- The paper introduces a novel automatic video dubbing system that synthesizes speech synchronized with video lip movements based on provided scripts.
- The methodology employs a Text-Video Aligner and an Image-based Speaker Embedding module to control speech prosody and timbre from visual cues.
- Experimental results on single and multi-speaker datasets demonstrate superior synchronization and audio quality, rivaling benchmarks like FastSpeech 2.
Neural Dubber: Dubbing for Videos According to Scripts
The paper "Neural Dubber: Dubbing for Videos According to Scripts" (2110.08243) introduces a novel approach for automatic video dubbing (AVD), termed Neural Dubber, which synthesizes speech synchronized with video based on provided text scripts. This is achieved by creating a multi-modal text-to-speech model that integrates video lip movements to control prosody. This manuscript outlines the technical implementation and validates its efficiency and alignment with state-of-the-art TTS systems through comprehensive experimentation.
Introduction to Automatic Video Dubbing
AVD is a complex task consisting of synchronizing synthesized speech with the lip movements visible in a video. The traditional process requires professional voice actors for fine-tuned dubbing tasks like ADR (Automated Dialogue Replacement), in scenarios where lip movement (viseme) aligns with scripts (phoneme). Neural Dubber addresses this automatically, tackling two primary challenges: achieving temporal synchronization and maintaining content consistency with the text input.
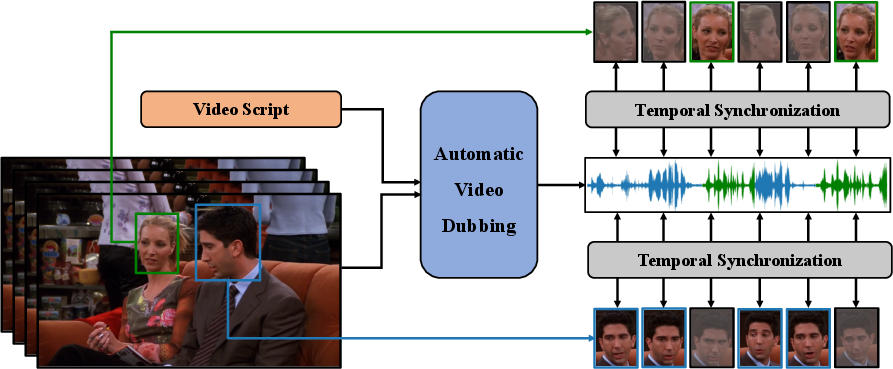
Figure 1: The schematic diagram of the automatic video dubbing (AVD) task. Given the video script and the video as input, the AVD task aims to synthesize speech that is temporally synchronized with the video.
Neural Dubber Architecture
The architecture of Neural Dubber involves two core modules: the Text-Video Aligner and the Image-based Speaker Embedding (ISE) module. The Text-Video Aligner utilizes an attention mechanism to ensure consistent alignment between video frames and phonemes. This module enables explicit control of speech prosody by using video content to inform the timing and rhythm of generated speech.
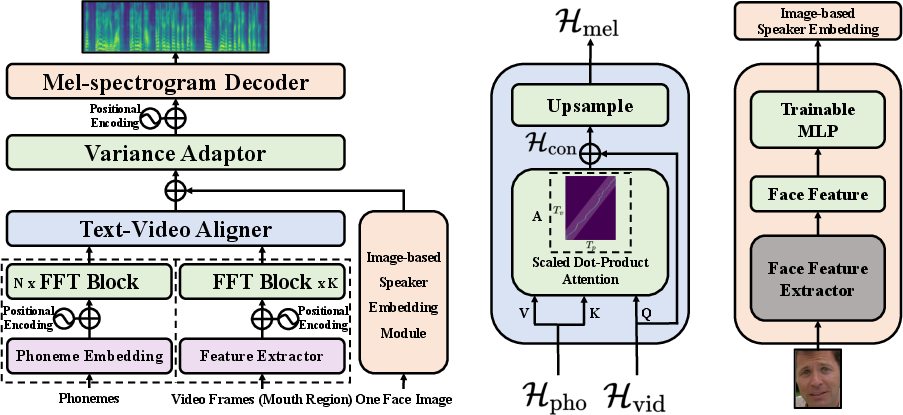
Figure 2: Neural Dubber.
ISE leverages face images to generate embeddings that influence the timbre of the synthesized speech, reflecting the speaker’s characteristics perceived from their facial features. This facilitates a personalized and realistic dubbing process, particularly beneficial in multi-speaker environments.
Experimental Results
The performance of Neural Dubber was assessed on both single and multi-speaker datasets. For the single-speaker scenario, the model was evaluated on a chemistry lecture dataset, demonstrating its capability to produce high-fidelity, synchronized speech. In the multi-speaker setting, the LRS2 dataset was used, verifying Neural Dubber's adaptability to diverse speaker profiles and synchronization needs.
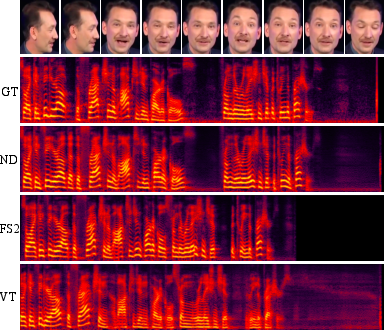

Figure 3: Mel-spectrograms of audios synthesized by some systems: Ground Truth (GT), Neural Dubber (ND), FastSpeech 2 (FS2) and Video-based Tacotron (VT).
Quantitative metrics such as LSE-D and LSE-C quantitatively confirmed superior av sync results. Qualitative evaluations showed Neural Dubber's superiority in maintaining audio quality and synchronization, positioning it on par with or exceeding the FastSpeech 2 benchmark, particularly due to ISE’s contributions in timbre adjustment.
Conclusion
Neural Dubber marks a significant advance in the field of automatic dubbing, successfully integrating video-driven prosody control within a multi-modal TTS framework. Its architecture promises considerable improvements in the synthesis of synchronized and natural language speech. Future work may extend its capabilities for broader language contexts and contribute to refining face-image-driven timbre modulation for even more nuanced dubbing outputs. Overall, Neural Dubber opens new pathways in automatic synthesis methodologies with potent implications for the media and entertainment industries.
