Unified SVM Algorithm Based on LS-DC Loss
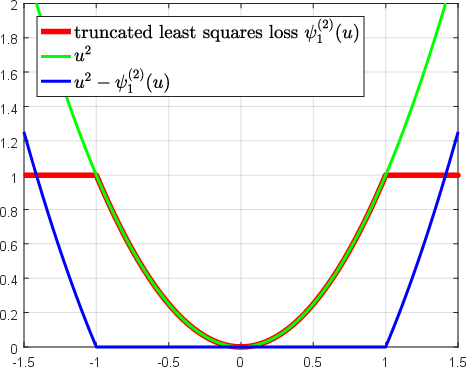
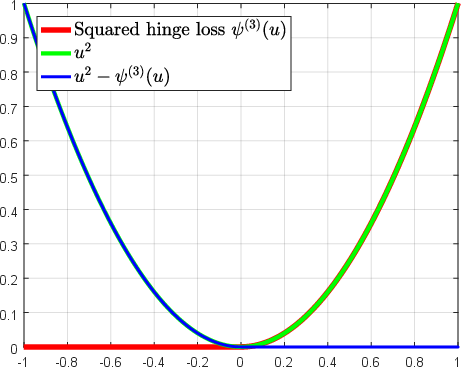
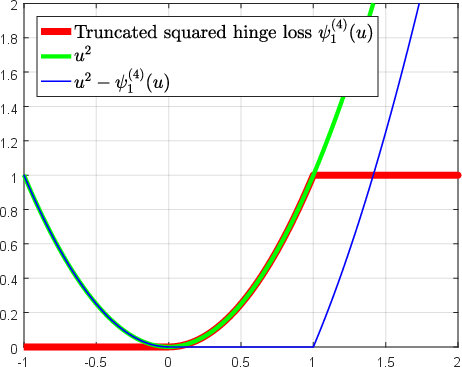
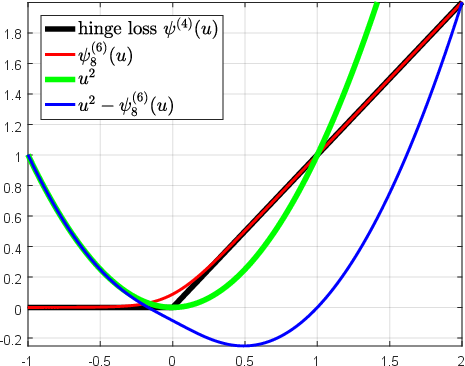
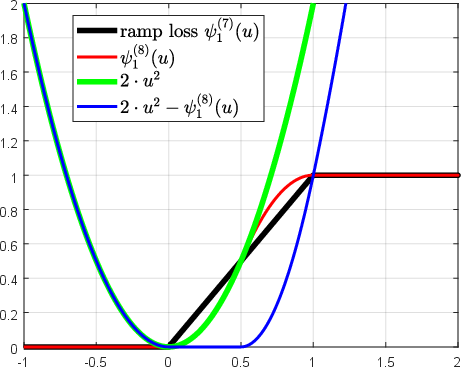
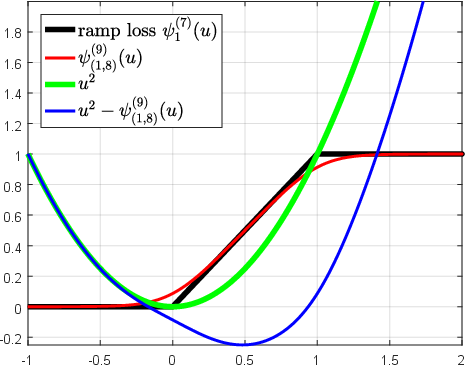
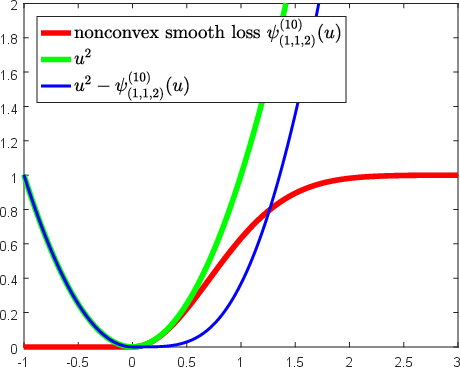
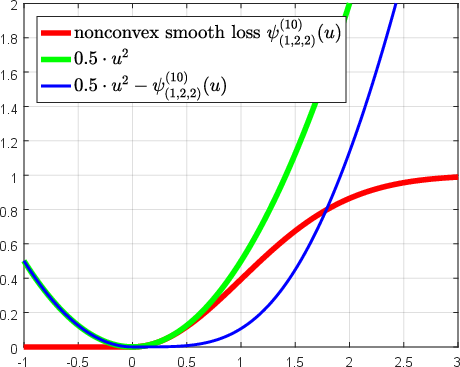
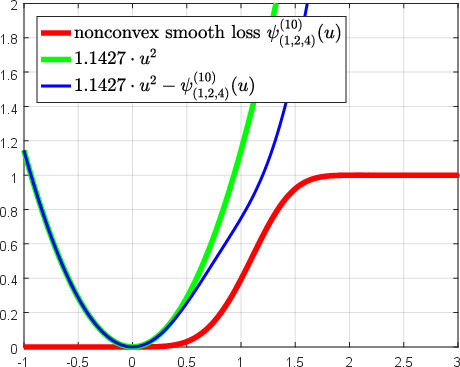
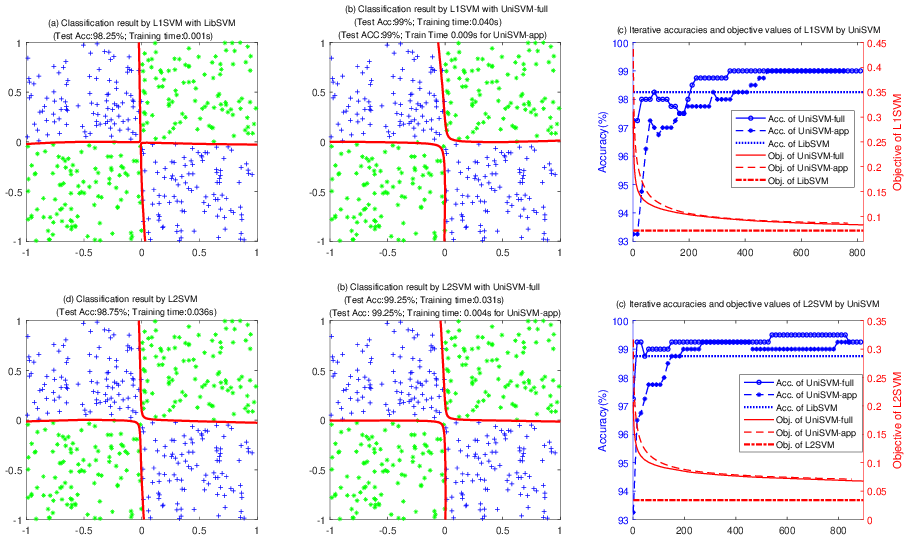
Abstract: Over the past two decades, support vector machine (SVM) has become a popular supervised machine learning model, and plenty of distinct algorithms are designed separately based on different KKT conditions of the SVM model for classification/regression with different losses, including the convex loss or nonconvex loss. In this paper, we propose an algorithm that can train different SVM models in a \emph{unified} scheme. First, we introduce a definition of the \emph{LS-DC} (\textbf{l}east \textbf{s}quares type of \textbf{d}ifference of \textbf{c}onvex) loss and show that the most commonly used losses in the SVM community are LS-DC loss or can be approximated by LS-DC loss. Based on DCA (difference of convex algorithm), we then propose a unified algorithm, called \emph{UniSVM}, which can solve the SVM model with any convex or nonconvex LS-DC loss, in which only a vector is computed, especially by the specifically chosen loss. Particularly, for training robust SVM models with nonconvex losses, UniSVM has a dominant advantage over all existing algorithms because it has a closed-form solution per iteration, while the existing algorithms always need to solve an L1SVM/L2SVM per iteration. Furthermore, by the low-rank approximation of the kernel matrix, UniSVM can solve the large-scale nonlinear problems with efficiency. To verify the efficacy and feasibility of the proposed algorithm, we perform many experiments on some small artificial problems and some large benchmark tasks with/without outliers for classification and regression for comparison with state-of-the-art algorithms. The experimental results demonstrate that UniSVM can achieve comparable performance in less training time. The foremost advantage of UniSVM is that its core code in Matlab is less than 10 lines; hence, it can be easily grasped by users or researchers.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Collections
Sign up for free to add this paper to one or more collections.

