- The paper introduces xGQA, a benchmark that extends the GQA dataset into seven typologically diverse languages for cross-lingual VQA evaluation.
- The paper employs two adapter-based methodologies to adapt monolingual and multilingual transformers for enhanced multimodal alignment.
- The paper demonstrates significant performance gains in few-shot settings, highlighting the benefit of leveraging modest target-language data for improved accuracy.
"xGQA: Cross-Lingual Visual Question Answering"
Introduction
The paper introduces xGQA, a benchmark designed to extend the capabilities of visual question answering (VQA) systems into multilingual contexts. Addressing a prevalent gap in existing research, which predominantly focuses on English, xGQA is developed by expanding the established GQA dataset into seven typologically diverse languages. This work lays the groundwork for investigating the challenges inherent in cross-lingual VQA and proposes adapter-based techniques to enhance multilingual and multimodal model alignment.
Dataset Construction
The xGQA dataset is derived from the English GQA dataset, leveraging its structure by translating the balanced test-dev set into seven languages, as shown in (Figure 1). This expansion covers languages such as German, Portuguese, Russian, Indonesian, Bengali, Korean, and Chinese, accommodating various language families and scripts. The questions in xGQA maintain simplicity, averaging 8.5 words per question. This dataset is positioned as the first genuinely typologically diverse evaluation benchmark for VQA.

Figure 1: Example taken from the xGQA dataset with the same question uttered in 8 languages.
Approach and Architecture
The paper investigates a two-pronged adapter-based methodology. First, it adapts monolingual transformers such as OSCAR+, a multimodal model, to multilingual domains. Second, it extends multilingual models, specifically mBERT, to encapsulate multimodal capabilities. Both approaches exploit the modular architecture of transformers, incorporating language adapters and novel multimodal aligners to enhance cross-lingual multimodal transfer potential.
The architecture integrates modality-specific task adapters, which are concatenated after processing inputs through pre-trained layers shared across text and image modalities (Figure 2). This design aims to mitigate alignment issues between multilingual and multimodal spaces observed in prior models like M3P.
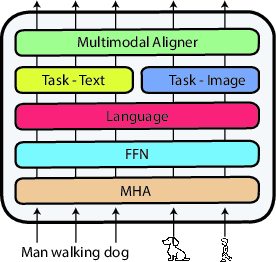
Figure 2: Architecture of an adapter-based multilingual multimodal model. Text and image inputs share the weights of the multi-head attention (MHA) and feed-forward (FFN) layers, as well as the language and multimodal align adapters.
Experimental Results
In the zero-shot cross-lingual transfer setting, adapter-based models demonstrated superior results compared to existing methods, particularly the M3P model. Notably, an average accuracy drop of 38 points was observed across all target languages, underlining the difficulty of this task. The proposed adapter-based extension of mBERT outperformed M3P, suggesting the importance of preserving cross-lingual congruence during fine-tuning.
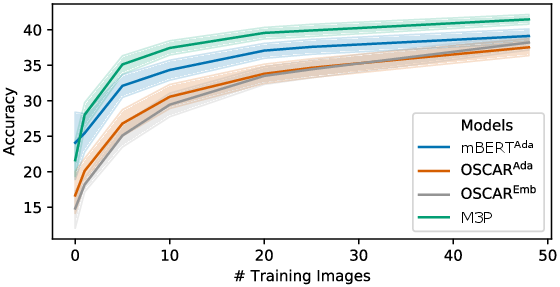
Figure 3: Few-shot accuracy with different training dataset sizes of the different approaches, showing scores averaged over all languages.
The few-shot experimental setup illustrated considerable gains when modestly increasing training dataset sizes, demonstrating improvements across all language targets. This suggests that leveraging a small quantity of target-language data can significantly bolster model performance, effectively enhancing multimodal and cross-lingual alignment.
Analysis and Discussion
Initial analysis revealed significant performance disparities across structural question types (Figure 4). Choose-type questions exhibited notably high accuracy drops, indicating alignment failures at the linguistic level. Conversely, query-type questions, characterized by free-form semantics, presented consistent interpretive challenges due to their complexity.
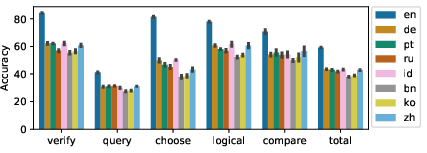
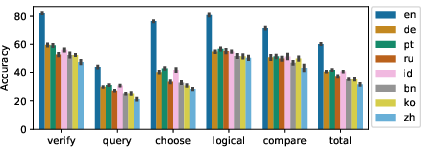
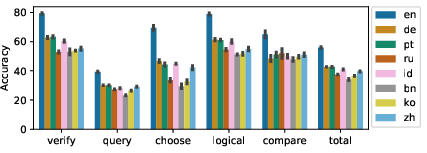
Figure 4: Zero-shot accuracy across different languages and structural question types from xGQA.
Language transfer analysis highlighted predictable accuracy variances favoring languages typologically closer to English, such as German and Portuguese, as opposed to those markedly different like Bengali and Korean. This trend underscores the necessity of typologically inclusive datasets to facilitate robust model training and transfer evaluation.
Conclusion
The introduction of xGQA marks a pivotal advancement in the field of multilingual multimodal research. While significant cross-lingual performance hurdles persist, the proposed adapter-based methodologies offer promising avenues for enhancing alignment of multilingual and multimodal systems. Future investigations are inspired by this benchmark, focusing on sophisticated pre-training techniques that better capture the intricate dance between language and visual modalities across diverse linguistic landscapes.