- The paper introduces SILCR that leverages an agent’s own experience to retroactively assign constant rewards, overcoming delayed reward challenges.
- It integrates Maximum Entropy Reinforcement Learning via the soft actor-critic method to enhance exploration in sparse reward settings.
- Empirical evaluations on MuJoCo tasks show SILCR’s rapid learning and enhanced policy stability compared to traditional SAC-based methods.
Self-Imitation Learning for Robot Tasks with Sparse and Delayed Rewards
Introduction
The paper introduces Self-Imitation Learning with Constant Reward (SILCR), a novel approach to tackle reinforcement learning (RL) challenges associated with sparse and delayed rewards in robotic control tasks. In traditional RL methods, the immediate reward functions critically influence learning efficiency and agent performance; however, real-world applications frequently suffer from sparse and episodic rewards, which hinder timely credit assignment across behaviors. SILCR proposes a unique self-supervised learning paradigm whereby constant rewards replace handcrafted immediate reward metrics, leveraging episodic reward evaluation to assign temporal credit retroactively.
Self-Imitation Learning Framework
The fundamental premise of SILCR is the utilization of past experiences to enhance RL agent policies without requiring immediate environmental rewards. Unlike typical imitation learning approaches necessitating expert demonstrations, SILCR derives its training signals from the agent's own interactions with the environment. This framework is visually illustrated, indicating how both favorable and unfavorable experiences collectively inform the robot's progression towards an optimal policy.
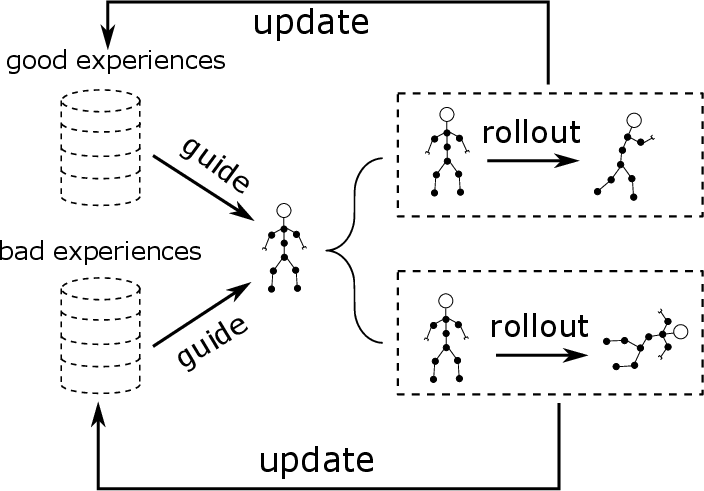
Figure 1: Our self-imitation learning framework for robot learning. The good (keep walking) and bad (fall down) experiences generated by the robot itself will further guide its subsequent behaviors.
The interaction-derived experience data thus generates a cycle of continuous improvement, eschewing the need for expert knowledge, and fostering exploration.
Maximum Entropy Reinforcement Learning
SILCR is anchored in Maximum Entropy Reinforcement Learning principles, deviating from traditional paradigms by integrating entropy within policy maximization to encourage stochastic action selection. The soft actor-critic (SAC) methodology exemplifies this, aiming to optimize both expected rewards and entropy:
π∗=argmaxπt∑∞E[rt+αH(π(⋅∣st))]
SILCR adopts SAC as its underlying framework, using episodic rewards for learning without immediate reward signals, thus accommodating environments where temporal credit assignment traditionally falters.
Training Strategy
The training strategy employs two buffers—DO and DE—to manage data from both entire episodes and selective high-performance trajectories. The introduction of constant reward values (0 or 1) simplifies dynamics and ensures consistent guidance for agent policy optimization.
The training process involves sampling data from these buffers proportionately to maintain sample diversity and balance during policy updates driven by the soft Q function and maximum entropy objectives, following SAC-based optimization routines.
Empirical Evaluation
The method is rigorously evaluated against established benchmarks in continuous control tasks within the MuJoCo simulation environment. These tasks range in complexity and dimensionality, providing a robust evaluation spectrum. When faced with sparse rewards, SILCR demonstrates a decisive advantage over SAC, exhibiting rapid learning and high episodic rewards.
(Figure 2 and Figure 3)
Figure 2: Five continuous robotics control tasks in MuJoCo simulation.
Figure 3: Learning curves on five MuJoCo continuous control benchmarks. The results of GASIL are intercepted from the original study.
Dense reward settings further validate SILCR’s competitive performance, matching or exceeding episodic reward levels achieved by SAC—despite the latter relying on immediate environmental reward feedback.
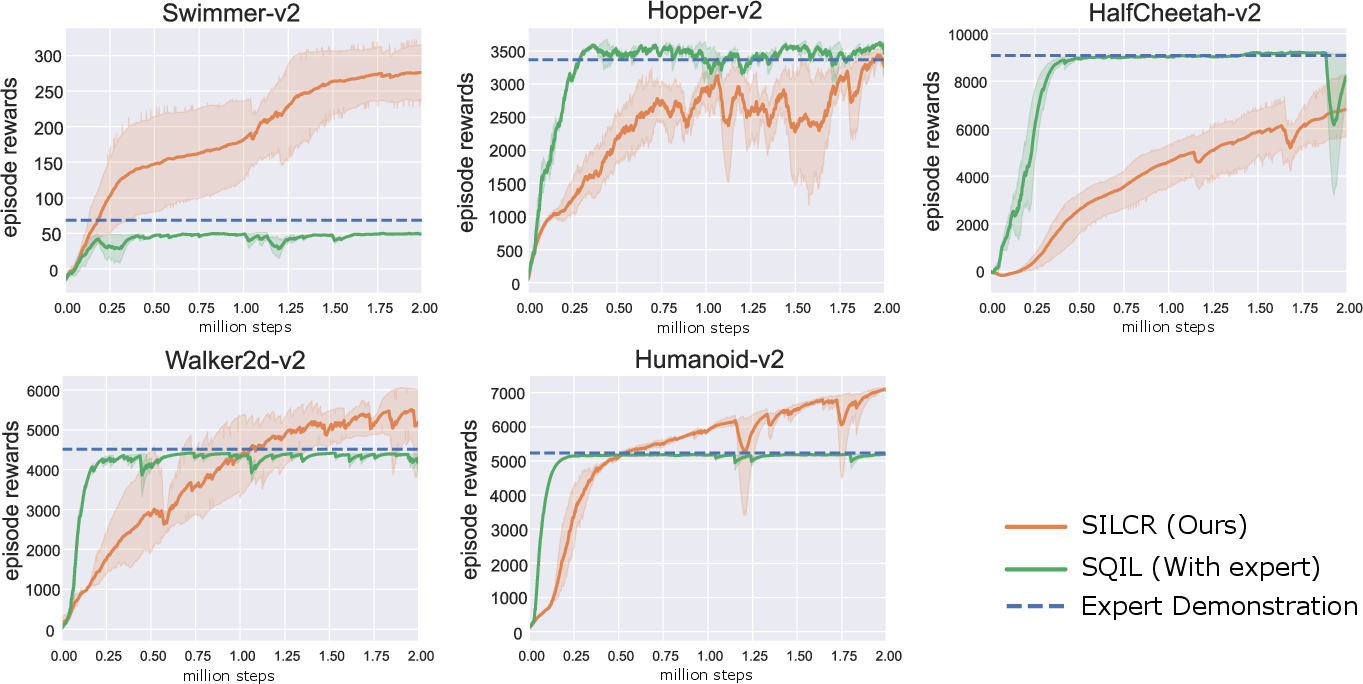
Figure 4: Comparison with imitation learning on five MuJoCo continuous control benchmarks. The expert is generated by a SAC agent trained in dense reward settings.
Hyperparameter Sensitivity
An ablation study concerning the expert buffer size (M) reveals critical insights into hyperparameter impact on learning outcomes. Buffer sizes significantly influence stability and performance, underscoring the trade-offs between experience depth and diversity.
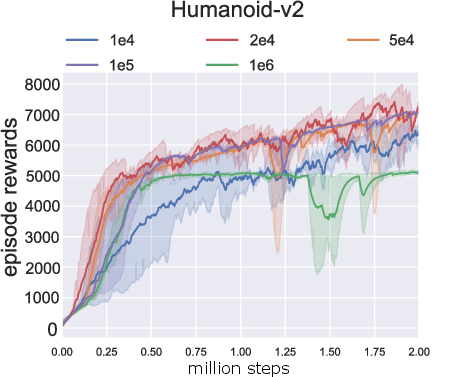
Figure 5: Ablation study over the size of expert replay buffer $\mathcal{M}.
Conclusion
SILCR offers a practical self-imitation approach to robotic learning challenges where rewards are sparse or delayed, effectively circumventing traditional RL limitations without sacrificing performance or stability. Future investigations may explore its application across alternative RL frameworks, particularly in discrete action environments, with potential integrations enhancing exploration and initial learning phases. This method demonstrates potential for widespread adoption within robotic control tasks, particularly those constrained by real-world reward sparsity.
The research addresses inherent limitations in standard RL and imitation learning paradigms, presenting implications for broadening autonomous robotic capabilities and enabling more nuanced, efficient policy development in challenging reward landscapes.