- The paper introduces a low-rank regularizer that forces deep neural networks to learn low-dimensional feature representations for improved robustness against both adversarial and random noise.
- It employs virtual layers and the Nyström projection to enforce low-rank constraints, maintaining discriminative power even under challenging perturbations.
- Empirical results on CIFAR10/100 demonstrate notable improvements, achieving significant compression with up to 400× reduction in parameters and minor accuracy loss.
Robustness via Deep Low-Rank Representations
Introduction
The paper "Robustness via Deep Low-Rank Representations" explores the influence of the dimensionality of representations in DNNs on robustness against both adversarial and random input perturbations. The authors introduce a low-rank regularizer (LR) to enforce feature representations into a low-dimensional subspace. This approach is computationally efficient, trainable end-to-end, and applicable to any layer in a neural network. The resulting models not only show improved resistance to noise but also maintain their discriminative power, offering a memory-efficient way to store data features.
Low-Rank Regularizer
The core of this approach is the low-rank regularizer, which, when applied to DNNs, helps the learned feature representations to reside in a low-dimensional linear subspace. This method hypothesizes that enforcing such low-dimensionality can yield more robust classifiers. The paper proposes:
- Virtual Layers: These layers are not used during prediction but influence the training phase by altering the loss function to include a term that penalizes non-low-rank representations.
- Auxiliary Parameter Matrices: These matrices enforce the low-rank nature during training through parameter updates.
The method leverages the Nystrom method for matrix projection, ensuring the algorithm remains efficient even for high-dimensional data.
Empirical Evaluation
The experiments showcase the low-rank approach on common datasets such as CIFAR10 and CIFAR100 using the ResNet architecture. Key findings include:
- Robustness to Adversarial Attacks: Models trained with LR outperform traditional models significantly in both white-box and black-box adversarial attacks. This is evidenced by the substantially better adversarial test accuracy across various settings of perturbation budget and attack iterations.
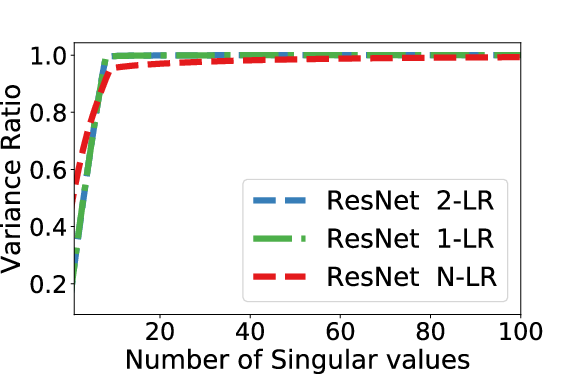
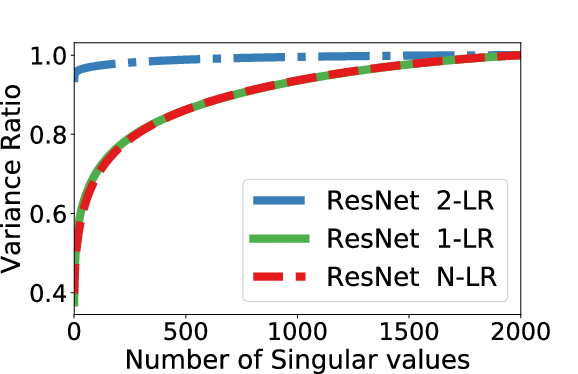
Figure 1: CIFAR10: Activations after last ResNet block.
- Compression Without Significant Accuracy Loss: Using hybrid max-margin models, the paper demonstrates that embeddings can be compressed by up to 400 times with only a minor drop in accuracy. For instance, a 5-dimensional embedding resulted in only a 6% loss in accuracy compared to non-low-rank models which suffered a 27% loss.
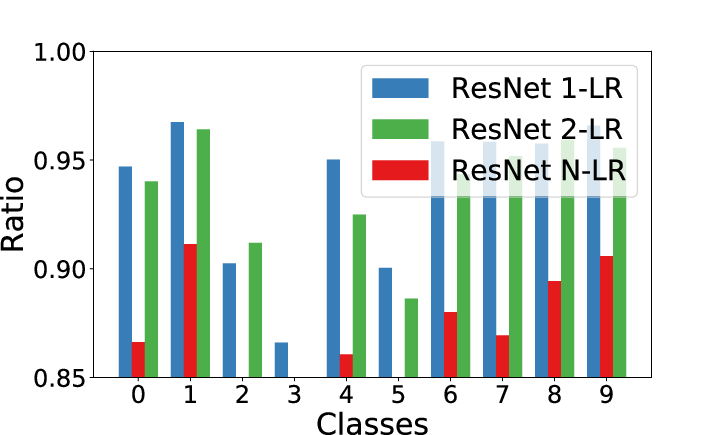
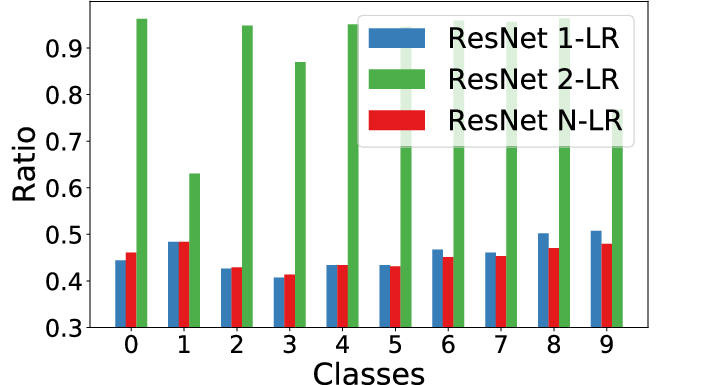
Figure 2: 512 dimensional activations from after last ResNet block.
- Noise Stability: LR models exhibit substantial stability against random pixel perturbations, implicating better generalization and robustness.
Adversarial and Random Noise Experiments
The robustness against adversarial noise is measured using various attack methods: Iterative Fast Sign Gradient Method, Iterative Least Likely Class Method, and DeepFool. LR models consistently require higher noise magnitudes for a similar level of misclassification compared to conventional architectures. This suggests that the noise propagation is effectively attenuated in the presence of LR constraints.
Compression and Efficient Representation
The paper also highlights the application of low-rank regularization in compressing model size. By utilizing the hybrid max-margin model, it is observed that applying low-rank constraints allows for a significant reduction in model parameters while maintaining competitive performance. This offers a practical advantage in scenarios with limited computational resources.
Conclusion
The investigation affirms that low-rank representations via deep learning frameworks significantly enhance robustness against perturbations, both adversarial and random, while providing high compression rates. This research opens pathways for designing neural networks that are inherently robust with efficient memory utilization. Future explorations could expand the application of low-rank principles to other architectures and problem domains, potentially enriching existing DNN robustness frameworks.

