- The paper's main contribution is the introduction of a semiparametric extension to traditional energy-based models by learning a flexible nonlinear mapping from energy to probability.
- The methodology employs piecewise constant approximations and basis expansions to efficiently learn the nonlinear function, resulting in improved log-likelihood performance on neural data.
- The results demonstrate that the semiparametric model significantly outperforms conventional models by capturing higher-order interactions and complex distributions in neural recordings.
Semiparametric Energy-Based Probabilistic Models
Introduction
The paper "Semiparametric Energy-Based Probabilistic Models" introduces a generalization of traditional energy-based models (EBMs) by incorporating a semiparametric approach. Unlike standard EBMs where the probability of a state is a function of the state's energy, this method employs an arbitrary positive, strictly decreasing, and twice differentiable nonlinear function to map energies to probabilities. This generalization aims to capture distributions with wide dynamic ranges, a characteristic seen in various data types, notably the neural activity data from retinal ganglion cells.
Traditional EBMs model probabilities as:
p(s;α)=Z(α)e−E(s;α)
where E(s;α) denotes the system's energy, and Z(α) is the partition function. In this framework, the new model adjusts the energy-based formulation to:
p(s;α,V)=Z(α,V)e−V(E(s;α))
This extended model parameterizes the energy function E(s;α) as before but incorporates a nonlinear mapping V(E), to be explicitly learned from the data. This nonlinearity V is key for relating the model's energy to observed data distributions while being parameterized in a way that respects its mathematical properties, like positive monotonicity.
Non-parametric Nonlinearity and Learning
The function V is represented using a piecewise constant approximation of a more complex nonlinear form, imposing minimal prior constraints to remain adaptable. This representation employs a basis expansion in terms of a function W and constants γ1 and γ2, facilitating an unconstrained optimization the learning process necessitates.
For learning, the paper proposes maximizing the likelihood of energy distributions, both empirical and model-generated. This approach enforces that the learned nonlinear function aligns the theoretical model's predictions closely with the training data's statistical structure. The mechanism is efficient, paralleling methods from statistical mechanics that smooth density estimations over complex energy landscapes.
Experiments and Results
The model was tested on neural recordings from retinal ganglion cells, assessing its capability to replicate the neural population statistics significantly better than other models, like K-pairwise models or traditional Boltzmann machines.
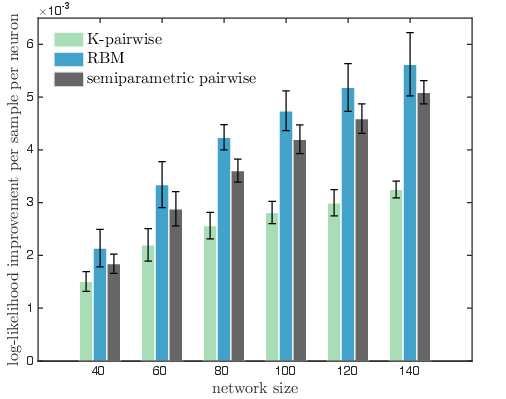
Figure 1: Out-of-sample log-likelihood improvement per sample per neuron averaged over subnetworks. Errorbars denote variation over subnetworks (one standard deviation), not the accuracy of likelihood estimates. Baseline is the pairwise model.
The results, as visualized, confirm that the semiparametric model consistently improves performance when compared to conventional pairwise models. This is indicative of the intrinsic adaptability offered by the nonlinear mapping function, which can expressively capture the distribution of complex, higher-order interactions in the neural data.
Understanding Nonlinearity
Further investigation into the model's success manner revealed that the semiparametric model inferred nonlinearities that align with expectations from statistical mechanics—in essence, suggesting a smooth transition towards an understanding of intricate dependencies across observed variables.
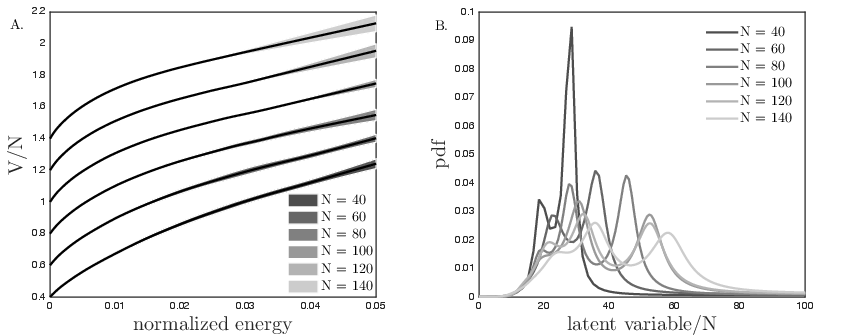
Figure 2: A. Inferred nonlinearities of the semiparametric pairwise model. The shift along the y-axis is arbitrary, increasing readability. B. Inferred probability densities of the latent variable for one sequence of subnetworks.
These nonlinear transformations, as depicted, reflect sophisticated latent variable coupling across the systems being modeled. The paper provides evidence that the role of V can be viewed as an implicit introduction of such latent global couplings, postulated by theoretical expansions into latent variable models.
Implications and Future Work
The semiparametric energy-based model opens avenues for applications across data domains characterized by complex dependencies—neuroscience being paramount but also extending to image processing and other domains exhibiting global couplings.
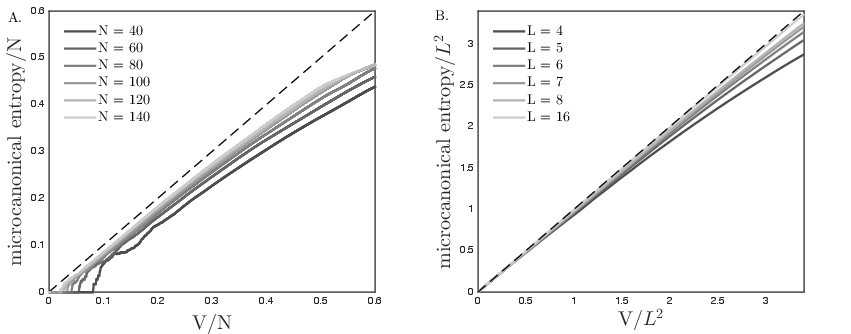
Figure 3: A. Plot of the inferred nonlinearity vs the microcanonical entropy for the semiparametric pairwise model. B. The same for the elliptically symmetrical model of luminance distribution in natural images.
The future works might explore enhancing the semiparametric framework's efficiency and scalability, potentially integrating it with deep-learning architectures to model even larger and more diverse datasets.
Conclusion
The introduction of semiparametric energy-based probabilistic models represents a significant enhancement in modeling complex systems with expansive dynamic ranges. By learning not just the potential energies but also the transformations from energies to probabilities, the paper proposes a powerful method for capturing critical dependencies in high-dimensional data, a method that carries promising applications across various scientific fields.