- The paper shows that data augmentation alone can effectively replace weight decay and dropout as regularization across multiple datasets.
- It employs comparative experiments using All-CNN and Wide Residual Networks on ImageNet, CIFAR-10, and CIFAR-100 to assess performance differences.
- The study highlights that higher learning rates and proper hyperparameter tuning are crucial when relying solely on implicit regularization through data augmentation.
An Ablation Study on Weight Decay and Dropout in Deep Neural Networks
Introduction
Deep neural networks have achieved remarkable success in computer vision tasks primarily due to their large model capacity, which often significantly exceeds the number of available training samples. Traditional practices to control such over-parameterization involve employing regularization techniques such as weight decay and dropout. However, these techniques inherently reduce the model's effective capacity, necessitating deeper architectures to counteract this reduction. This paper challenges the necessity of these techniques, positing that sufficient data augmentation alone can match the performance gains typically attributed to explicit regularization.
Experimental Setup
The research focused on validating the hypotheses using well-established datasets including ImageNet ILSVRC 2012, CIFAR-10, and CIFAR-100. ImageNet involves 1.3 million images categorized into 1,000 classes, while CIFAR-10 and CIFAR-100 contain 50,000 images with 10 and 100 classes respectively. The networks were trained with two data augmentation schemes: light and heavier, alongside a baseline with no augmentation.
Two prominent network architectures were evaluated: All-CNN and Wide Residual Networks (WRN). The difference between these architectures lies in their depth and width, with WRN being deeper with more parameters compared to All-CNN. The experiments were designed to observe the effects of weight decay and dropout versus data augmentation on model generalization.
Results and Discussion
The findings are illuminated by the comparative test accuracies presented in Figure 1. Notably, data augmentation alone was capable of providing equivalent regularization benefits compared to when combined with weight decay and dropout, demonstrating marginally superior performance especially in All-CNN models. With WRN models, the additional explicit regularization led to slightly better results, though the improvement was statistically insignificant.
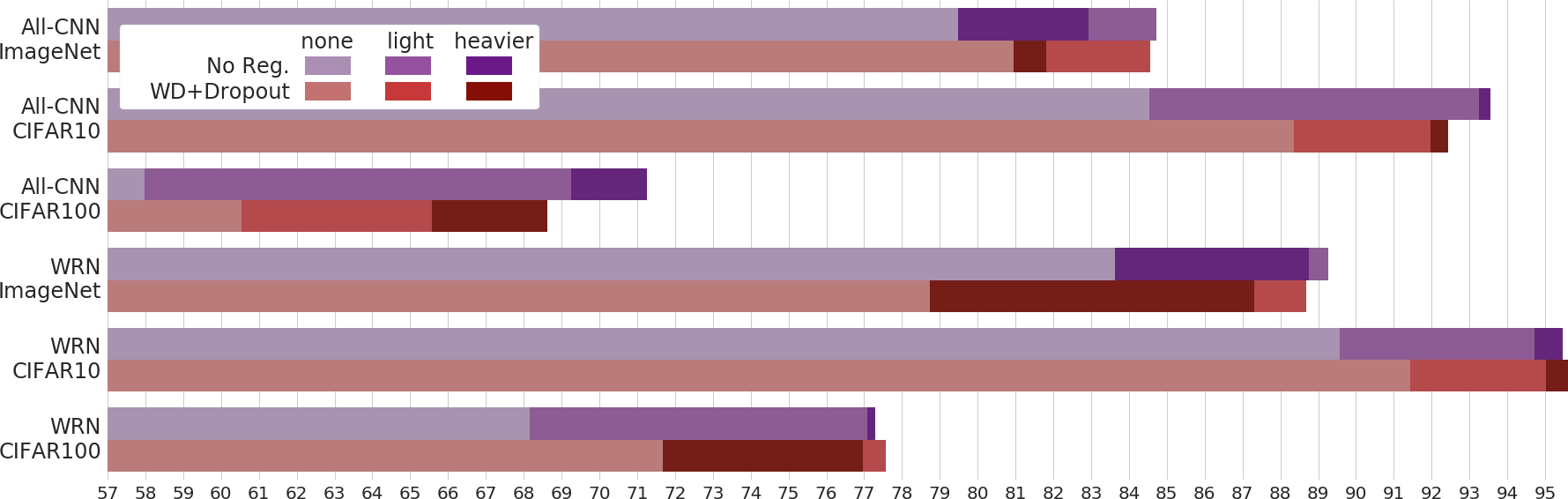
Figure 1: A comparison of the test accuracy of models with and without weight decay and dropout across several datasets, highlighting the efficacy of data augmentation.
Important insights emerged regarding hyperparameter optimization. The study acknowledged that the hyperparameters optimized for regularized models were not ideal when regularization was removed. Surprisingly, higher learning rates proved beneficial in such contexts, indicating that explicit regularization might be an overemphasized necessity in contemporary training protocols.
The adaptability of data augmentation to varying hyperparameters contrasts with the dependency of explicit regularization techniques like dropout and weight decay on hyperparameter tuning relative to architecture and dataset specifics. This flexibility suggests data augmentation as a robust implicit regularization strategy, corroborated by its ability to provide model resilience without requiring elaborate adjustments.
Conclusion
The ablation study reveals critical observations on traditional regularization methods within neural networks. While techniques like weight decay and dropout have been prevalent for mitigating overfitting, this paper demonstrates their potential redundancy when robust data augmentation is employed. The evidence challenges conventional paradigms, encouraging further exploration into leveraging data augmentation as a standalone strategy in deep learning model training.
Future research directions include extending the analysis across a broader array of architectures and datasets to comprehensively understand the dynamic between explicit and implicit regularization methods. Exploring these variables will be pivotal in refining model optimization strategies within machine learning research.