- The paper introduces a fully data-driven method that learns hand-eye coordination using CNNs and over 800,000 grasp attempts.
- It employs continuous visual servoing with real-time feedback and cross-entropy sampling to reduce grasp failure rates to as low as 10–17.5%.
- The approach generalizes across diverse hardware and environments, establishing a scalable platform for autonomous manipulation.
Learning Hand-Eye Coordination for Robotic Grasping via Deep Learning and Large-Scale Data Collection
Motivation and Problem Setting
The paper addresses the challenge of integrating visual perception with robotic actuation for robust, versatile grasping from monocular images without explicit camera-to-arm calibration. Traditional approaches typically depend on geometric models, hand-engineered features, or explicit calibration to facilitate visual servoing, limiting adaptability and robustness in real-world, unstructured environments. The authors propose a fully data-driven solution capable of real-time visual feedback-based control, relying solely on monocular RGB input and gripper-relative motor commands. The central objective is learning continuous hand-eye coordination that generalizes across varying robot hardware, camera pose, and object types, establishing foundational elements for scalable autonomous manipulation.
Large-Scale Data Collection Framework
To enable generalization across hardware and environmental variability, the authors implement a distributed data collection pipeline using up to 14 robotic manipulators with distinct camera placements and subject to hardware wear. The robots attempted over 800,000 grasps on diverse objects, with no manual annotation or supervision except for object replenishment in bins. Grasp attempts were conducted on flat surfaces only, and success detection used a combination of gripper state and image-based drop tests. The breadth and diversity of this dataset surpass previous grasping literature by orders of magnitude, providing the necessary signal for end-to-end training of high-capacity models.

Figure 1: The aggregated grasp attempt setup, leveraging up to 14 robots to amass over 800,000 data points.
CNN-Based Grasp Success Prediction
The authors introduce a convolutional neural network architecture that ingests monocular RGB images and parameterizes a candidate gripper motion via a 3D translation and sine/cosine encoding for vertical orientation. The network predicts the probability that executing such a motion will lead to a successful grasp. Crucially, the model is not informed of explicit projections of gripper pose in image space—it's tasked with inferring spatial relationships from raw sensory data, making calibration unnecessary and leveraging the CNN's spatial reasoning capabilities.


Figure 2: Visual input to the network with sampled grasp candidates color-coded for predicted success probabilities.

Figure 3: Data sample formulation, each grasp generates a trajectory of (image, displacement vector, success label) tuples.
The architecture concatenates the current and pre-grasp image (with gripper removed), processes them via a series of convolutions with batch normalization, then fuses the motion vector input after the fifth convolution via tiling, followed by additional convolution and pooling. Two final fully connected layers yield a sigmoid probability for grasp success.
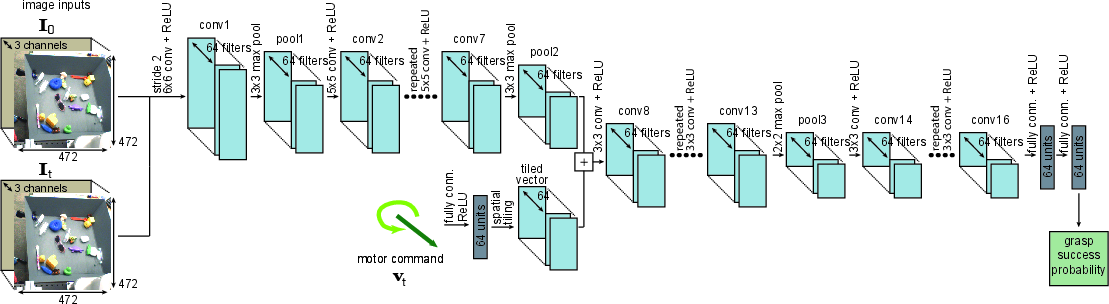
Figure 4: Detailed CNN architecture, highlighting multi-scale convolutional processing and motion-vector fusion.
Continuous Visual Servoing and Sampling-Based Control
The trained network is used in a closed-loop servoing system. Candidate motor commands are sampled and evaluated via cross-entropy method (CEM), selecting the motion with maximal predicted grasp success. This mechanism operates at 2–5 Hz, continuously recomputing optimal actions to adapt to environmental or actuation perturbations. Command constraints (e.g., workspace bounds, height, joint limits) are imposed via rejection sampling, facilitating integration with higher-level user directives.
Heuristics determine when to attempt a grasp or reposition the gripper: if the probability of success with no-motion exceeds 90% of the maximal candidate, the gripper closes; if it’s less than 50%, the gripper is raised before repositioning—this prevents collisions and encourages exploration, particularly in the presence of clutter.
Hardware and Environmental Diversity
The dataset's robustness arises from hardware and environmental diversity: robots varied in camera pose, lighting, gripper geometry, and object sets, due to both intentional configuration and inevitable wear/tear.

Figure 5: Single manipulator structure—7DOF arm, underactuated gripper, monocular camera.

Figure 6: Sample images across all robots, demonstrating variation in bin positions, lighting, and object types.

Figure 7: Gripper wear at experiment conclusion, exemplifying hardware variation endured during data collection.
Experimental Results and Analysis
Evaluations with previously unseen objects encompassed a spectrum of shape, material, size, and translucency, further validating generalization.

Figure 8: Test objects and setup—broad diversity in weight, rigidity, and geometry.
The method was benchmarked against: (1) a random grasp baseline, (2) hand-engineered geometric grasping with depth input and calibration, and (3) an open-loop CNN-based grasp prediction requiring calibration. Performance is quantified via failure rates in both with-replacement and no-replacement protocols.
Key results include:
- Continuous feedback-based servoing achieves the lowest failure rates: 10–17.5% without replacement (first 10–30 attempts), 20% with replacement.
- Open-loop and hand-engineered baselines fail to match performance, particularly in clutter or with calibration/missing depth input.
Qualitatively, the approach learns context-sensitive grasp strategies, e.g., preferring embedding for soft objects, demonstrating implicit learning of material properties and affordances.

Figure 9: Grasp strategies for objects of similar appearance but differing material compliance.

Figure 10: Success with complex, challenging objects including awkward geometries and translucency.
Strong empirical evidence is presented showing monotonic improvement with increasing dataset size, underscoring the necessity of large-scale real-world data for robust manipulation.
Theoretical Implications
The approach encapsulates a form of transitive Q-function learning: action representations use displacement vectors from arbitrary starting poses, and predictions are decoupled from intermediate dynamics under the assumption that actions yield transitive outcomes. Although this is an approximation, it avoids instability and bootstrapping in standard fitted-Q iteration, allowing dense supervised learning. Expanding beyond this assumption via reinforcement learning could unlock the ability to intentionally manipulate scene configuration pre-grasp, e.g., by nonprehensile rearrangement.
Implications and Future Directions
This work exemplifies the practicality and scalability of self-supervised, large-scale learning for manipulation. The learned model achieves calibration-free, feedback-driven grasping, applicable across hardware variance and object diversity. However, generalization to unseen environments or robot types depends on dataset representativeness—future extensions should include diverse surfaces, settings, and robot morphologies.
The collective learning paradigm, wherein pooled experience from distributed robots accelerates skill acquisition, is particularly conducive to real-world deployment scenarios: cloud robotics and continual learning at the edge become tractable.
Additional research avenues include reinforcement learning for multi-step manipulation, domain adaptation for transfer to novel robots, and dataset expansion for more sophisticated manipulation tasks.
Conclusion
The paper presents a rigorously evaluated, fully data-driven framework for robotic grasping that leverages deep convolutional networks trained on an unprecedentedly large, diverse dataset collected from multiple manipulators. By eschewing explicit calibration and relying on real-time visual feedback, the method achieves robust performance in cluttered, variable environments on previously unseen objects. The study establishes a foundation for scalable self-supervised robotic learning and underscores the necessity and viability of extensive real-world data collection for manipulation tasks. Future research should explore transfer across robot platforms, broader manipulation domains, and integration with advanced RL strategies for complex task sequencing.

