- The paper presents a comprehensive dashcam video dataset with over 10,000 clips capturing diverse Chinese traffic conditions.
- Methodology includes meticulous manual annotations using bounding boxes and tracking labels for 12 object classes in 1,000 videos.
- Implications emphasize the dataset's value in advancing autonomous driving through improved detection and multi-object tracking techniques.
D2-City: A Large-Scale Dashcam Video Dataset of Diverse Traffic Scenarios
The paper presents D2-City, a comprehensive dataset of dashcam videos from various traffic scenarios across China, indispensable for advancing intelligent driving technologies. With over 10,000 clips exhibiting a broad spectrum of road and weather conditions, this dataset serves as a significant resource for both detection and tracking tasks, revealing its utility in developing robust AI models for complex driving environments.
Dataset Overview
The D2-City dataset stands out due to its extensive coverage of real-world traffic scenarios in China, recorded by dashcams from vehicles operating on DiDi's platform. Unlike previous datasets, which often lack diversity or focus on specific tasks, D2-City encapsulates varied environments and conditions, offering more than 11,000 video clips recorded in either 720p HD or 1080p FHD resolution.





Figure 1: A list of sample video frames from the D2-City data collection.
Data Collection and Specification
Data collection was proficiently executed using dashcams from a selection of vehicles across five Chinese cities, ensuring diverse urban and suburban scenarios. Videos were initially filtered for quality issues such as image blur and lighting conditions, preserving only the most informative clips. The dataset, therefore, boasts high variability in video quality and resolution.
The distribution of videos throughout different times of day reveals a focus on capturing well-lit, varied traffic conditions. Particularly, daytime scenarios have been emphasized due to better video quality under natural light conditions.
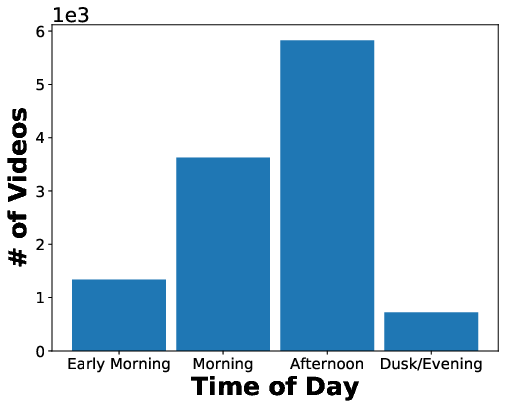
Figure 2: Distribution of videos in different times of day.
D2-City further distinguishes itself by providing detailed annotations for 12 object classes across 1000 videos with comprehensive detection and tracking information. These annotated videos are integral for developing algorithms capable of handling intricate detection and multi-object tracking challenges prevalent in autonomous driving systems.
Annotation and Objectives
Annotation within D2-City was accomplished through manually enriched bounding box and tracking labels using an enhanced CVAT system. Notably absent were learning-based pre-annotations, ensuring the purity of ground-truth data. The annotations cover classes such as cars, vans, buses, various tricycle types, and even blocks and forklift objects, highlighting the unique traffic elements in China.
The dataset provides training, validation, and test splits across 1000 annotated videos, along with detection annotations for keyframes in the remaining collection. This design facilitates tasks in object detection, multi-object tracking, and detection interpolation, crucial for robust scene understanding.
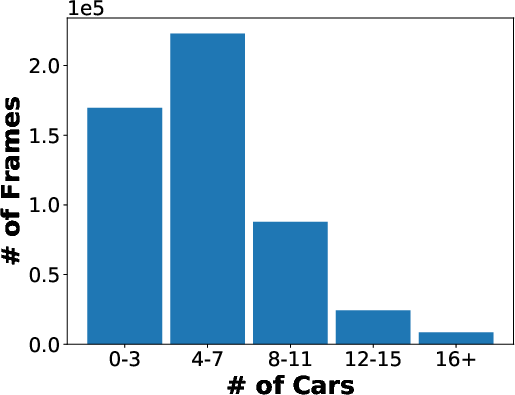
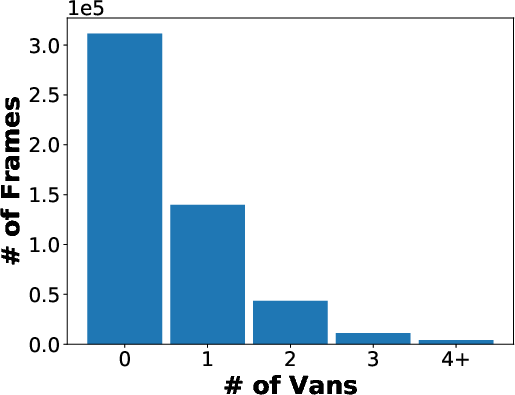
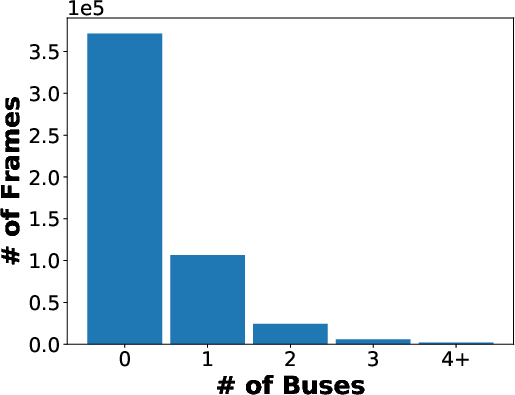
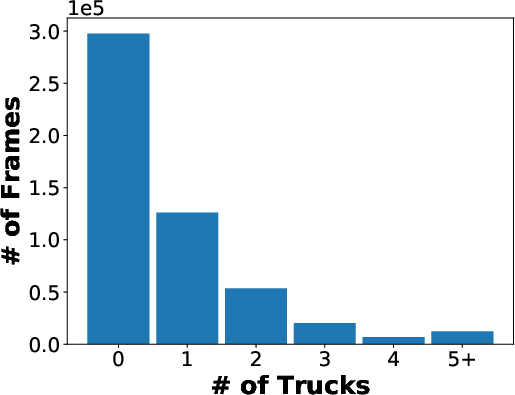
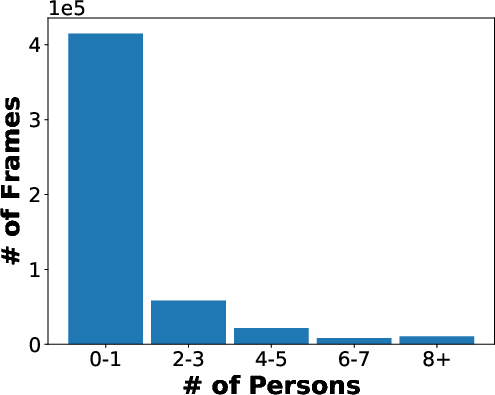
Figure 3: Statistics on the numbers of detection bounding boxes of 5 classes (car, van, bus, truck, and person) in each frame.
Comparisons with Existing Datasets
D2-City addresses the shortcomings of previous driving datasets, such as KITTI, CityScapes, and BDD100K. While KITTI and CityScapes focus on specific aspects like stereo camera inputs or semantic segmentation, D2-City provides voluminous video-level annotations, crucial for tracking applications. Differing significantly from datasets like BDD100K, D2-City offers abundant annotated data pertinent to Chinese traffic conditions, which are less represented in datasets focusing on US scenarios.
Implications and Future Work
The implications of D2-City are far-reaching within the field of intelligent driving. The richness and diversity it offers provide an unparalleled resource for training perception algorithms capable of adapting to complex, real-world scenarios. Additionally, the dataset is poised to prompt further research into more efficient annotation methods and detection interpolations.
Future updates to D2-City will include expanded keyframe annotations, efforts to encapsulate all-weather and extreme conditions, and increase the representation of rare traffic scenarios. This expansion will secure its standing as an essential resource in the continuous development of autonomous driving technologies.
In conclusion, D2-City significantly enhances the landscape of driving datasets, laying a foundation for innovations in perception and intelligent driving systems. This remarkable collection of dashcam videos and annotations engenders a breadth of opportunities for AI advancements in vehicular autonomy.