- The paper introduces Tsunami, a learned index that leverages Grid Trees and Augmented Grids to efficiently address query skew and data correlations.
- It demonstrates up to 6× faster query speeds and 11× improvement over traditional and state-of-the-art indexes in various datasets.
- Its adaptive design scales with higher dimensions and dynamic workloads while significantly reducing memory usage.
Introduction
"Tsunami: A Learned Multi-dimensional Index for Correlated Data and Skewed Workloads" (2006.13282) presents a novel approach to enhance query performance in analytical database systems. The authors address limitations of traditional multi-dimensional indexing techniques such as k-d trees and R-trees, particularly in handling skewed workloads and correlated data. Recent advancements have introduced learned indexes that optimize index structures for specific datasets and query workloads. However, existing solutions struggle with query skew and data correlations. This paper proposes Tsunami, a new in-memory learned multi-dimensional index that substantially improves upon its predecessors in terms of query speed and index size efficiency.
The Tsunami Design
Addressing Query Skew
Tsunami utilizes a Grid Tree to mitigate query skew. This decision tree partitions the data space into regions with low skew, enabling optimized query performance across varied workloads.
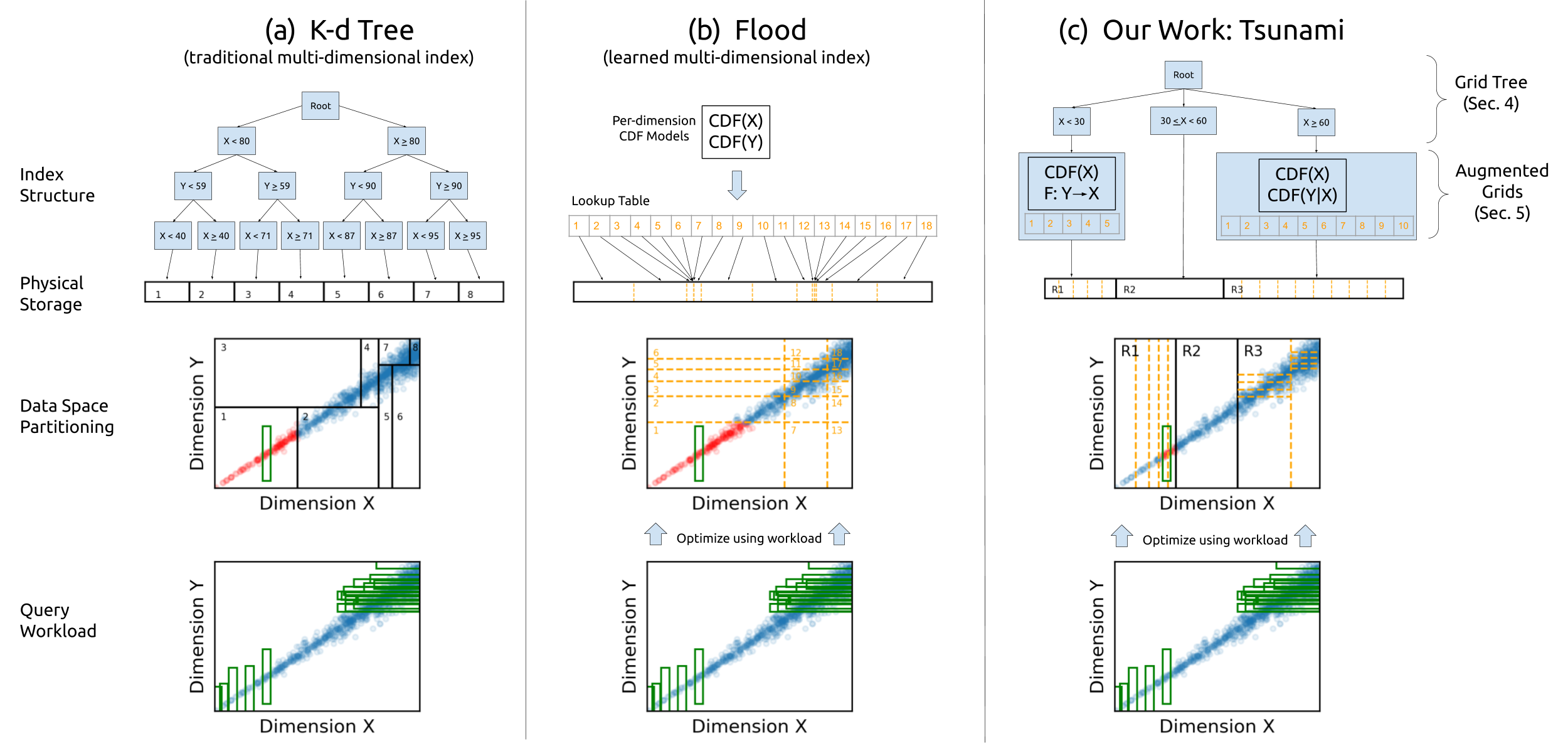
Figure 1: Indexes must identify the points that fall in the green query rectangle. Tsunami is optimized using the workload, is adaptive to query skew, and maintains equally-sized cells within each region.
A query workload is skewed when queries vary significantly in frequency or selectivity across the data space. Tsunami exploits this by assigning more partitions to frequently accessed regions, maintaining high performance even when workloads exhibit significant skew.
Tackling Data Correlations
The Augmented Grid within Tsunami handles data correlations by employing techniques such as functional mappings and conditional cumulative distribution functions (CCDFs). Functional mappings efficiently address monotonic correlations, whereas CCDFs handle generic correlations by partitioning dimensions dependently, resulting in equally-sized grid cells.
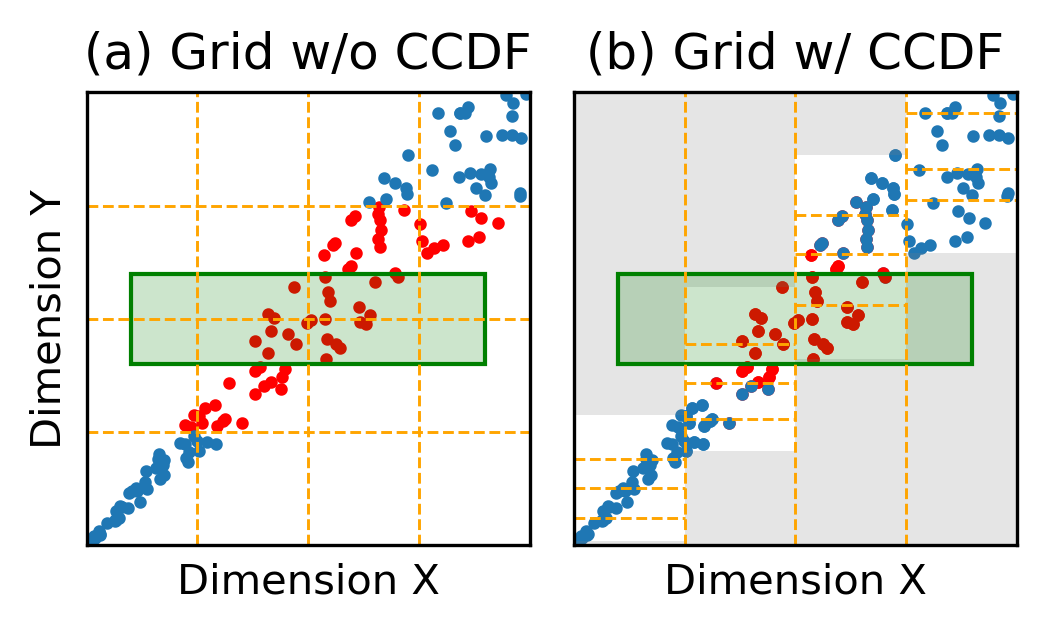
Figure 2: Conditional CDFs create equally-sized cells and reduce scanned points for generic correlations.
By doing so, Tsunami ensures that queries involving correlated dimensions are processed swiftly, avoiding the pitfalls of traditional independent partitioning.
Experimental Evaluation
The authors conduct extensive evaluations on datasets including TPC-H, NYC Taxi, performance monitoring logs, and historical stock prices. Tsunami consistently outperforms competing indexes, achieving up to 6 times faster queries than Flood (a state-of-the-art learned index) and up to 11 times faster than traditional non-learned indexes.
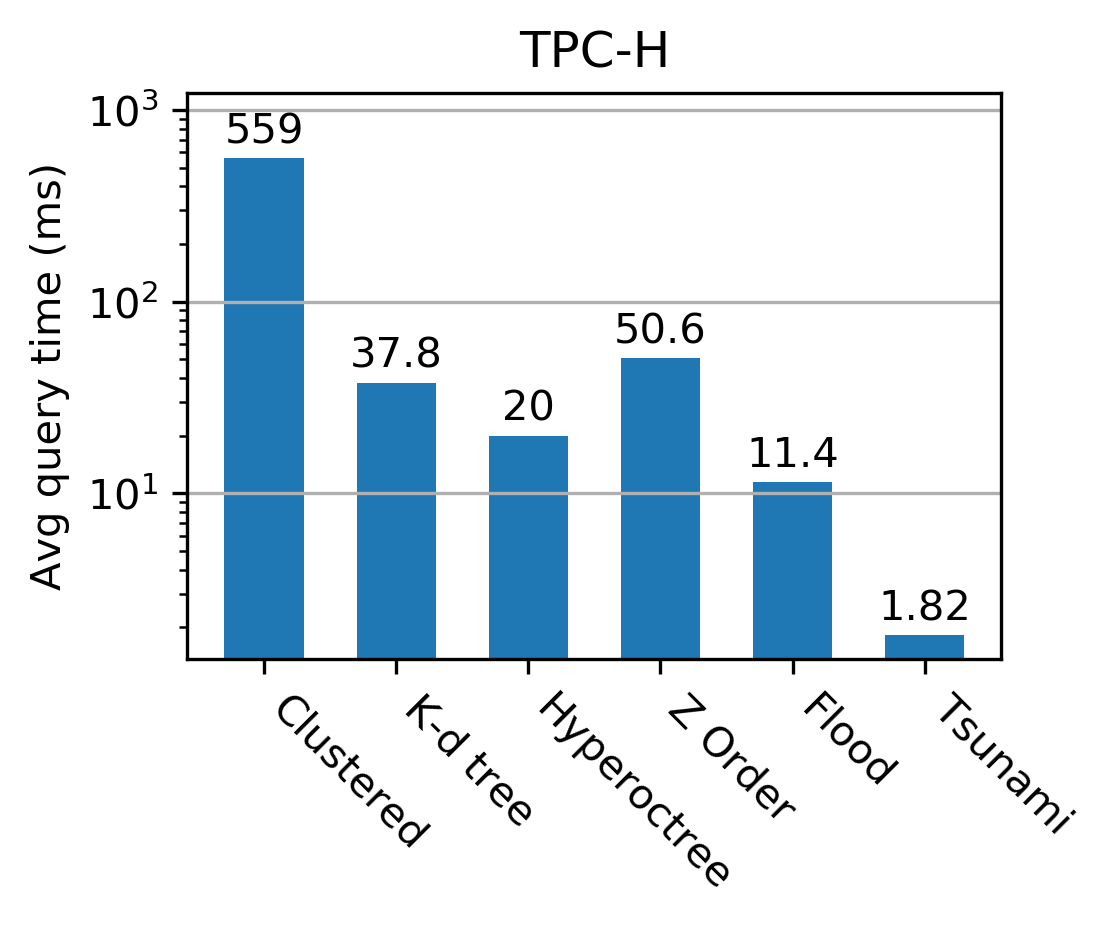
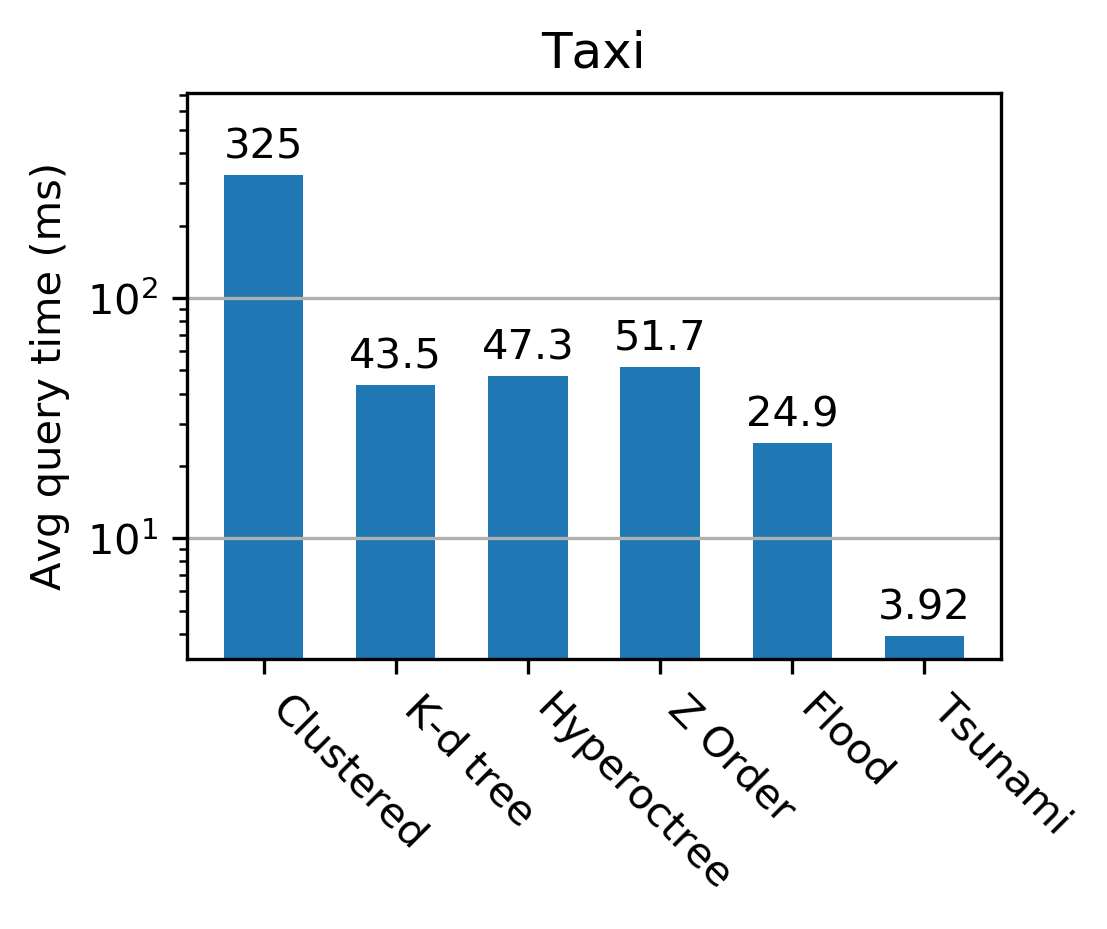
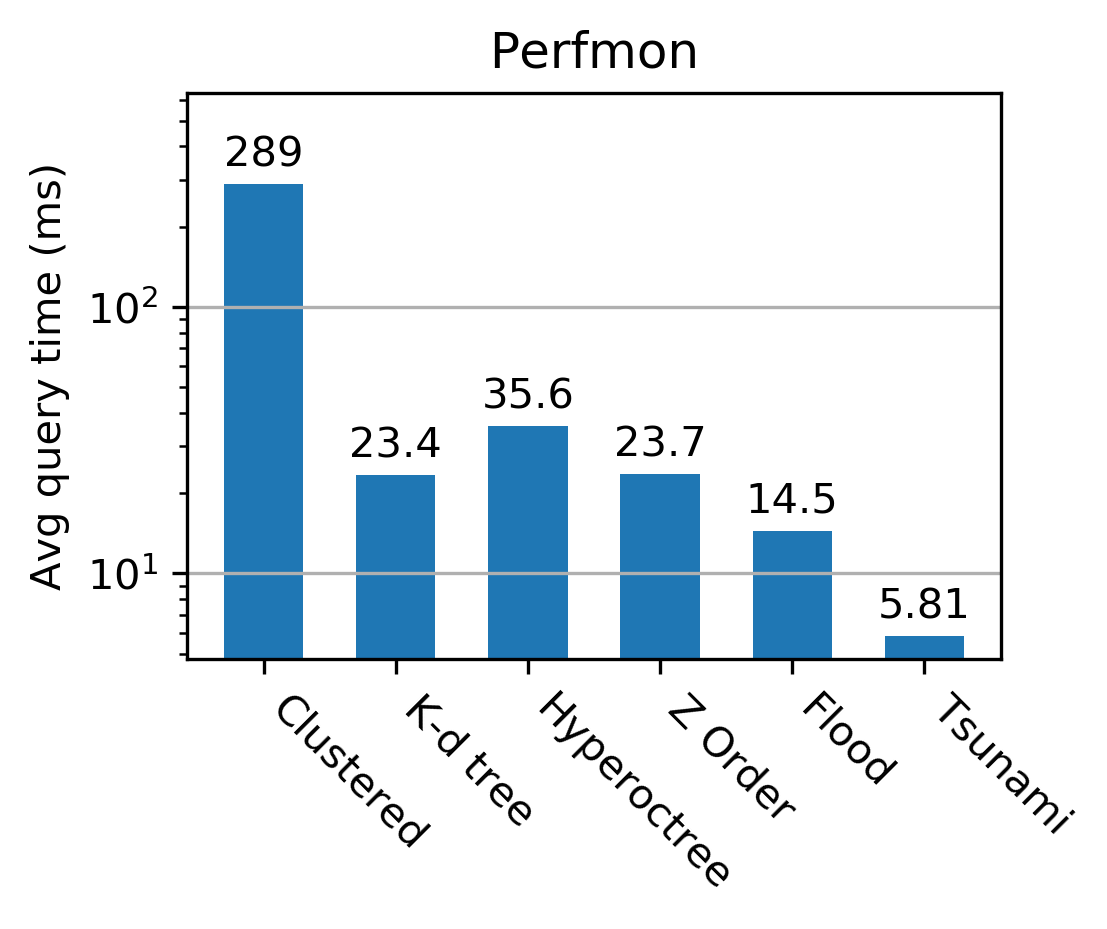
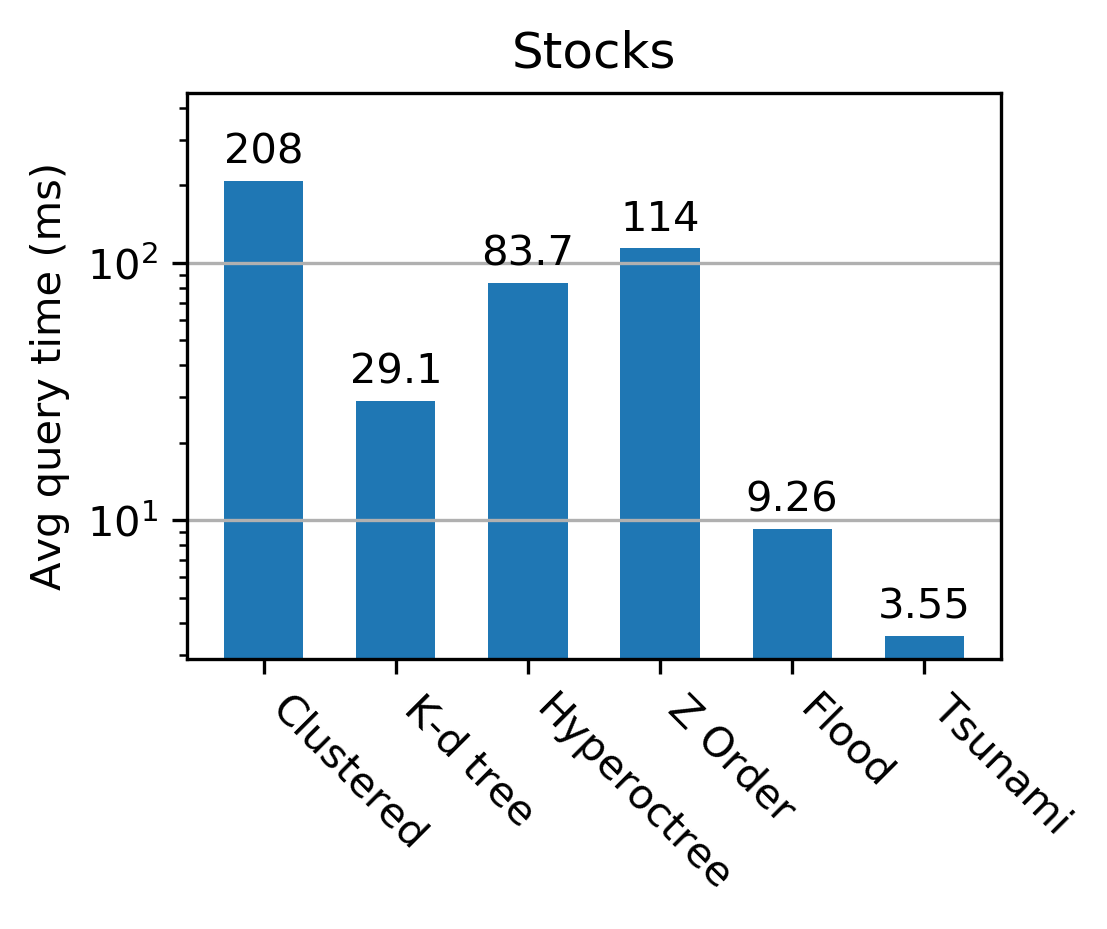
Figure 3: Tsunami achieves up to 6 times faster queries than Flood and up to 11 times faster queries than the fastest non-learned index.

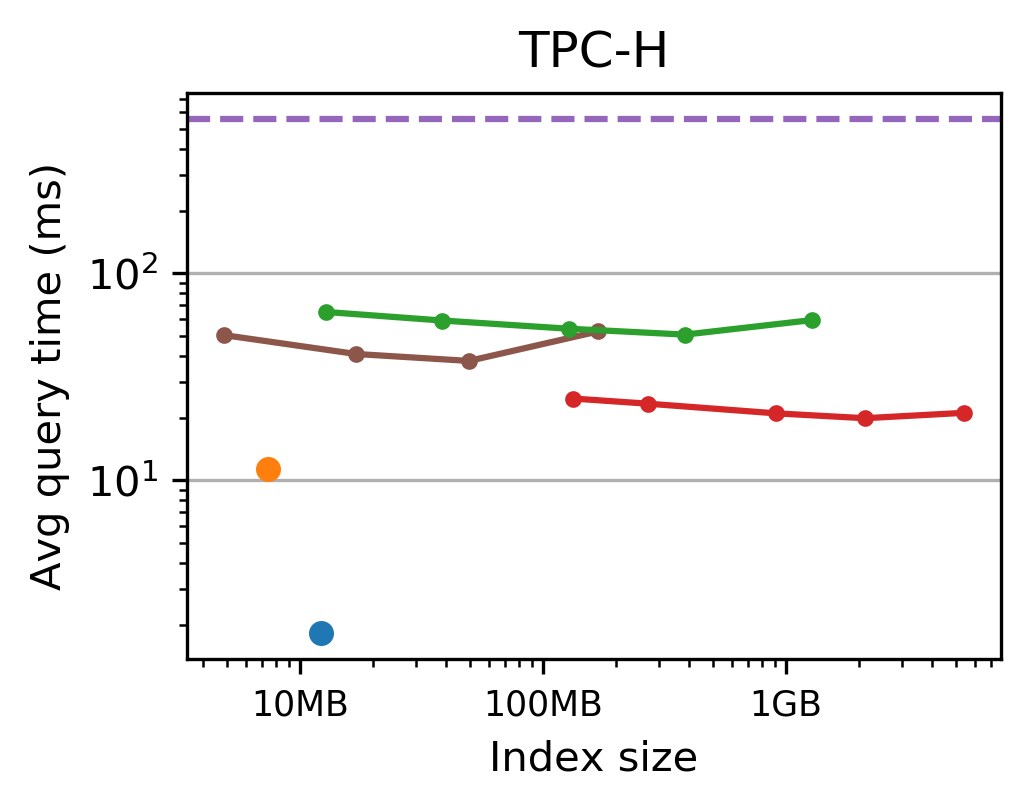
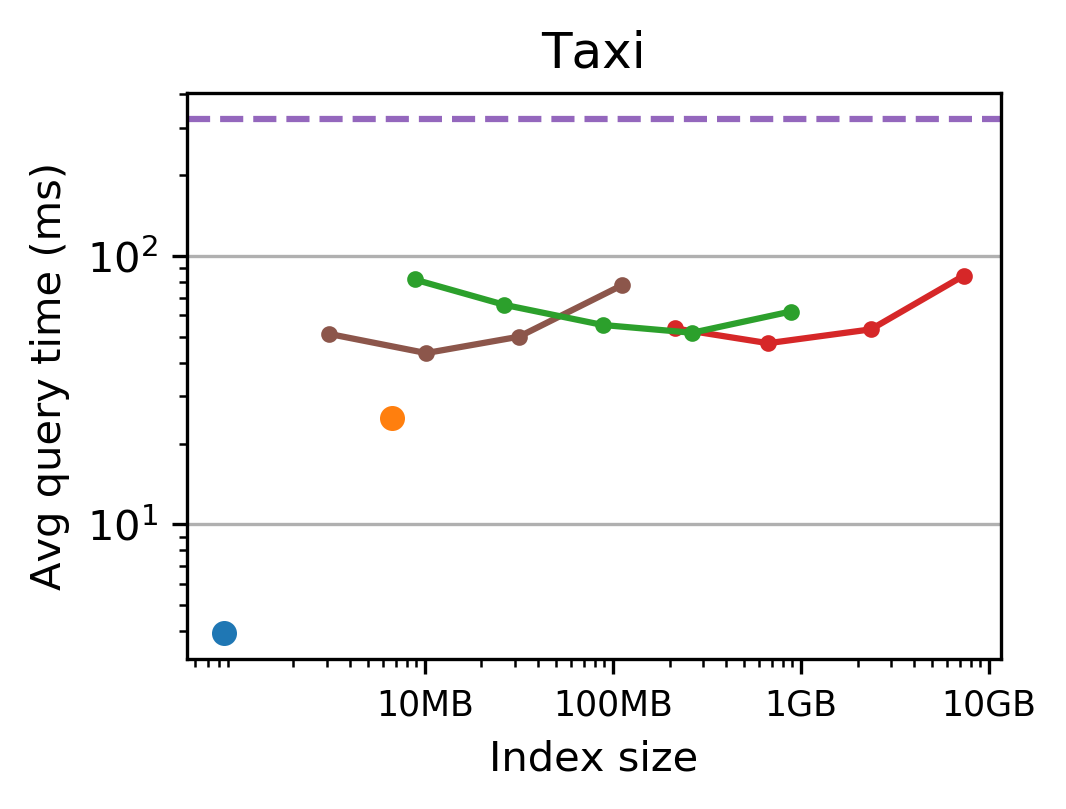
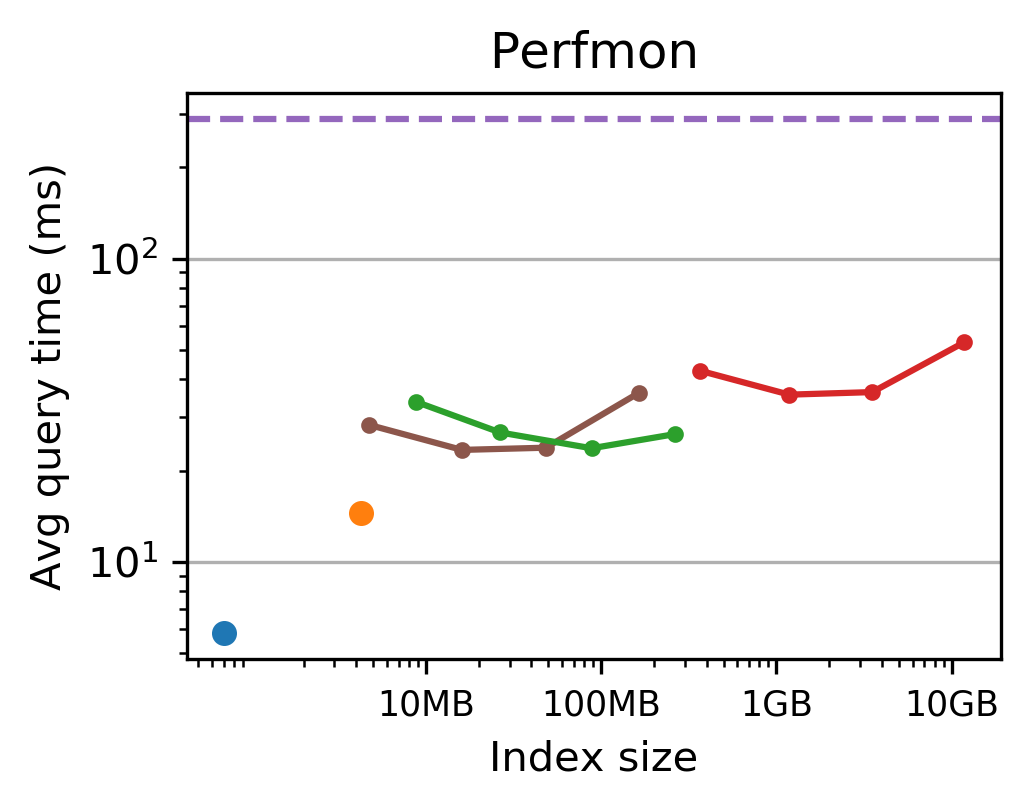
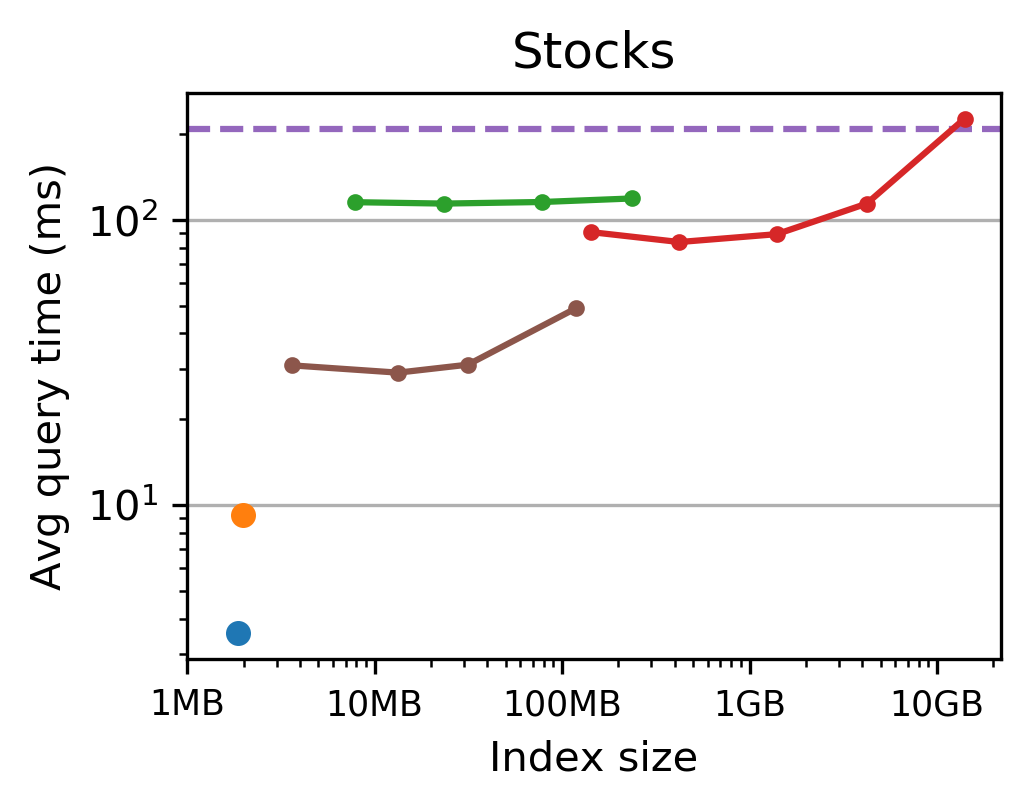
Figure 4: Tsunami uses up to 8 times less memory than Flood and 7-170 times less memory than the fastest tuned non-learned index.
These results highlight Tsunami's robustness and efficiency, largely attributed to its adaptive structures that tailor to specific data distributions and query patterns.
Scalability and Adaptability
Tsunami also demonstrates remarkable scalability with increasing dimensionality, dataset size, and varying query selectivities. This flexibility is crucial for modern analytical tasks that often involve complex multi-dimensional data.
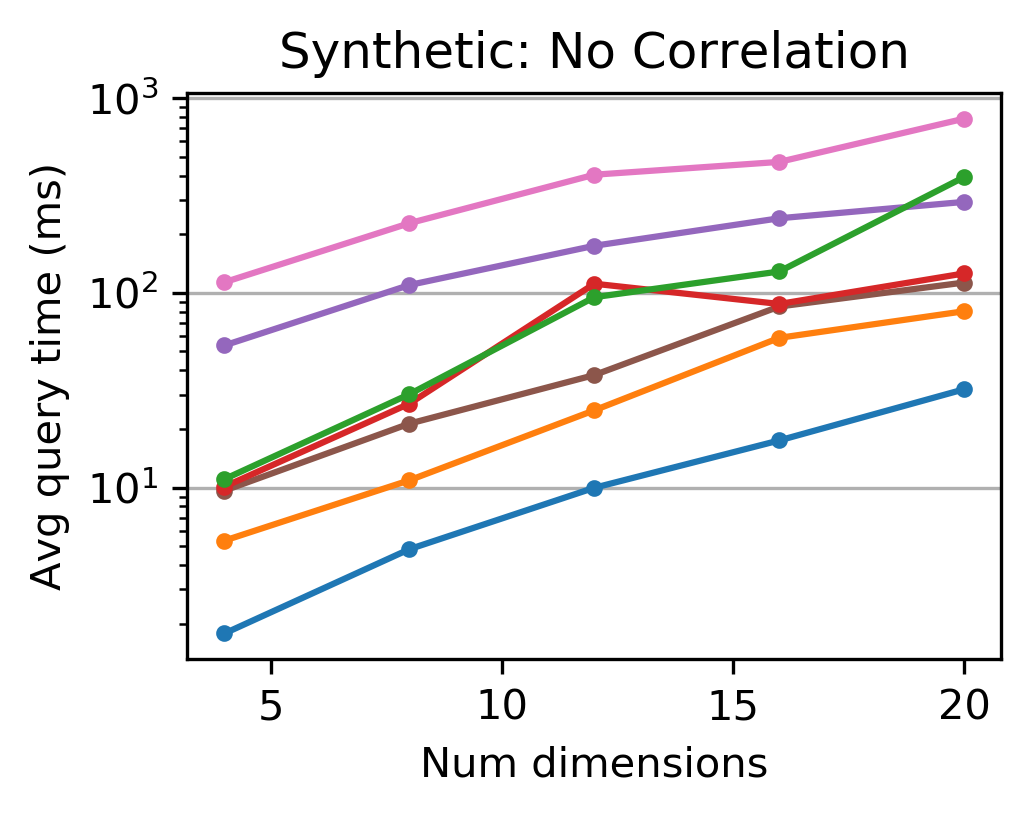
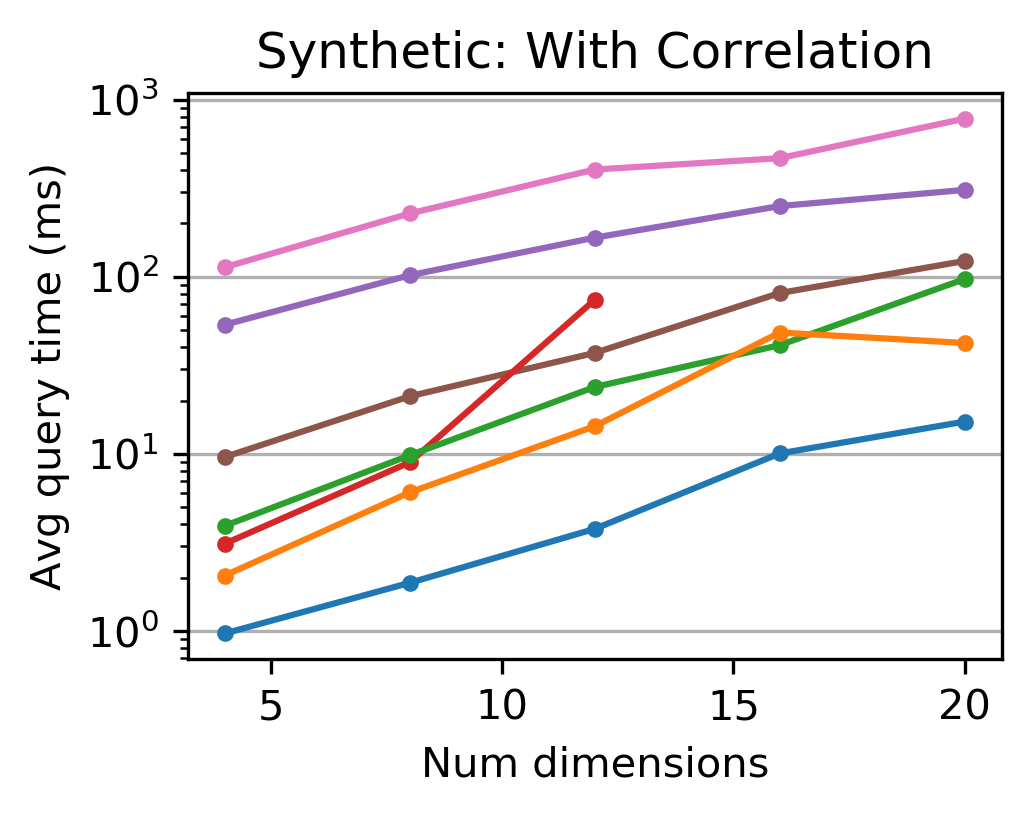
Figure 5: Tsunami outperforms other indexes at higher dimensions. Augmented Grid helps delay the curse of dimensionality on correlated data.
Moreover, Tsunami can adapt to workload changes swiftly, optimizing its index structure within minutes, making it suitable for dynamic environments where data and query patterns evolve rapidly.
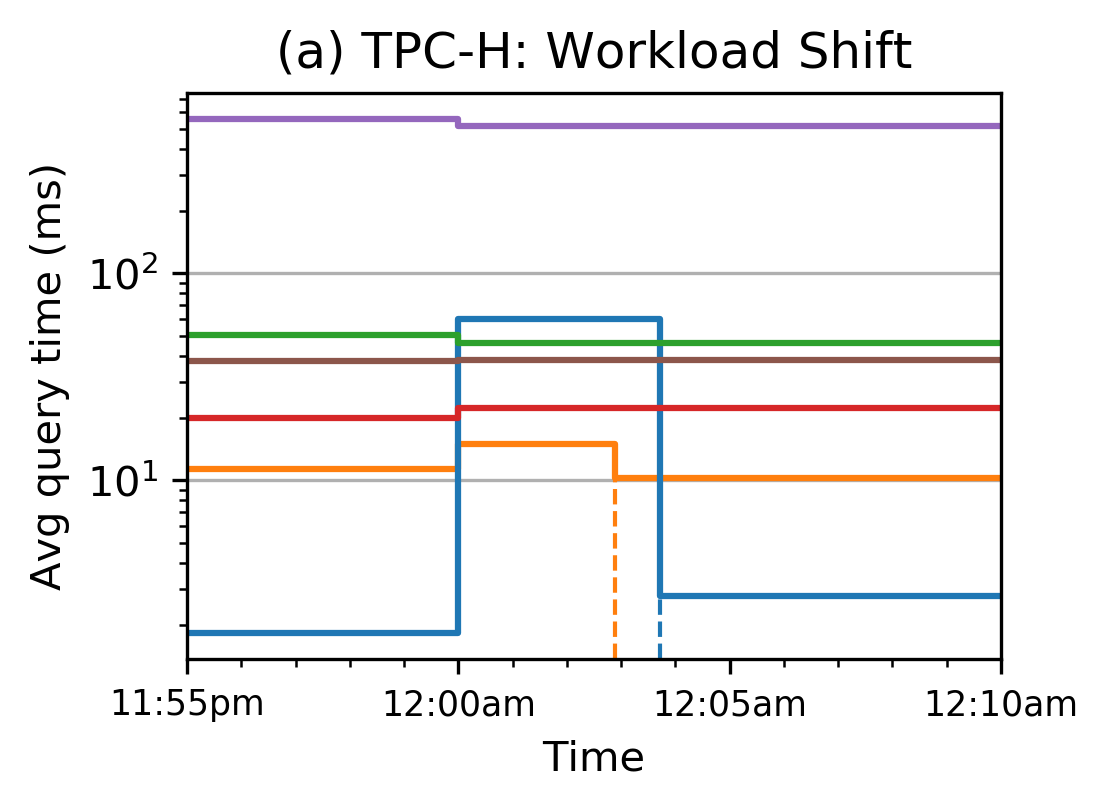
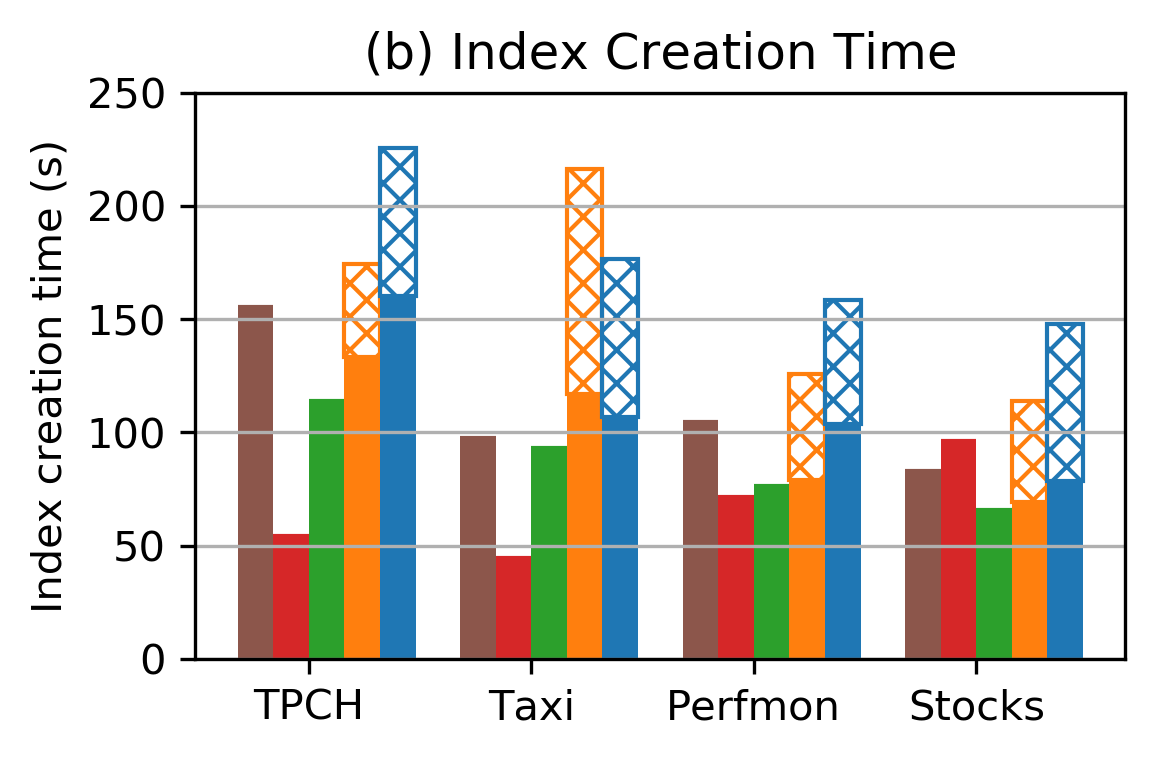
Figure 6: After workload changes, Tsunami re-optimizes quickly to maintain high performance.
Conclusion
"Tsunami: A Learned Multi-dimensional Index for Correlated Data and Skewed Workloads" introduces a significant advancement in the domain of learned indexes. By integrating techniques to handle both query skew and data correlations, Tsunami achieves superior speed and memory efficiency. Its ability to adapt to changing workloads and maintain high performance across diverse scenarios positions it as a strong candidate for modern in-memory database systems. As workloads and data characteristics in real-world applications continue to evolve, solutions like Tsunami that offer both performance and adaptability will be invaluable. Further research could extend Tsunami's applicability to on-disk databases and enhance its handling of complex correlations, thereby broadening its impact on data management systems.