- The paper proposes a non-parametric, case-based reasoning approach that dynamically retrieves paths from similar entities to complete evolving knowledge graphs.
- It leverages probabilistic weighting to assess path frequency and precision, achieving competitive performance on benchmark datasets.
- The model employs hierarchical clustering and efficient online updates, eliminating the need for extensive retraining in open-world settings.
Probabilistic Case-based Reasoning for Open-World Knowledge Graph Completion
The paper "Probabilistic Case-based Reasoning for Open-World Knowledge Graph Completion" (2010.03548) introduces a non-parametric model leveraging case-based reasoning (CBR) for Knowledge Graph (KG) completion, particularly focused on handling evolving KGs where new entities and relations continuously emerge. The model dynamically gathers paths from similar entities in the KG to answer queries, emphasizing the importance of probabilistic weighting to improve precision and adaptability in open-world settings.
Model Overview and Methodology
Case-based Reasoning Approach
The proposed approach applies a k-nearest neighbor (KNN)-like mechanism, akin to CBR systems in classical AI, to accommodate dynamic and open-world KGs. Given a query, the model retrieves similar entities and identifies reasoning paths between these entities and the target relations. This process involves two key probabilistic estimations: the path's prior (frequency) and its precision (likelihood to correctly resolve a query).
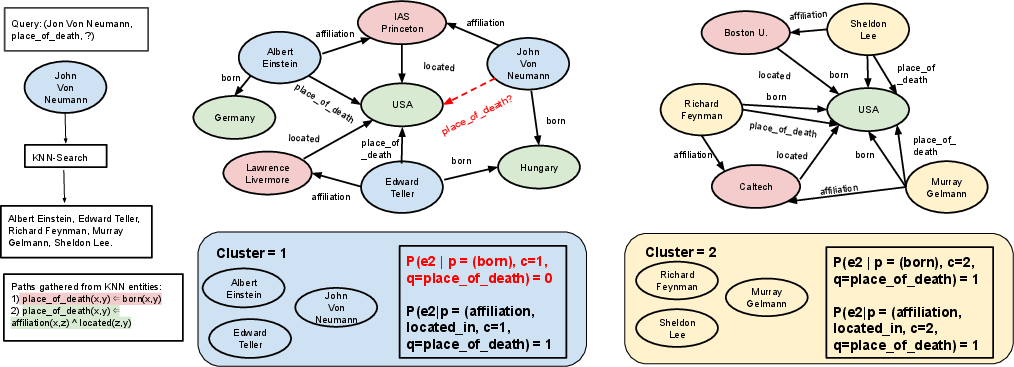
Figure 1: Given the query, (Jon Von Neumann,~place_of_death,~?), the model gathers reasoning paths from similar entities, emphasizing the importance of learning path weights for clusters of similar entities.
Non-parametric Learning
The model is non-parametric, meaning it grows in complexity as the KG expands, without needing extensive retraining. The parameters are derived from path statistics within clusters of similar entities, enabling scalability and efficiency. The clusters are formed using hierarchical agglomerative clustering, with parameter estimates computed through simple count statistics rather than iterative optimization.

Figure 2: Illustration of the non-parametric model's ability to handle newly added entities and infer new facts without requiring expensive training.
Implementation Details
Path Statistics and Clustering
For accurate path relevance estimation, entities are clustered, and path statistics are computed for each cluster. This clustering helps mitigate parameter explosion and noise due to sparsity. This method efficiently integrates with an online setting, leveraging Grinch – an online hierarchical clustering algorithm – to adapt the clustering dynamically as data evolves.
Handling Open-world Dynamics
The model effectively manages open-world scenarios by:
- Dynamically updating entity representations using sparse vectors of edge types.
- Applying fast and efficient parameter updates only for affected entities using path length cycles.
Experimental Results
Knowledge Base Completion
The model demonstrates competitive performance on traditional KBC tasks, significantly outperforming other rule-based and embedding-based models on several benchmark datasets like NELL-995, FB122, and WN18RR. Specifically, the model achieves superior results on tasks involving logical rule application, highlighting its path weighting efficacy.
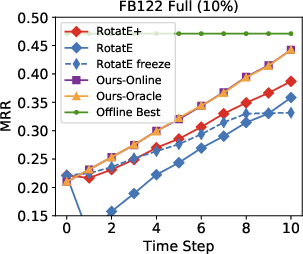
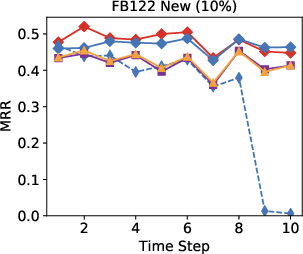
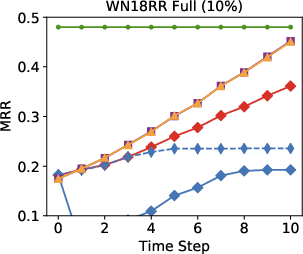
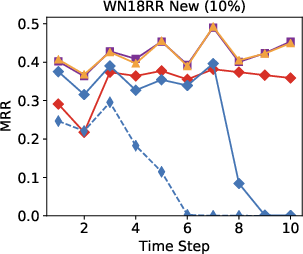
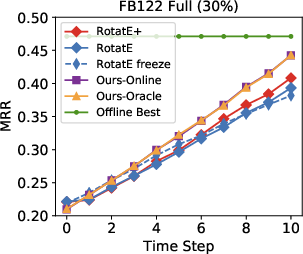
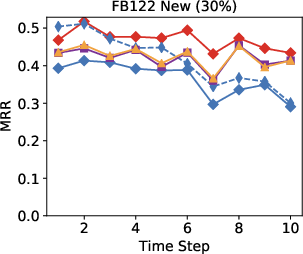
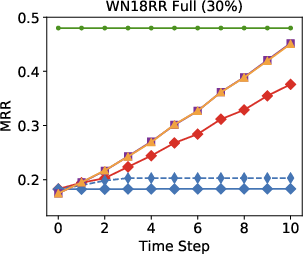
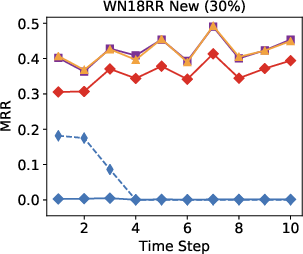
Figure 3: Performance results indicate the model surpasses other approaches in an open-world setting using 10-30% of seen edges.
Open-world Settings
Remarkably, in streaming data conditions, the model efficiently bridges the performance gap with the best offline methods, substantially outperforming parametric models such as RotatE, which struggle with model forgetting issues as new data is added.

Figure 4: Number of entities added to KB in each batch and number of entities modified in each update, showcasing the model's efficiency in incremental updates.
Conclusion
The presented approach represents a simple yet effective method for KG completion, aligning with open-world requirements by dynamically learning from nearest entities and efficiently updating parameters. The model's significant advantage lies in its ability to deliver close to state-of-the-art performance without relying on extensive retraining, positioning it as a viable solution for handling ever-evolving KGs. Future research could refine the clustering process or expand on path types to further boost performance in more diverse KG scenarios.