- The paper’s main contribution is a multilevel strategy that leverages label propagation to accelerate SVM training.
- It utilizes a hierarchy of coarsened problems for efficient initial training followed by uncoarsening to refine support vectors.
- Experimental results demonstrate orders of magnitude speed-ups while maintaining robust classification accuracy on diverse datasets.
Faster Support Vector Machines
The paper "Faster Support Vector Machines" (1808.06394) proposes a multilevel approach to enhance the efficiency of Support Vector Machines (SVMs), allowing them to handle massive datasets effectively. The authors introduce the use of label propagation algorithms for constructing problem hierarchies, achieving significant speed improvements over existing methods without compromising classification accuracy.
Introduction to Multilevel SVMs
The paper begins by addressing the limitations of traditional SVMs due to their computational complexity, which becomes prohibitive for large-scale datasets. Typical SVM training involves solving a complex optimization problem with time complexity ranging between O(n2) and O(n3). The multilevel SVM approach simplifies this by creating a hierarchy of smaller, related problems.
Multilevel Paradigm and Hierarchy Construction
The multilevel process involves creating a hierarchy starting from the largest, original problem and progressively coarsening it. Each level in this hierarchy represents a reduced version of the problem:
Implementation Details
Coarsening Using Label Propagation
Label propagation is applied to cluster the graph representation of data points efficiently. This clustering determines proximity and helps define how the problem can be reduced through contraction.
Efficient Training
In multilevel SVMs, training initially occurs at the smallest level. Due to its reduced size, optimization is rapid, speeding up model selection. The algorithm uses pre-determined kernel parameters, significantly minimizing computational overhead compared to exhaustive grid searches or Uniform Design processes.
Uncoarsening Strategy
During uncoarsening, the support vectors are refined as they re-expand to larger problem sizes. Structural insights from the coarse levels help optimize parameters progressively as the hierarchy is traversed.
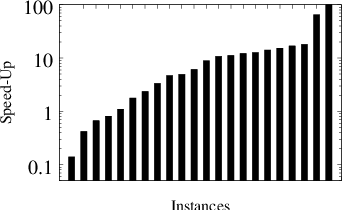
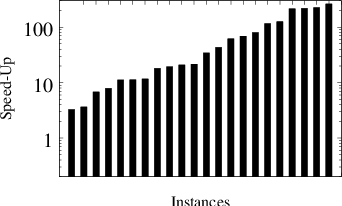
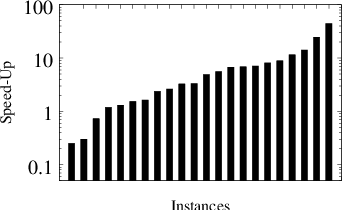
Figure 2: Distribution of speed-ups of our algorithm over mlsvm-AMG when running algorithms on the same k-folds. From left to right: speed-ups of LPSVM over mlsvm-AMG. speed-ups of LPSVMfast
Experimental Results
Extensive experiments show the proposed approach reduces computation time significantly, sometimes by orders of magnitude, compared to leading algorithms such as ThunderSVM. The performance is tested across various datasets, from standard UCI benchmarks to massive data challenges, showing comparable or improved classification quality.
- Performance Metrics: G-mean is used to handle imbalanced datasets, ensuring sensitivity and specificity aren't compromised.
- Speed Comparisons: Compared to mlsvm-AMG, the algorithm achieves geometric mean speed-ups across all tested instances.
Conclusion
This multilevel approach presents a substantial advancement in efficiently scaling SVMs to large data sizes while maintaining robust classification quality. The hierarchical model selection strategy enables quick optimization, making the approach versatile across domains requiring rapid data-driven insights.
Future work could explore automatic parameter tuning and extend the multilevel strategy to other kernel-based learning models, potentially broadening its application scope further. The KaSVM open-source framework supports ongoing development and application studies.