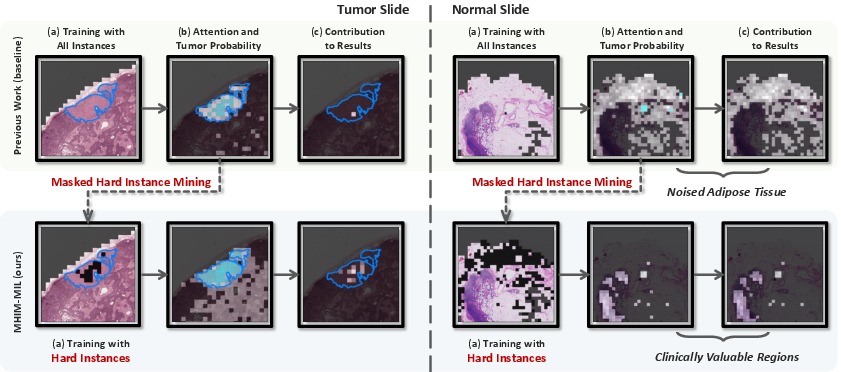
- The paper presents a teacher-student MIL framework that mines hard instances by masking easy ones to enhance discriminative learning.
- It leverages class-aware instance probabilities and dual masking strategies to effectively target challenging regions in gigapixel WSIs.
- Empirical results across cancer diagnosis, subtyping, and survival analysis demonstrate improved AUC, F1-score, and computational efficiency.
Multiple Instance Learning with Masked Hard Instance Mining for Gigapixel Histopathology Image Analysis
Introduction and Motivation
The analysis of gigapixel whole slide images (WSIs) in computational pathology (CPath) is fundamentally constrained by the scale of the data and the lack of fine-grained annotations. Multiple Instance Learning (MIL) has become the dominant paradigm, treating each WSI as a bag of thousands of unlabeled instances (patches), with only bag-level labels available. However, conventional attention-based MIL methods are biased toward easy-to-classify, highly salient instances, neglecting hard instances that are critical for learning robust and discriminative models. This bias leads to suboptimal generalization, especially in the presence of class imbalance and noisy backgrounds typical of histopathology.
The paper introduces MHIM-MIL, a novel MIL framework that systematically mines hard instances by masking out easy ones, leveraging a momentum teacher-student architecture, class-aware instance probability, and a global recycle network (GRN) to recover potentially lost key features. The approach is validated across cancer diagnosis, subtyping, and survival analysis tasks, demonstrating consistent improvements over state-of-the-art (SOTA) baselines in both performance and computational efficiency.
Methodology
Masked Hard Instance Mining (MHIM)
The core innovation is the masked hard instance mining strategy, which operates as follows:
- Momentum Teacher-Student Framework: A Siamese architecture is used, where the teacher model (updated via exponential moving average, EMA) evaluates all instances in a bag to estimate their class-aware probabilities. The student model is trained on hard instances mined by the teacher.
- Class-Aware Instance Probability: Instead of relying on class-agnostic attention scores, the teacher computes class-aware probabilities for each instance, providing a more accurate assessment of instance difficulty. This is achieved by passing attention-weighted features through an instance classifier (or the bag classifier if unavailable).
- Randomly High Score Masking (RHSM): The top βh% of easy instances (highest class-aware probabilities) are masked out. To avoid error masking (i.e., masking all informative regions), a decaying mask ratio and random selection within the top candidates are used.
- Large-Scale Random Score Masking (RSM): To further reduce redundancy and increase diversity, a large proportion (70%−90%) of the remaining instances are randomly masked, producing a compact, diverse set of hard instances for training.
- Global Recycle Network (GRN): To mitigate the risk of losing critical features due to aggressive masking, a GRN recovers key features from the masked-out instances using multi-head cross-attention with global queries updated via EMA.
- Consistency Loss: The student is trained with a combination of cross-entropy loss and a consistency loss that aligns its bag embedding (from hard instances) with the teacher's embedding (from all instances), facilitating stable and effective knowledge transfer.
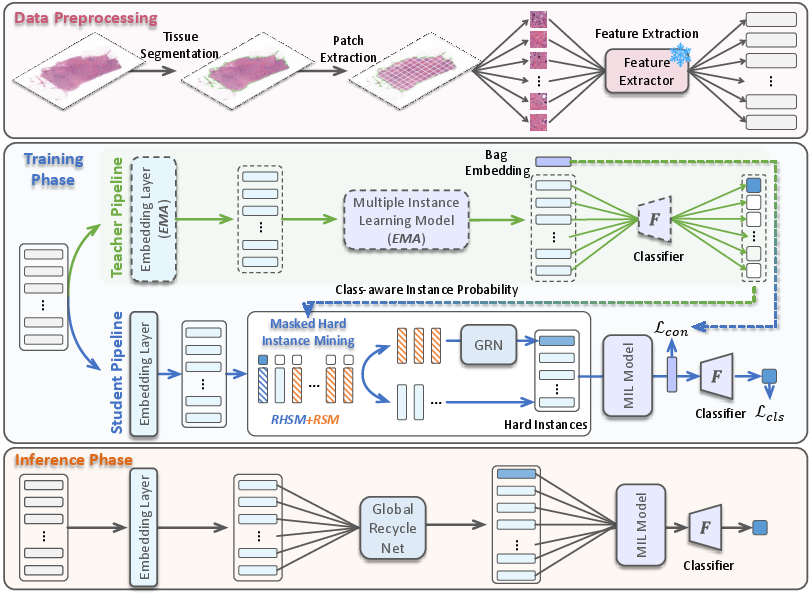
Figure 1: Overview of the MHIM-MIL framework, illustrating the teacher-student architecture, masking strategies, GRN, and loss functions.
Implementation Details
- Feature Extraction: Patches are extracted from WSIs and encoded using pre-trained models (ResNet-50, PLIP, UNI).
- Optimization: The teacher is updated via EMA; the student is optimized with Adam and a combination of supervised and consistency losses.
- Inference: Only the student model is used, with the full set of instances and GRN-recovered features.
Empirical Results
MHIM-MIL and its improved version (MHIM-v2) are evaluated on multiple datasets (CAMELYON, TCGA-NSCLC, TCGA-BRCA, TCGA-LUAD, TCGA-LUSC, TCGA-BLCA) for cancer diagnosis, subtyping, and survival analysis. Across all tasks and feature extractors, MHIM-v2 consistently outperforms SOTA baselines (AB-MIL, DSMIL, TransMIL, DTFD-MIL, R2T-MIL, 2DMamba), with notable improvements in AUC, F1-score, and C-index.
Ablation and Analysis
- Class-Aware Instance Probability: Outperforms attention-based mining, especially for complex models like TransMIL, with up to 1.1% AUC improvement.
- Masking Strategies: RSM provides better performance and lower memory usage than low-score masking (LSM), and the GRN recovers performance lost due to aggressive masking.
- Teacher Initialization and EMA: Momentum-based teachers initialized from pre-trained baselines yield the most stable and performant hard instance mining.
- Hyperparameter Robustness: The framework is robust to masking ratios and scaling factors, with different baselines exhibiting varying sensitivity.

Figure 3: Illustration of various hard instance mining methods, including RHSM and RSM.
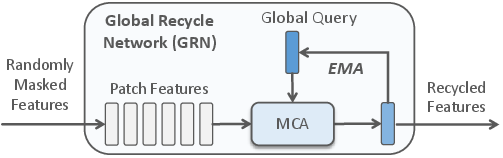
Figure 4: Illustration of the Global Recycle Network, which recovers key features from masked-out instances.
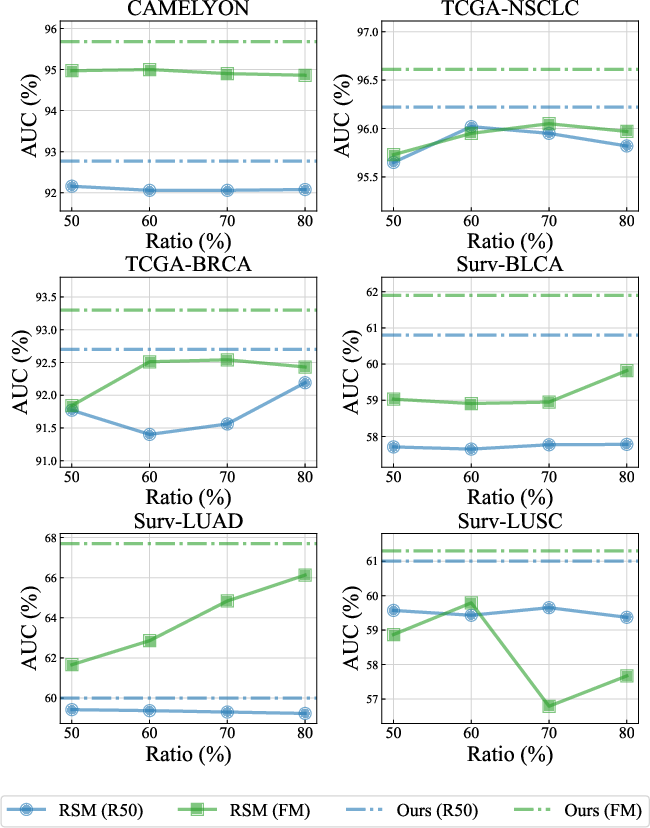
Figure 5: Performance comparison between simple random masking and the full MHIM-v2 framework, demonstrating the necessity of guided hard instance mining.
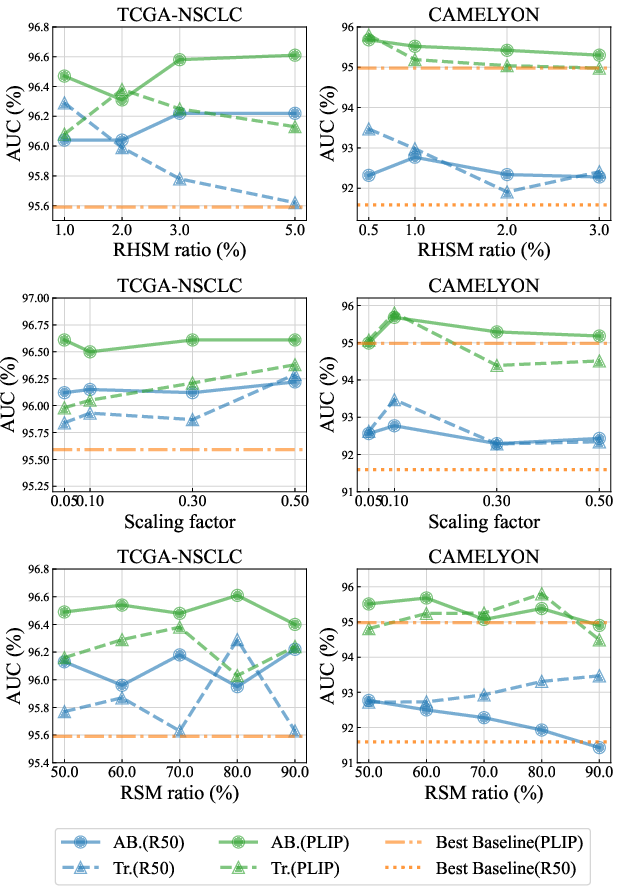
Figure 6: MHIM-v2 performance under different hyperparameter settings, showing stability across a range of values.
Qualitative Visualization
- Attention and Probability Maps: MHIM-v2 corrects the attention bias of baselines, focusing on clinically relevant regions and reducing false positives in non-tumor areas.
- Training Dynamics: The discriminability of the teacher model improves over training, and class-aware probabilities provide more accurate and uniform assessments than attention scores.

Figure 7: Patch visualization produced by baselines and MHIM-v2 on CAMELYON, showing improved alignment with tumor regions.
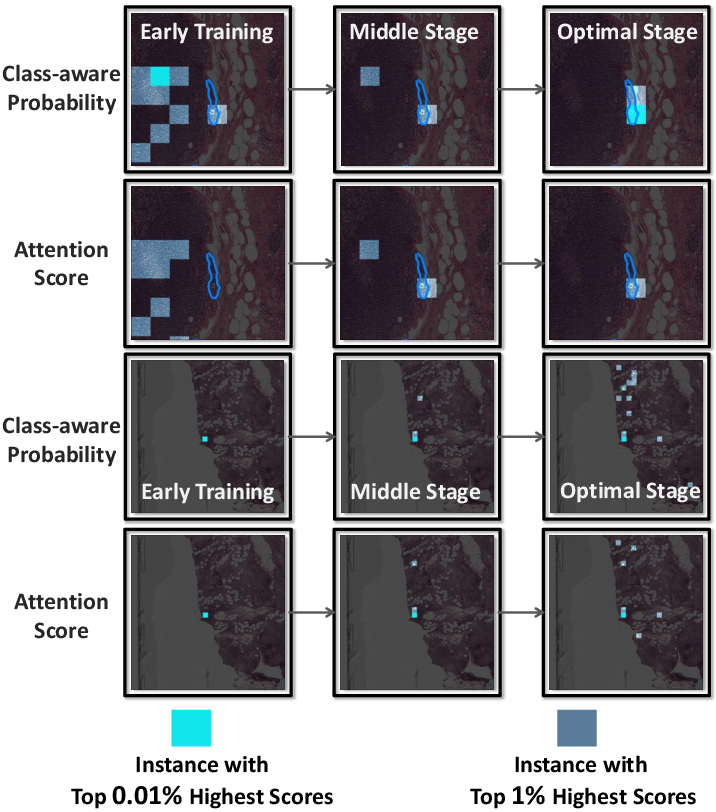
Figure 8: Visualization of easy-to-classify instances during training, highlighting the superiority of class-aware instance probability.
Practical and Theoretical Implications
Practical Implications
- Scalability: The masking strategies and GRN enable efficient training on gigapixel WSIs, making advanced MIL models feasible for large-scale clinical deployment.
- Generalizability: The framework is agnostic to the choice of feature extractor and MIL backbone, and demonstrates strong cross-source transferability (e.g., TCGA to CPTAC).
- Robustness: By focusing on hard instances and recovering lost features, MHIM-MIL is more robust to noise and class imbalance, critical for real-world pathology.
Theoretical Implications
- Instance Mining in Weak Supervision: The work formalizes hard instance mining in the absence of instance-level labels, leveraging self-supervised consistency and momentum distillation.
- Attention vs. Probability: The distinction between attention-based and class-aware probability-based mining is empirically validated, with the latter providing superior discriminative power.
- Iterative Optimization: The teacher-student EMA loop enables stable, progressive mining of increasingly informative hard instances.
Future Directions
- Integration with Multimodal Data: While the current framework is unimodal, extending MHIM-MIL to incorporate genomics, radiology, or clinical text could further improve performance and robustness.
- Adaptive Masking Policies: Learning dynamic masking ratios or instance selection policies conditioned on bag-level uncertainty or task difficulty may yield further gains.
- End-to-End Feature Learning: Jointly optimizing the feature extractor and MIL model within the MHIM-MIL framework could close the gap with multimodal and fully supervised approaches.
Conclusion
MHIM-MIL addresses a critical limitation of attention-based MIL in computational pathology by systematically mining hard instances through masking and recycling strategies, guided by a momentum teacher-student architecture and class-aware instance probabilities. The framework achieves SOTA performance across diverse CPath tasks and datasets, with improved efficiency and robustness. Theoretical and empirical analyses support the superiority of hard instance mining over conventional salient instance selection, and the approach is broadly applicable to other weakly supervised learning scenarios involving large, imbalanced, and noisy data.