- The paper introduces STaR, a method that bootstraps language model reasoning by iteratively generating and fine-tuning on intermediate rationales.
- It employs few-shot prompting and backward rationalization to enhance problem-solving in arithmetic, commonsense, and grade-school math tasks.
- Experimental results demonstrate up to 89.5% accuracy and performance improvements comparable to much larger models.
Bootstrapping Reasoning With STaR
The paper "STaR: Bootstrapping Reasoning With Reasoning" (2203.14465) explores a novel technique for improving the reasoning capabilities of LLMs (LMs) through iterative rationale generation and fine-tuning. The proposed method, named Self-Taught Reasoner (STaR), leverages a few initial examples to bootstrap the generation of complex reasoning tasks, mitigating the drawbacks of existing methods which either require massive datasets or result in reduced accuracy due to limited inferential examples.
STaR Methodology
Rationale Generation and Fine-Tuning
STaR's core mechanism involves generating intermediate rationales for a series of questions, fine-tuning the model only on those rationales that lead to correct answers, and iterating this cycle to enhance reasoning capabilities. The process initiates with a few-shot prompting setup, using a small number of rationale-labeled data instances to guide the LM in generating reasoned responses for a larger dataset without rationales.
The loop of rationale generation and filtering builds a dataset incrementally. The inclusion of only those rationales that produce correct responses ensures the dataset's quality, allowing the model to self-improve by learning from its generated reasoning structures.
Rationalization for Enhanced Learning
To address the limitation encountered when the model fails to solve new problems, the paper introduces the concept of rationalization. This involves providing the model with correct answers to unsolved problems, prompting it to generate 'backward' rationales, and subsequently fine-tuning on these generated sequences. This backward reasoning aids in exposing the model to challenging problems and expanding its capability by simulating a reasoning heuristic.
Experimental Evaluation
The effectiveness of STaR is demonstrated in the domains of arithmetic, commonsense reasoning (CommonsenseQA), and grade-school-level math (GSM8K). In arithmetic tests, the model achieves an accuracy of 89.5% on multi-digit addition problems after numerous iterations, showing a notable improvement over baseline models trained without rationales. For CommonsenseQA, STaR outperforms fine-tuned LMs by generating higher-quality rationales, achieving performance close to models that are significantly larger in scale.
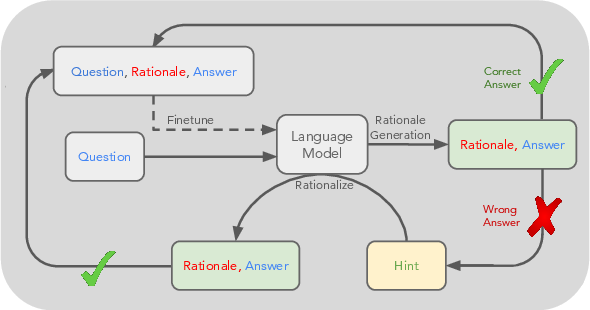
Figure 1: An overview of STaR and a STaR-generated rationale on CommonsenseQA.
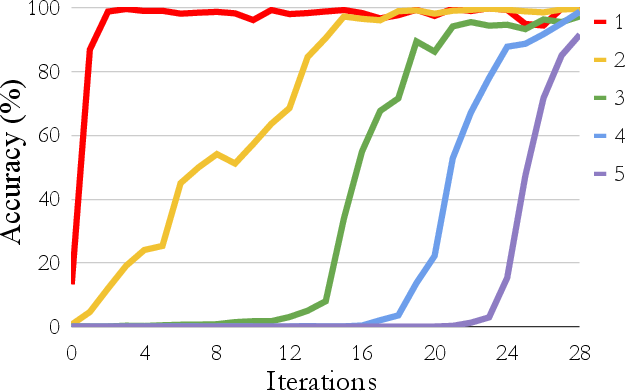
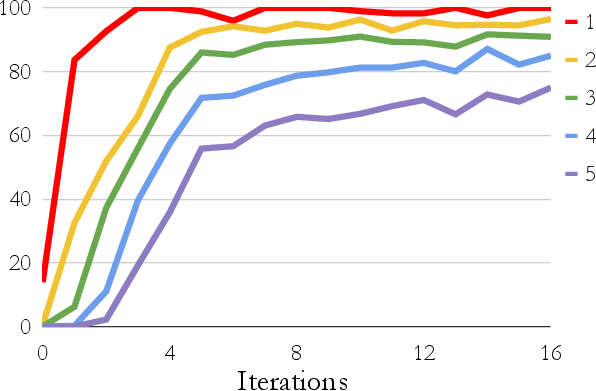
Figure 2: Without rationalization

Figure 3: An example problem in the training set where STaR derives a significantly simpler solution than the ground truth.
The experiments also highlight the added value of rationalization, which facilitates significant improvements across different iteration cycles. The capability of STaR to enhance reasoning in LMs without large-scale data makes it a promising approach for scalable application.
Discussion and Challenges
The integration of rationalization within STaR highlights the potential of utilizing backward reasoning techniques, allowing models to improve by justifying known outcomes. However, challenges remain, particularly concerning the balance between rationale quality and the exploration of novel reasoning paths, especially in datasets with high chance accuracy scenarios, such as binary decision-making.
Additionally, STaR's efficacy is linked to the initial reasoning capacity of the underlying LM, which must have a baseline competence above random chance. This implies that while the technique demonstrates significant potential, its application may require sufficiently capable initial models.
Conclusion
STaR's iterative rationale generation and fine-tuning framework exemplifies an innovative method for refining reasoning in LMs using limited examples. By leveraging both generated and rationalized reasoning, the methodology addresses key constraints in existing rationale generation frameworks. The approach shows promise in enhancing model generalization across diverse reasoning tasks, laying groundwork for further examination of its deployment in expansive and varied reasoning domains.
In summary, STaR provides a pathway for models to bootstrap their reasoning skills effectively, showing significant performance improvement on both symbolic and natural language reasoning tasks. However, further exploration is needed to address its limitations and to extend its applicability across broader contexts and more diverse model architectures.