Characterizing Phishing Pages by JavaScript Capabilities
Abstract: In 2024, the Anti-Phishing Work Group identified over one million phishing pages. Phishers achieve this scale by using phishing kits -- ready-to-deploy phishing websites -- to rapidly deploy phishing campaigns with specific data exfiltration, evasion, or mimicry techniques. In contrast, researchers and defenders continue to fight phishing on a page-by-page basis and rely on manual analysis to recognize static features for kit identification. This paper aims to aid researchers and analysts by automatically differentiating groups of phishing pages based on the underlying kit, automating a previously manual process, and enabling us to measure how popular different client-side techniques are across these groups. For kit detection, our system has an accuracy of 97% on a ground-truth dataset of 548 kit families deployed across 4,562 phishing URLs. On an unlabeled dataset, we leverage the complexity of 434,050 phishing pages' JavaScript logic to group them into 11,377 clusters, annotating the clusters with what phishing techniques they employ. We find that UI interactivity and basic fingerprinting are universal techniques, present in 90% and 80% of the clusters, respectively. On the other hand, mouse detection via the browser's mouse API is among the rarest behaviors, despite being used in a deployment of a 7-year-old open-source phishing kit. Our methods and findings provide new ways for researchers and analysts to tackle the volume of phishing pages.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What this paper is about
This paper looks at phishing websites — fake pages that try to trick people into giving away passwords or other personal info — and shows a new way to sort them into groups automatically. Instead of looking at how the pages look, the authors watch what the page’s JavaScript actually does in the browser. By grouping pages that “behave” the same way, they can spot which “phishing kits” were used to build them and see which tricks are popular across many attacks.
The main questions the authors asked
- Can we group phishing pages by the JavaScript actions they perform, and do those groups match the underlying phishing kits used to build them?
- Which browser-based tricks (like fingerprinting a device, hiding from bots, or popping up permission boxes) are most common across phishing pages?
- Can this automated grouping reduce the amount of manual work analysts do and help them track phishing activity at large scale?
How the research was done (in everyday language)
Think of each phishing page like a person in a room. Instead of judging them by their clothes (how the page looks), the authors listened to what they said and did (the JavaScript they ran). They used:
- A special web browser that records every important JavaScript action a page performs. These actions are calls to “browser APIs” — built‑in abilities like “ask for the user’s screen size,” “read cookies,” “make a network request,” or “start a timer.” You can think of these as the page’s “moves.”
- Big lists of suspected phishing links from well-known feeds (so they had lots of pages to test).
- A tool that sometimes finds the actual phishing kit zip files left on the same server. This gave them “ground truth” — confirmed info about which kit built which page.
Then they:
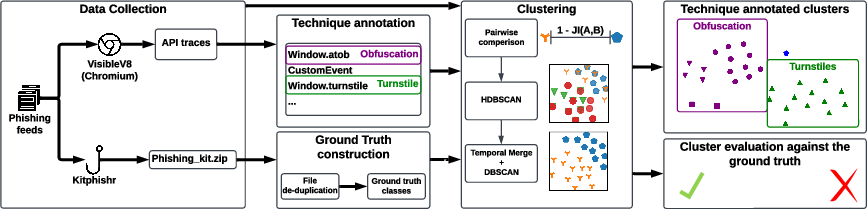
- Collected the set of browser actions each page performed in its own code (not counting third‑party tools like analytics when possible).
- Measured how similar two pages were by comparing these action sets. If two pages used the same kinds of actions, they were likely built from the same kit.
- Used a clustering algorithm (a math method that groups similar things automatically) to put pages into groups without telling the algorithm how many groups to make.
- Checked the quality of these groups by comparing them to the known kit labels (when they had them) and by looking at how cleanly separated the groups were (when they didn’t).
Key ideas explained simply:
- Browser API: A built-in “ability” that webpages can use, like reading cookies or making network requests.
- Dynamic analysis: Watching what the page does while it’s running, like observing someone in action.
- Clustering: Sorting things into piles where items in the same pile are more similar to each other than to items in other piles.
What they found and why it matters
Here are the most important results, explained simply:
- Grouping by behavior works very well. When they had confirmed kit labels to check against, their behavior-based groups matched the real kits with about 97% accuracy (and about 69% in a tougher, rebalanced test) — much better than earlier attempts that relied on static features like page structure or URL patterns.
- Behavior beats “code fingerprints.” Using what the code did (browser API usage) grouped pages more accurately than using raw script file hashes. This makes sense: kits often change filenames or pack code differently, but their behavior — the features they offer attackers — tends to stay similar.
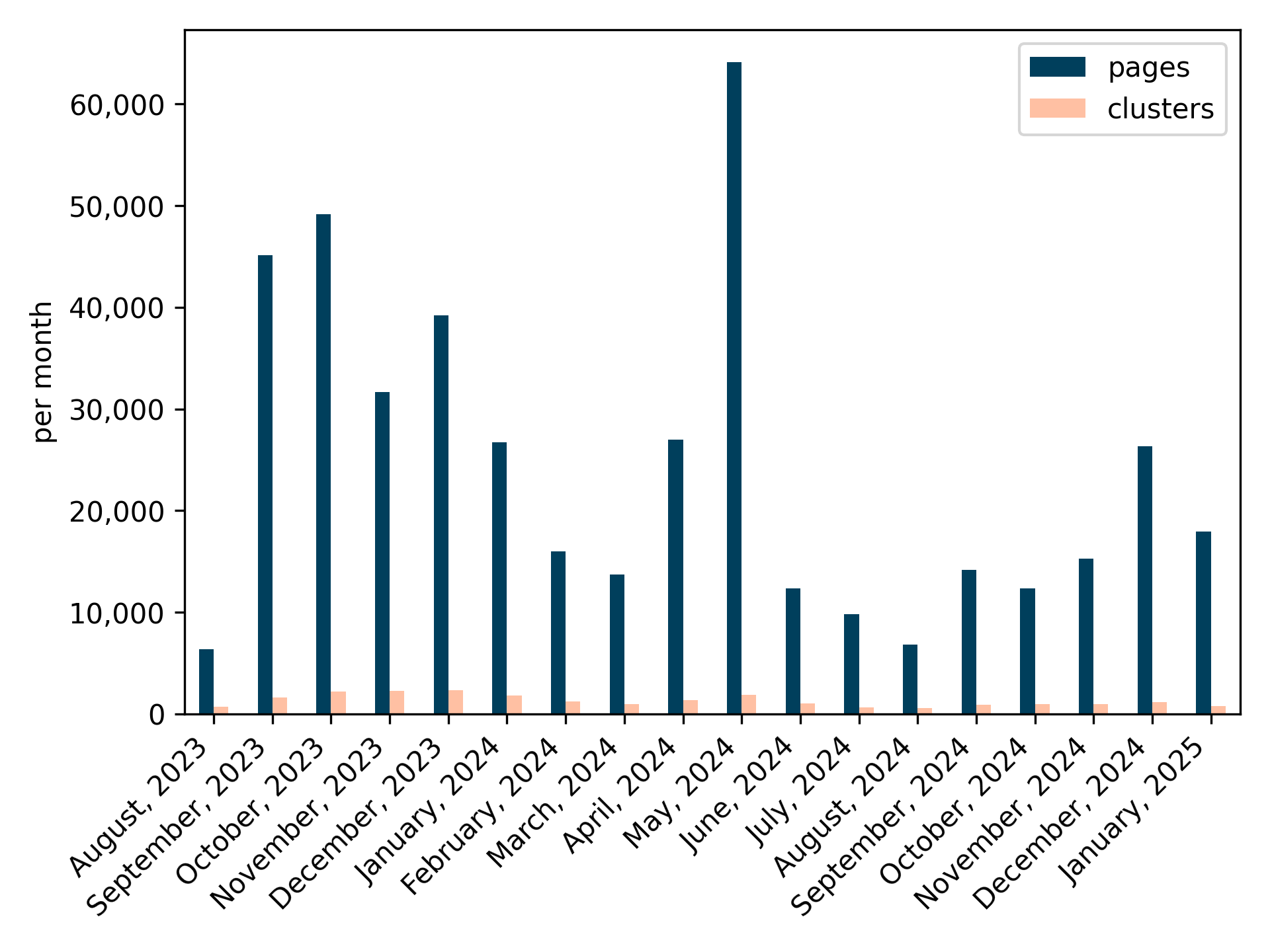
- They handled huge scale. From 1.3 million crawled URLs, they clustered 434,050 phishing pages into 11,377 behavior-based groups. That means analysts can study thousands of “kinds” of phishing instead of hundreds of thousands of pages one by one.
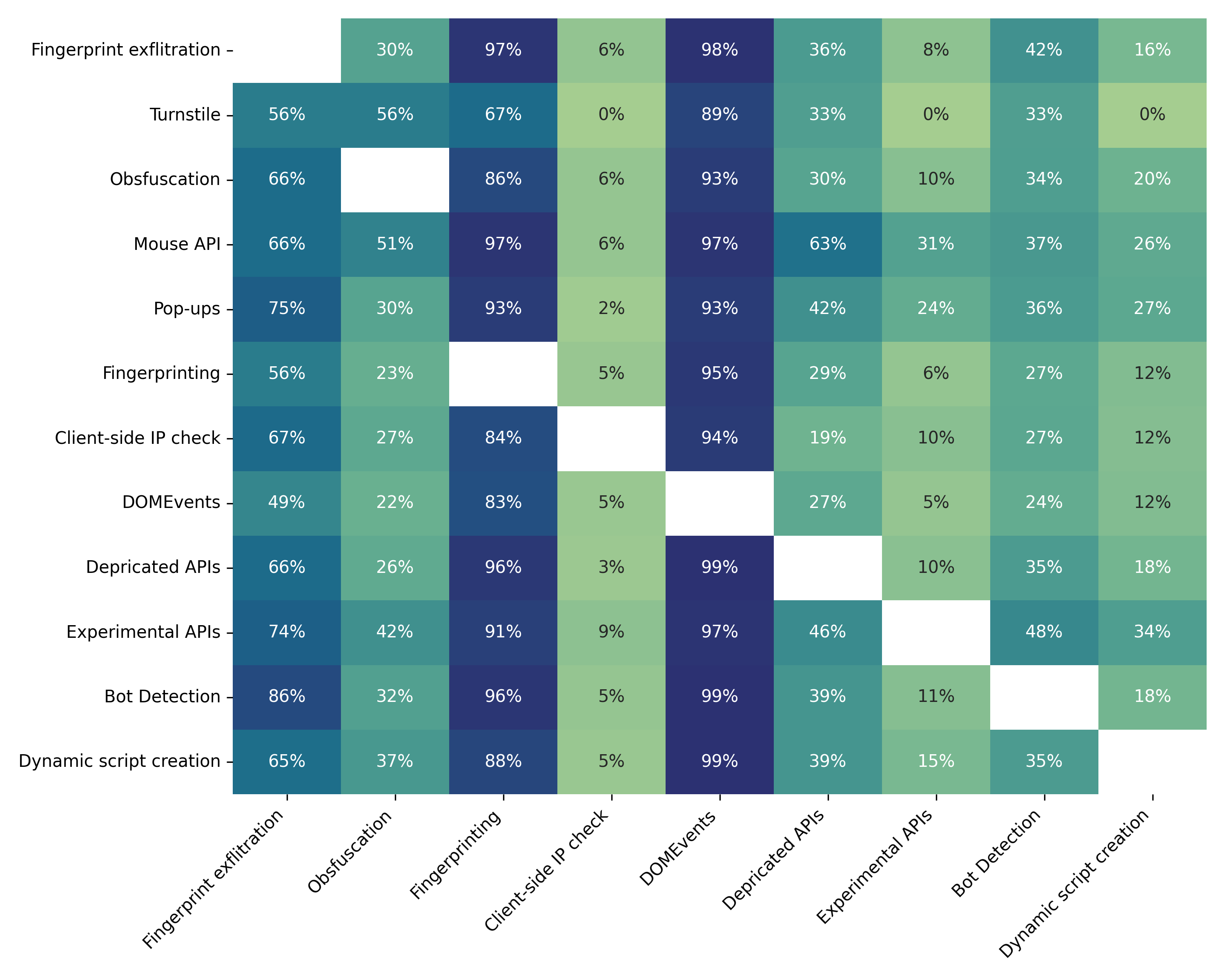
- Common tricks are everywhere:
- UI interactivity is nearly universal. About 9 in 10 groups used click handlers or other interactive code — often part of multi-step phishing where the site waits for user actions.
- Fingerprinting is very common. About 80% did basic fingerprinting (like reading cookies or user agent), and roughly two‑thirds used more advanced techniques. This helps attackers tell real people from bots and can help them bypass extra security checks.
- Some tricks are rare:
- Mouse movement detection and Cloudflare Turnstile checks showed up in only small fractions of groups.
- Pop-up permission requests (like notifications or camera/mic) have dropped compared to older studies, likely because browsers made these prompts quieter and less interruptive.
- Cloaking with IP reputation exists but isn’t universal. Around 500 groups (roughly 20,000 pages) called third‑party IP info services in the browser to decide whether to show the real phishing content (for example, hiding from cloud servers or school networks).
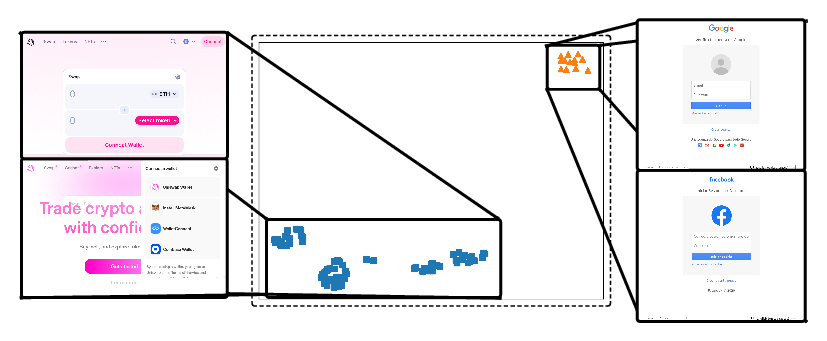
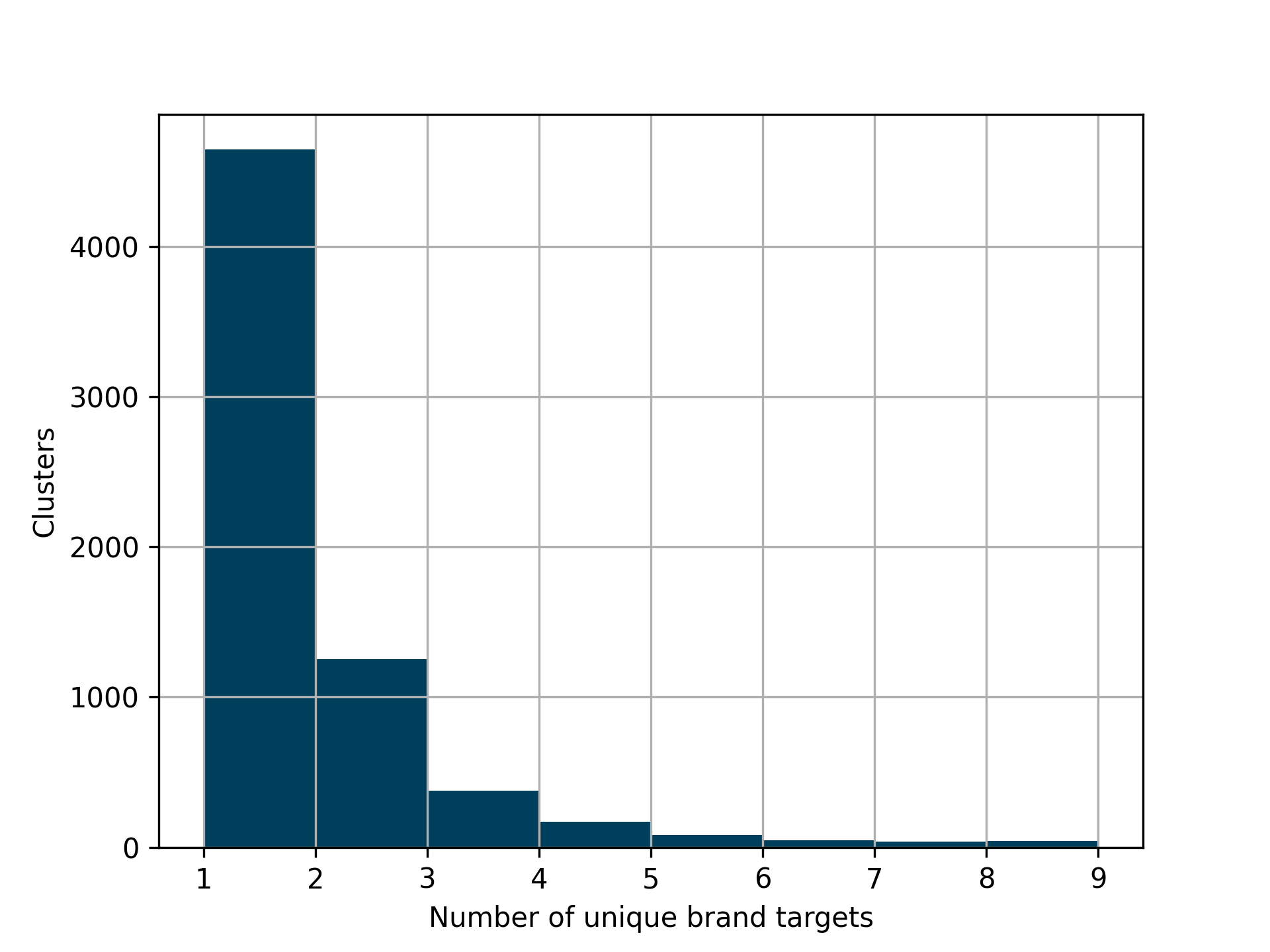
- Brand focus. About two-thirds of groups targeted a single brand (like a specific bank or social network), suggesting many kits are brand-specific modules packaged for ease of use.
Why this matters:
- Defense teams get a “map” of the phishing landscape based on what pages do, not just how they look. That’s harder for attackers to fake and scales better.
- Knowing which tricks are most popular helps defenders focus on the right browser signals and build better automatic detection.
What this could change going forward
- Faster, smarter responses: Security teams can quickly identify which kit family a new phishing page belongs to, estimate how widespread it is, and understand its likely tricks — without manual code reading.
- Better detection tools: Browser-side behaviors that are reliable signals (like certain fingerprinting or timing checks) can feed into new detectors that keep working even when attackers hide their code.
- Tracking kit evolution: Because the method groups by behavior, it can reveal when a kit updates or returns after a pause, helping researchers follow the “life story” of phishing campaigns over time.
- Reduced workload: Turning millions of pages into a manageable number of behavior-based groups lets analysts study patterns instead of chasing individual sites.
In short, the paper shows that watching what phishing pages do in the browser is a powerful, scalable way to sort them, spot the kits behind them, and see which tricks are spreading — giving defenders a stronger and more efficient path to protect people online.
Knowledge Gaps
Below is a single, actionable list of knowledge gaps, limitations, and open questions that remain unresolved in the paper. Each item highlights a specific uncertainty or missing exploration for future researchers to address.
- Vantage-point bias and cloaking effects: The crawler operated from an educational network, which some pages explicitly cloak against. Quantify how vantage point (educational vs. residential vs. mobile; different countries and ASNs) changes observed behaviors, the rate of “no first-party API execution,” and technique prevalence. Replicate with diverse IPs and geolocations.
- Limited interaction and dwell time: Crawls waited 45 seconds and did not simulate user interactions beyond page load. Measure sensitivity to dwell time and add scripted interactions (clicks, keystrokes, scrolling, form input, navigation) to capture multi-step flows, deferred code, time bombs, and conditional logic that only executes after user actions.
- Headless detection and crawler fingerprinting: Puppeteer-stealth may still be detectable. Systematically assess how anti-bot detection impacts execution traces and clustering (e.g., comparing headless vs. full browsers, Chrome vs. Firefox vs. Safari, desktop vs. mobile). Quantify the fraction of pages altering behavior due to crawler artifacts.
- First-party–only tracing may miss kit functionality: The paper excludes third-party scripts (except for special handling of Cloudflare Turnstile) and defines “first-party” strictly by root domain. Evaluate how this choice hides kit behaviors loaded via CDNs or separate domains, and develop robust criteria to include kit-related third-party scripts without inflating noise.
- Cloudflare and third-party exclusion side effects: Excluding cdn-cgi and relying on the presence of Window.turnstile may undercount cloaking/abuse-prevention widgets or misattribute their use. Validate Turnstile detection via multiple signals (DOM patterns, network requests, script provenance) and quantify the impact of Cloudflare exclusion on technique prevalence.
- Unordered API-set representation discards sequence and context: Clustering uses sets of APIs (unordered, unweighted). Investigate sequence-aware and context-aware features (API n-grams, call graphs, parameter/value-aware signals, timing relations) and assess whether they improve kit differentiation and robustness to adversarial padding.
- Adversarial robustness of API-based clustering: Kit authors can add dummy API calls or randomize calls to perturb set-based features. Stress-test clustering with synthetic and observed adversarial modifications (padding, randomization, API suppression) and identify resilient features (e.g., stable call motifs, dependency patterns, API co-occurrence structure).
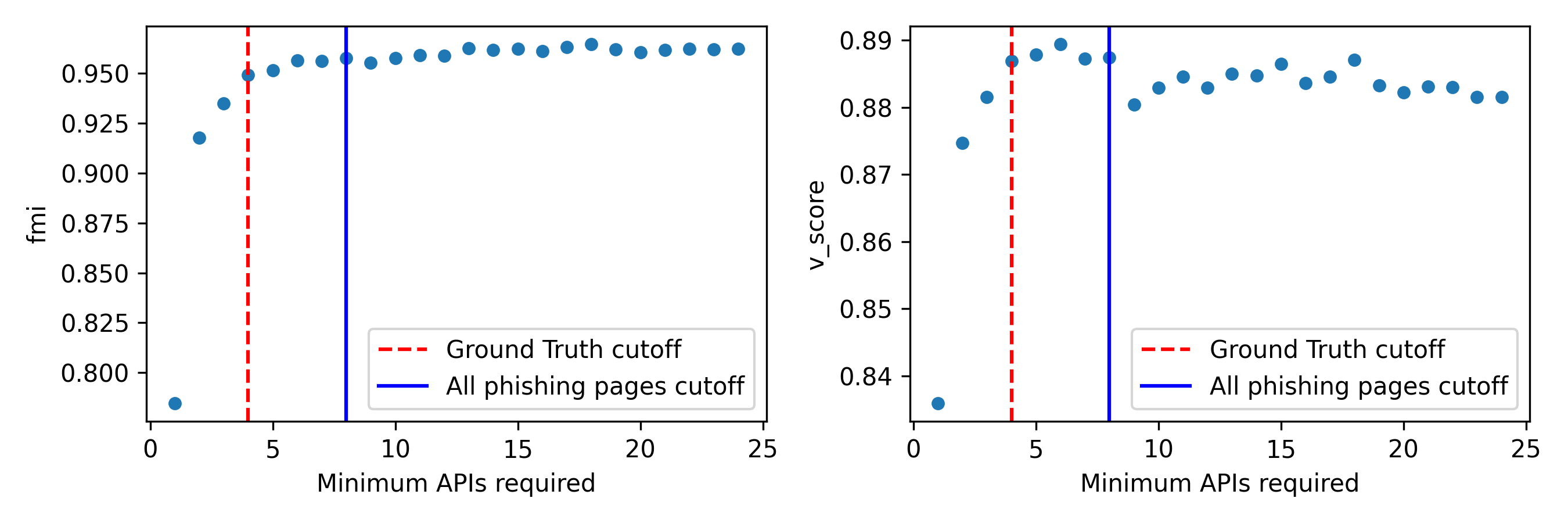
- Ground-truth coverage and fidelity: Ground truth relies on kits recoverable via KitPhishr (leftover zip downloads) and a 90% Jaccard file-similarity threshold for kit-family deduplication. Evaluate biases (only kits with recoverable zips), validate the 90% threshold via sensitivity analysis, and address encrypted zips treated as unique kits (could be duplicates). Expand ground truth through manual attribution, community intelligence, or server-side evidence.
- Rebalancing and dominant-kit effects: FMI accuracy drops when rebalancing the ground truth (e.g., 0.69 for a dominant kit). Examine methods to mitigate dominance effects (stratified sampling, class-weighted metrics, calibrated clustering validations) and characterize accuracy across brands, hosting types, and technique complexity.
- Rolling-window clustering and merging design trade-offs: The rolling 4-week windows with DBSCAN merging (ε=0.05) may under-/over-merge clusters; intersections as “representative API sets” can be brittle and shrink with non-determinism. Perform sensitivity analyses on window size, merge ε, and representative selection (e.g., medoids, weighted unions, probabilistic presence) and explore streaming/online clustering.
- Overlapping clusters unresolved: 108,954 pages belong to multiple clusters, but overlapping membership is not reconciled. Investigate overlapping/soft clustering approaches (e.g., community detection, topic modeling) and define rules for assigning or weighting memberships to better represent kit families and re-use.
- Large proportion of pages with zero first-party APIs: 388,536 pages executed no first-party APIs. Diagnose root causes (cloaking, redirects, third-party-only scripts, permission gating, interaction requirements) and develop methods to recover signals (e.g., multi-hop crawl through redirect chains, interaction replay, DOM diffing, network-level features).
- Technique taxonomy and coverage gaps: The technique set is limited to 10 categories and a manual API mapping. Extend the taxonomy (e.g., webdriver checks, canvas/font/audio fingerprinting specifics, hardware concurrency, battery, font probes, WebGL fingerprints, timing anomalies, referrer-based gates, URL-chain cloaking) and validate the mapping’s precision/recall via manual audits and labeled samples.
- Validation of technique detection: The manual mapping from APIs to techniques is not empirically validated. Quantify detection accuracy (precision/recall) against gold-standard labels and assess false positives (e.g., benign use of TextDecoder.decode or window.atob for bundling) and false negatives (obfuscated or indirect calls).
- Exfiltration and data-flow analysis: Fingerprint exfiltration detection relies on simple API presence and specific network endpoints. Incorporate data-flow/taint analysis (linking fingerprint reads to outbound network calls) and broaden network sink coverage (XHR, fetch, Beacon, postMessage to iframes/service workers) to reduce misclassification.
- Sequence of multi-stage phishing flows: Many kits use multi-phase pages (landing, CAPTCHA/turnstile, credential forms, confirmation). Capture and analyze multi-step sequences (including redirects and click-through) to understand stage-specific API usage and cloaking.
- Cross-browser generalizability: Results are Chromium-centric (VisibleV8). Replicate on Firefox, Safari, and mobile browsers to quantify cross-browser differences in API behavior, permissions, and cloaking outcomes.
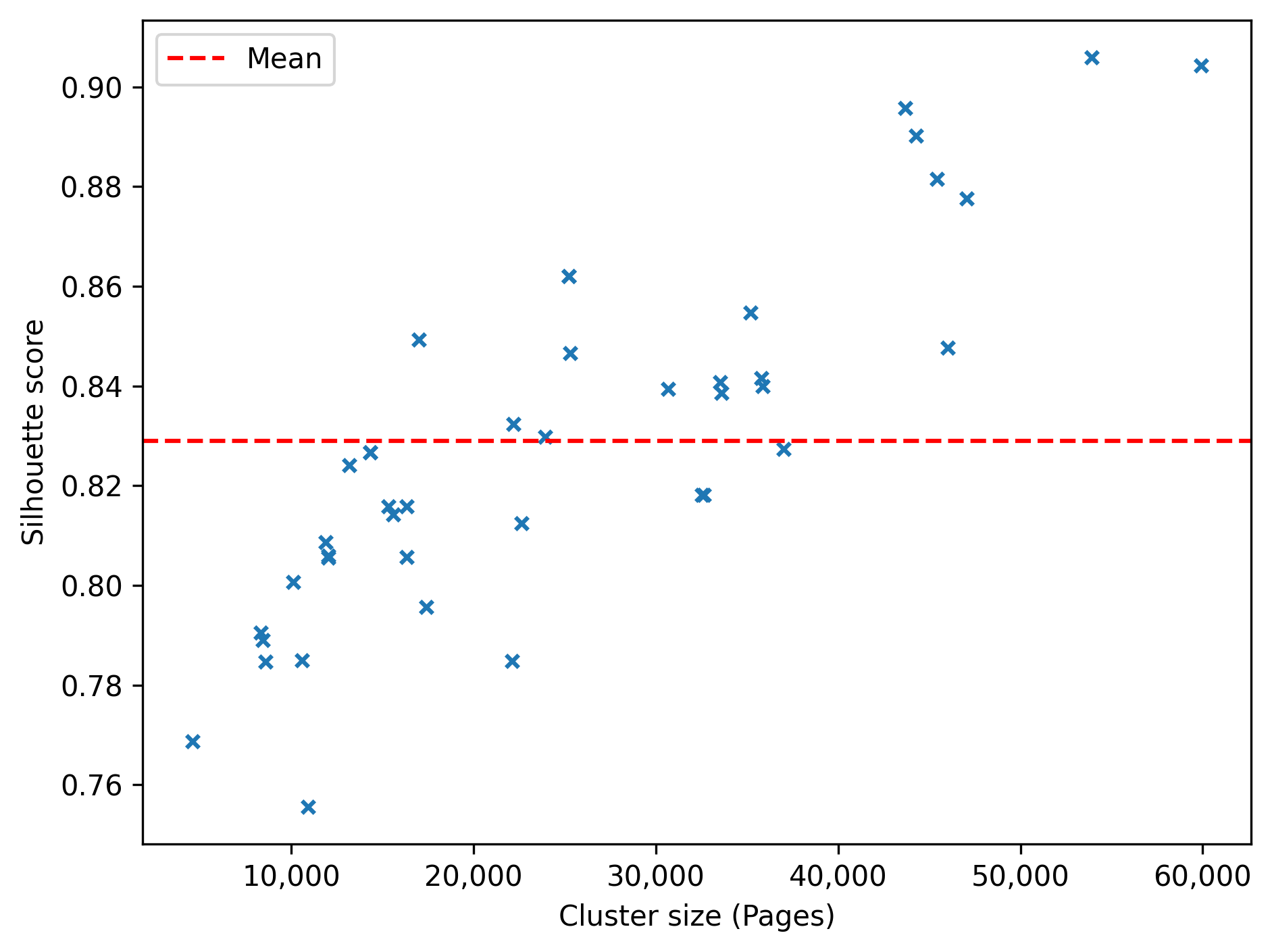
- Visualization and internal validation metrics: t-SNE is only illustrative; silhouette is biased for non-convex clusters. Compare density-specific internal validation metrics (e.g., DBCV, cluster stability from HDBSCAN) and assess consistency across parameterizations and subsets.
- Actionability for defenders: The paper stops short of turning clusters into deployable detection rules. Derive cluster-level signatures (e.g., stable API motifs, network sinks, DOM patterns) and evaluate operational performance (precision/recall, latency, evasion resilience) in a live or retrospective detection setting.
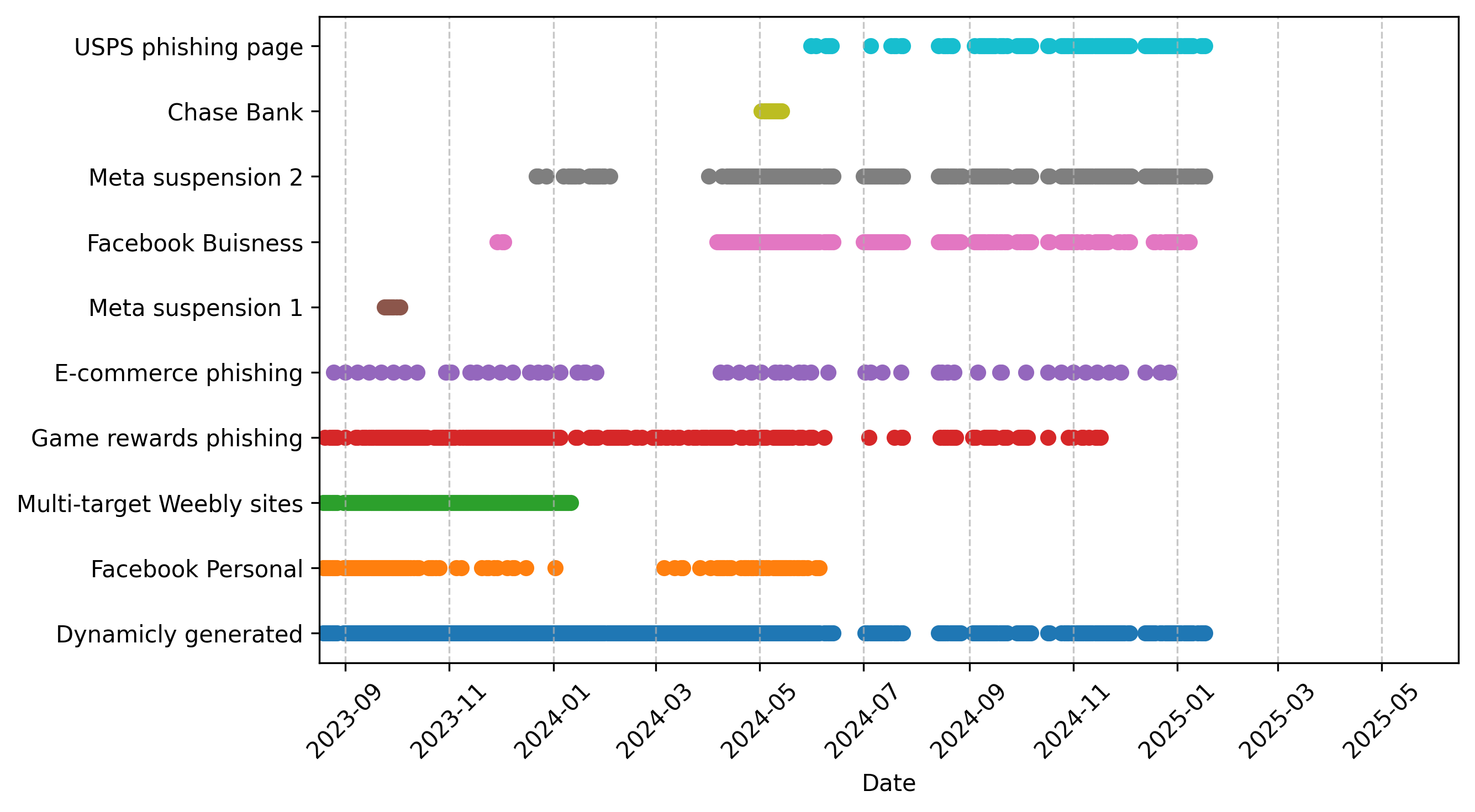
- Temporal evolution and lineage: Cluster lifetimes are reported, but kit evolution (feature drift, branching, family trees) is not analyzed. Build temporal lineage models, detect version changes, and study the dynamics of capability adoption (e.g., turnstile removal/addition, new fingerprinting).
- Brand labeling noise and its impact: Feeds mislabel brands (e.g., Japanese shopping pages tagged as National Police Agency JAPAN). Quantify label noise systematically and explore brand attribution via page content, logos, and visual DOM features to improve analyses tied to target brands.
- Hosting and deployment diversity analysis: e2LD is used to measure deployment diversity, but hosting environments (Cloudflare Pages, Blogger, AWS, DigitalOcean) may influence observed APIs (e.g., injected scripts, CSP). Characterize hosting-driven artifacts and their impact on clustering and technique detection.
- Cloudflare Turnstile detection completeness: Relying on Window.turnstile may miss self-hosted copies or obfuscated integrations. Expand detection using DOM widget signatures, network call patterns to known endpoints, and challenge workflows to avoid undercounting.
- Mouse-detection rarity not explained: Mouse detection APIs appear in few clusters. Investigate whether this rarity is due to kit age, browser policy changes, detection risk, or replacement by other detection mechanisms; correlate with campaign dates and outcomes.
- Ethical and operational safeguards: Crawling live phishing raises questions about triggering exfiltration and victim harm. Document and evaluate safeguards (e.g., fake credentials, network isolation, DMCA/abuse reporting), and measure whether any analysis inadvertently facilitated attacker infrastructure.
- Dataset and code release for reproducibility: The paper does not specify public release of code, traces, or cluster annotations. Provide artifacts (with appropriate redactions) and detailed instructions to reproduce clustering, technique mapping, and validations.
- Multi-modal integration: API-based dynamic features are powerful, but integrating static code features, DOM structures, visual similarity, URL-chain patterns, and server-side signals could increase fidelity. Explore multi-modal clustering and feature fusion.
- Threshold choices and malformed clusters: Choices like minimum distinct APIs (4 or 8) and removal of clusters with <4 APIs in common affect coverage. Perform sensitivity analyses on thresholds, quantify what phenomena are lost, and propose adaptive criteria based on stability or confidence.
- Feature importance and contribution analysis: The claim that DOM APIs and property reads are valuable is qualitative. Quantify feature importance (e.g., ablation, SHAP-like analyses for unsupervised settings) to identify core signals that best differentiate kits.
- Mapping clusters to known kits at scale: Only 313 clusters could be tied to kits via KitPhishr occurrences in the unlabeled set. Develop automated attribution methods (e.g., fuzzy matching to known kit fingerprints, code similarity in recovered partial archives) to identify kit families across the larger corpus.
- Redirect-chain analysis: Phishing frequently uses shorteners and intermediate pages. Analyze full redirect chains and intermediate DOM/API behaviors to understand cloaking layers and identify kits that hide landing-page logic behind benign intermediates.
- Parameter-level behavior tracking: Current signals ignore parameters (e.g., endpoint URLs, header values, request bodies). Incorporate parameter semantics (e.g., calls to specific IP reputation APIs, exfil endpoints, CDN tags) into feature sets to improve interpretability and detection.
Collections
Sign up for free to add this paper to one or more collections.