- The paper introduces GDCN with an SGDF module that robustly fuses multi-view embeddings even with noisy or missing data.
- It employs dedicated autoencoders and contrastive learning to align view-specific and common representations effectively.
- Empirical results show state-of-the-art clustering performance, improving accuracy by up to 7.8 percentage points on benchmark datasets.
Generative Diffusion Contrastive Network for Multi-View Clustering
Introduction
The paper introduces the Generative Diffusion Contrastive Network (GDCN), a novel architecture for Multi-View Clustering (MVC) that addresses the persistent challenge of low-quality data in multi-view fusion. The proposed solution leverages a Stochastic Generative Diffusion Fusion (SGDF) mechanism, which is robust to both noisy and missing data across views. GDCN integrates three core modules: an autoencoder for view-specific representation learning, the SGDF module for robust feature fusion, and a contrastive learning module for common representation alignment. The framework demonstrates superior clustering performance across multiple public datasets, outperforming existing deep MVC methods in terms of accuracy, normalized mutual information, and purity.
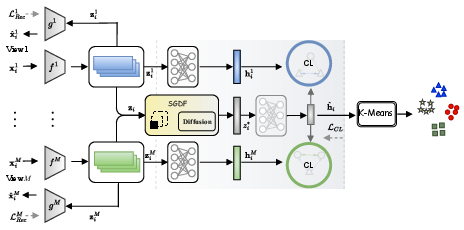
Figure 1: The GDCN framework, comprising the Autoencoder, SGDF, and Contrastive Learning modules, with K-Means for clustering.
Methodology
Autoencoder Module
Each view of the multi-view data is processed by a dedicated autoencoder, which consists of an encoder fm and a decoder gm. The encoder maps the input xim to a low-dimensional embedding zim, while the decoder reconstructs the original input from zim. The reconstruction loss LRec is minimized during pre-training to ensure that the learned representations retain essential information from each view.
Stochastic Generative Diffusion Fusion (SGDF)
SGDF is the central innovation of the paper. It fuses multi-view features by generating multiple samples via a diffusion model conditioned on the concatenated view-specific embeddings. The reverse diffusion process iteratively denoises a set of initial noise vectors, using a multi-layer perceptron (MLP) as the denoising function. The process is accelerated by discretizing the time steps and averaging the generated vectors to obtain a robust fused feature zi∗. This approach mitigates the impact of noisy or missing data by leveraging the generative capacity of diffusion models, which have demonstrated strong denoising and imputation capabilities in other domains.
Contrastive Learning Module
The contrastive learning module aligns the fused representation zi∗ with the view-specific representations zim using a contrastive loss LCL. This encourages consistency across views and enhances the discriminative power of the common representation. The final clustering is performed using K-Means on the learned common representations.
Experimental Results
GDCN is evaluated on four benchmark multi-view datasets: NGs, Synthetic3d, Caltech5V, and Wikipedia. The results indicate that GDCN achieves state-of-the-art performance, with substantial improvements over previous methods in all metrics. For example, on the NGs dataset, GDCN surpasses the second-best method by 7.8 percentage points in accuracy. Ablation studies confirm the critical role of both SGDF and contrastive learning modules; removing either leads to significant drops in clustering performance.
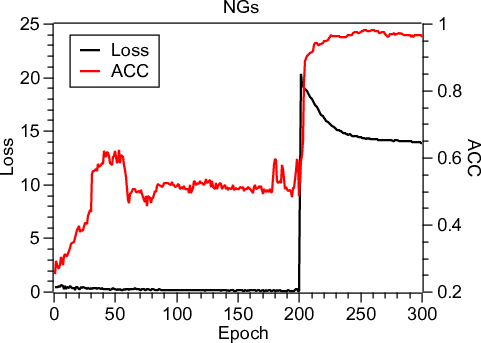
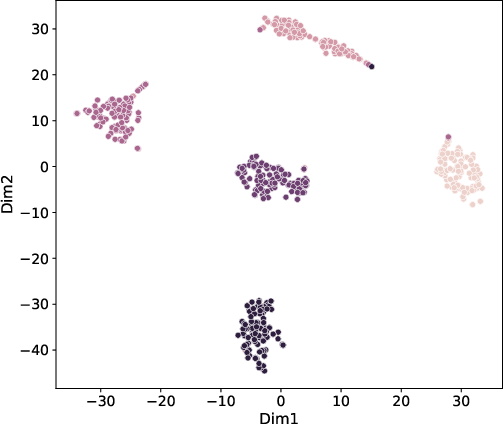
Figure 2: Convergence analysis and t-SNE visualization of common representations on NGs, showing clear cluster boundaries and stable training dynamics.
Hyper-parameter analysis reveals that the clustering performance is relatively insensitive to the number of diffusion sampling times (B) and discrete points (K), indicating robustness to these choices.
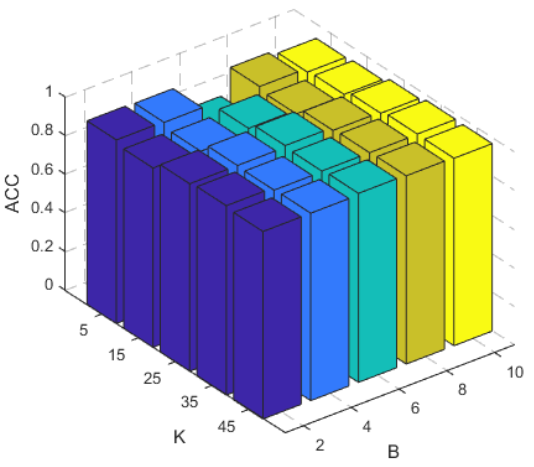
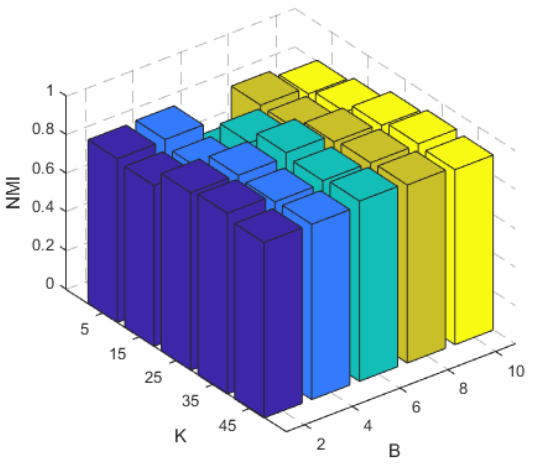
Figure 3: Hyper-parameter analysis on NGs, demonstrating stability of ACC and NMI across varying B and K.
Implementation Considerations
- Computational Requirements: The SGDF module introduces additional computational overhead due to multiple diffusion sampling and iterative denoising. Efficient implementation of the MLP denoiser and parallelization of the sampling process are recommended for scalability.
- Robustness: The generative nature of SGDF provides resilience to missing and noisy data, making GDCN suitable for real-world multi-view scenarios where data quality is heterogeneous.
- Deployment: The modular design allows for flexible integration with existing MVC pipelines. The use of K-Means for clustering ensures compatibility with standard unsupervised learning workflows.
- Parameter Selection: The insensitivity to B and K simplifies hyper-parameter tuning, facilitating practical deployment.
Theoretical and Practical Implications
The introduction of diffusion models into multi-view clustering represents a significant methodological advance, bridging generative modeling and representation learning. SGDF's robustness to low-quality data addresses a key limitation of prior fusion strategies (e.g., summation, concatenation, attention), which are often brittle in the presence of noise or missing views. The contrastive learning module further enhances the alignment and consistency of representations, a critical factor in MVC.
The strong empirical results suggest that generative diffusion-based fusion can be generalized to other multi-modal and multi-source learning tasks. Future work may explore the integration of more sophisticated diffusion architectures, adaptive sampling strategies, and the extension to incomplete or semi-supervised clustering settings.
Conclusion
GDCN establishes a new benchmark for deep multi-view clustering by combining autoencoder-based representation learning, robust generative diffusion fusion, and contrastive alignment. The SGDF module is particularly effective in mitigating the adverse effects of low-quality data, and the overall framework demonstrates superior clustering performance across diverse datasets. The approach is computationally tractable, robust to hyper-parameter choices, and readily adaptable to practical multi-view learning scenarios. Future research may extend these concepts to broader multi-modal fusion and clustering applications.