- The paper introduces ButterflyQuant, a method that leverages learnable orthogonal butterfly transforms to perform ultra-low-bit quantization of large language models.
- It employs a hierarchical composition of continuous Givens rotations to address layer-specific heterogeneity, reducing perplexity from 22.1 to 15.4 on the LLaMA-2-7B model.
- Empirical results show the method retains about 88% of full-precision model accuracy on reasoning tasks, facilitating LLM deployment on consumer-grade hardware.
Introduction
In "ButterflyQuant: Ultra-low-bit LLM Quantization through Learnable Orthogonal Butterfly Transforms," the authors address the challenge of reducing the memory footprint of LLMs to facilitate their deployment on consumer-grade hardware. The study introduces ButterflyQuant, a method leveraging learnable orthogonal butterfly transforms to perform ultra-low-bit quantization while mitigating performance degradation commonly associated with extreme quantization levels.
Challenges in LLM Quantization
LLMs typically demand significant memory resources, limiting their deployment on consumer hardware. Standard quantization techniques that aim to reduce numerical precision to 2-4 bits encounter severe performance loss, primarily attributed to the presence of outliers in activations. These outliers skew the dynamic range and impair low-bit compression. To counter this, rotation-based quantization methods have been devised, which apply orthogonal transforms to the activations before quantization.
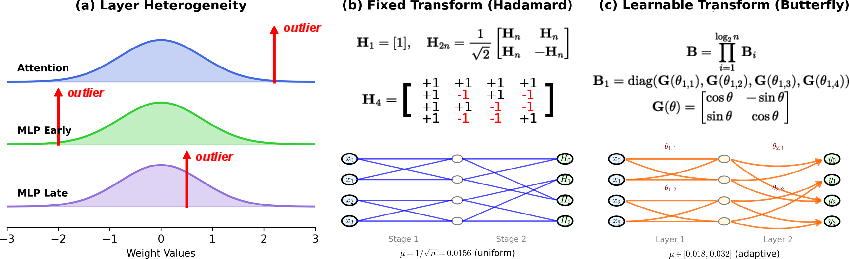
Figure 1: Layer heterogeneity motivates learnable transforms for LLM quantization.
The paper identifies the heterogeneity across transformer layers—each exhibiting distinct outlier characteristics—as a critical issue. This layer-specific variability suggests that a one-size-fits-all transformation approach is suboptimal.
ButterflyQuant Approach
ButterflyQuant replaces fixed Hadamard rotations with learnable butterfly transforms, leveraging the flexibility of continuous Givens rotation angles for gradient-based optimization. Unlike Hadamard's discrete entries, the continuous nature of butterfly transforms allows them to adapt to the unique outlier distances of each layer while ensuring orthogonality, a crucial property for maintaining theoretical guarantees in outlier suppression.
Implementation Details
The butterfly transform is parameterized to enforce orthogonality and expressiveness while maintaining efficient O(nlogn) complexity. This is achieved through a composition of Givens rotations, creating a sparse, hierarchical structure ideal for adaptation through gradient descent.
Rotation-based quantization methods such as QuaRot and QuIP apply predetermined orthogonal transforms to redistribute outliers across channels. In contrast, butterfly transforms are distinct in their ability to learn layer-specific adaptations while retaining computational efficiency and orthogonality.
Empirically, ButterflyQuant successfully reduces models to a 2-bit quantization level, achieving significantly lower perplexity scores than competing state-of-the-art methods, which demonstrates its efficacy. For example, on the LLaMA-2-7B model, it reduces perplexity from 22.1 with QuaRot to 15.4. Additionally, it maintains approximately 88% of the full precision model's accuracy on various reasoning tasks.
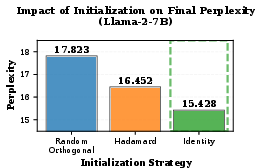
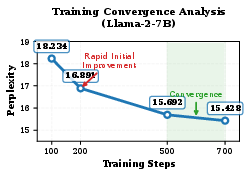
Figure 2: Impact of initialization strategy on final perplexity.
The adaptability provided by learnable transforms allows ButterflyQuant to achieve superior performance, highlighting the importance of continuous parameterization in addressing layer heterogeneity.
Conclusion
ButterflyQuant presents a significant advancement in the quantization of LLMs. By introducing learnable orthogonal butterfly transforms, it addresses the limitations of fixed rotation strategies, offering an effective balance between theoretical guarantees and practical implementation efficiency. This methodology's ability to perform extreme compression with minimal performance loss opens pathways for more accessible deployment of complex models across a broader range of hardware. Future research may further explore extensions of this technique to more diverse architectures and its applications within other domains of AI model compression.

