- The paper demonstrates that self-supervised learning on random, uncurated images can achieve 84.2% top-1 accuracy on ImageNet.
- It employs the SwAV approach with high-capacity RegNetY architectures, delivering robust performance in low-shot and transfer learning scenarios.
- Ablation studies reveal that scalable model capacity and optimized training strategies are key to effective self-supervised feature learning.
Self-supervised Pretraining of Visual Features in the Wild
"Self-supervised Pretraining of Visual Features in the Wild" (2103.01988) investigates the efficacy of self-supervised learning (SSL) when applied to large, uncurated datasets of images, aiming to challenge the traditional reliance on supervised learning using curated datasets like ImageNet. The paper leverages the SwAV SSL approach alongside high-capacity RegNet architectures to explore whether self-supervised methods can achieve state-of-the-art performance by pretraining on random Internet images.
Introduction
The paper begins by setting the context for SSL as a promising frontier in model pretraining, citing the reduction in the performance gap when compared to supervised methods. Traditionally, SSL outcomes have been tested in controlled environments using highly curated datasets such as ImageNet. However, SSL theoretically offers the capability to learn from any random image dataset. This motivates the research question: can SSL fulfill its potential in an uncontrolled, real-world setting?
To explore this, the paper presents SEER (SElf-supERvised) models, notably based on the RegNetY architecture with 1.3 billion parameters, trained using 512 GPUs on 1 billion random images, achieving an 84.2% top-1 accuracy surpassing existing models. Additionally, the paper highlights the few-shot learning capability of these SSL models, obtaining 77.9% top-1 accuracy with only 10% of ImageNet data, illustrating robust performance in resource-constrained scenarios.
Methodology
The paper employs the SwAV SSL method, focusing on clustering for feature extraction, characterizing it by computing cluster assignments across augmented views of images and enforcing consistency between them. This approach facilitates learning semantic representations invariant to data augmentations.
RegNet Architecture
RegNet, chosen for its scalable efficiency, forms the backbone of the study's experiments. It optimizes memory usage and runtime, leveraging a parametrized architecture that balances efficiency with increasing model capacity. Specifically, RegNetY models are augmented with Squeeze-and-excitation mechanisms to further improve performance.
Training and Optimization Techniques
Critical to handling the large scale of data and model complexity were strategies like mixed-precision training, gradient checkpointing, and optimized data loaders for efficient memory and computational usage. The training employed unsupervised data from Instagram without pre-processing or curation, adhering to a distributed, scalable training approach optimized through an evolving learning rate strategy.
Results
The paper's experiments demonstrate the prowess of SSL in varied settings:
Finetuning and Transfer Learning
SEER models pretraining showcases superior finetuned outcomes on ImageNet compared to prior SSL and semi-supervised pretrained models, highlighting SSL's ability to generalize from uncurated datasets. Performance gains were consistent across increasing model capacities, reaching up to 84.2% top-1 accuracy.
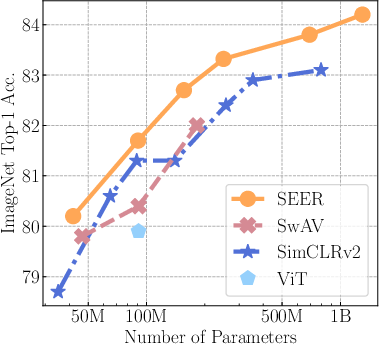
Figure 1: Performance of large pretrained models on ImageNet. We pretrain our SEER models on uncurated and random images.
Low-shot Learning
The impact of SSL is further validated in low-shot learning scenarios, where SEER outperformed several semi-supervised methods despite limited data access during training—a gap minimized even when SEER only utilized 1% of ImageNet data.
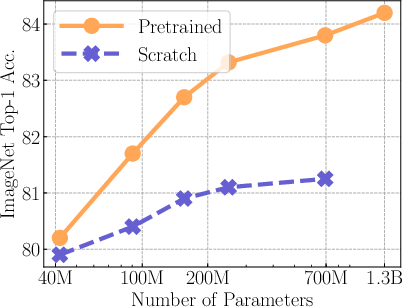
Figure 2: Finetuning pretrained RegNets on ImageNet versus Scratch.
Across Multiple Benchmarks
Investigating transferability, SEER models showed superior performance on tasks such as iNaturalist classification and COCO detection, indicating the features learned conveyed rich semantic understanding applicable across diverse tasks.
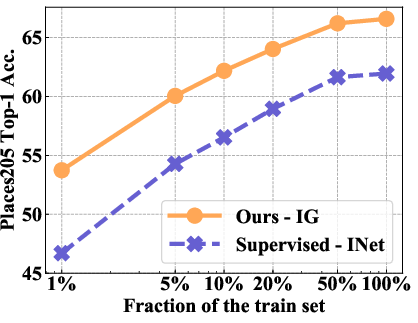
Figure 3: Low-shot learning on Places.
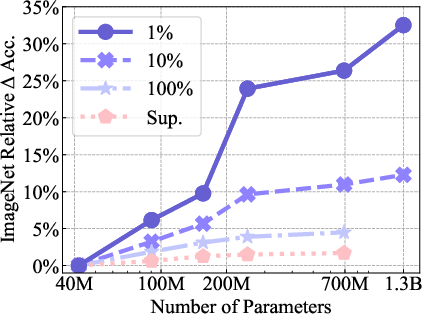
Figure 4: Impact of capacity on low-shot learning.
Ablation Studies
The paper presents thorough ablation studies to dissect the impact of model capacity, architecture, and training data size. The scalability of training updates rather than the absolute data size demonstrated dominant performance enhancements. Additionally, the optimized self-supervised head size in SwAV significantly enhanced pretrained feature quality.
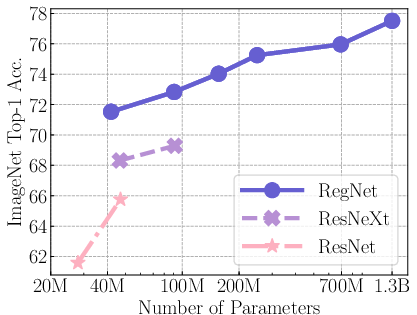
Figure 5: Comparison across architectures.
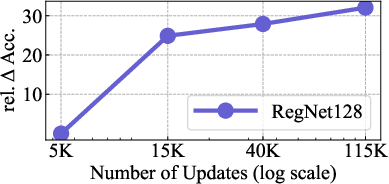
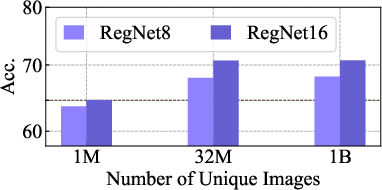
Figure 6: (left) Impact of number of updates; (right) Impact of number of unique images.
Conclusion
The research confirms that SSL trained on random, uncurated images can achieve competitive performances across tasks traditionally dominated by curated dataset-driven models. This work not only underscores the practical viability of SSL in real-world scenarios but also opens avenues for continuous learning systems capable of leveraging ever-evolving unlabeled data streams. Future developments could explore tailored RegNet architectures optimized directly for SSL tasks at scale.

