- The paper presents Delayed Streams Modeling (DSM) that enables streaming sequence-to-sequence learning through explicit delay conditioning for precise latency control.
- The framework achieves state-of-the-art results in ASR with a 6.4% WER on OpenASR and supports efficient, batched processing for arbitrary-length sequences.
- DSM unifies ASR and TTS tasks using a decoder-only Transformer architecture, facilitating real-time, multimodal streaming with scalable throughput.
Delayed Streams Modeling for Streaming Sequence-to-Sequence Learning
Streaming sequence-to-sequence (seq2seq) learning is essential for real-time applications such as ASR, TTS, and simultaneous translation. Traditional offline seq2seq models, including encoder-decoder and decoder-only Transformers, require the entire input sequence before generating outputs, which precludes real-time inference and limits input length. Existing streaming approaches, such as Transducers and monotonic attention, introduce policy learning for alignment, but this complicates batching and increases training complexity.
The Delayed Streams Modeling (DSM) framework addresses these limitations by assuming pre-aligned, time-synchronized input and output streams, enabling a decoder-only model to process multiple modalities in a streaming, batched, and autoregressive fashion. The key innovation is the introduction of a configurable delay between streams, which allows explicit control over the latency-quality trade-off and supports streaming inference for arbitrary-length sequences.
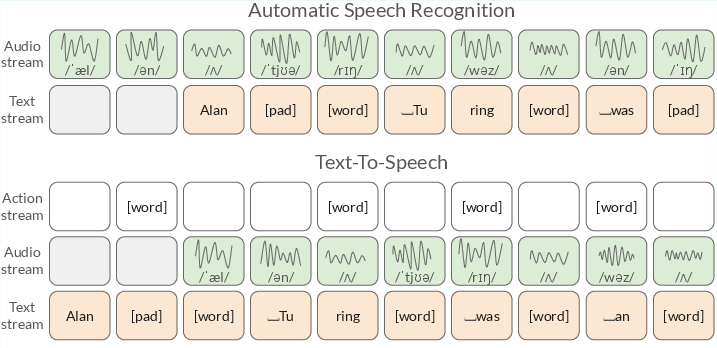
Figure 1: Delayed streams modeling for speech-text tasks. Depending on which stream is delayed with respect to the other, we solve either an ASR or a TTS task. For TTS, an action stream signals readiness for new word input.
DSM Framework and Architecture
DSM models the joint distribution over aligned input and output streams, e.g., audio and text, by discretizing both modalities to a shared frame rate. The model operates autoregressively, predicting the next output token conditioned on the current and past input tokens and past output tokens, with a fixed or variable delay τ between streams to ensure causality and prevent information leakage from the future.
The architecture consists of:
- Backbone: A decoder-only Transformer processes the sum of input and output token embeddings at each time step.
- Input Embedders: Separate learned embeddings for each modality, summed before entering the backbone.
- Sampler: For discrete outputs, a linear layer produces logits; for continuous outputs, a flow or diffusion model can be used.
- Delay Conditioning: The model can be conditioned on the delay value, enabling inference-time control of the latency/quality trade-off without retraining.
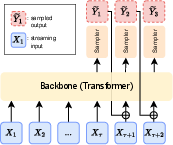
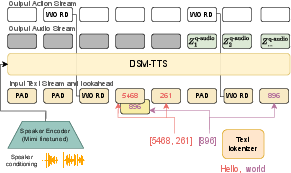
Figure 2: DSM Architecture. The Transformer backbone receives streaming input Xt; after a delay τ, the sampler generates Yt. At the next step, the backbone receives both the sampled value and the next streaming input, with their embeddings summed.
For TTS, an additional action stream is introduced to signal when the model is ready to receive a new word, and a lookahead text stream provides future word tokens to improve prosody and pause prediction.
Speech-Text Representations and Alignment
DSM leverages neural codecs (e.g., Mimi) to discretize audio into RVQ tokens at a fixed frame rate (e.g., 12.5 Hz), and aligns text tokens to the same grid using word-level timestamps. Special tokens ({PAD}, {WORD}) are used to indicate word boundaries and padding. This alignment enables synchronous, batched processing and precise timestamp prediction.
For ASR, the model predicts text tokens from audio tokens, learning to transcribe and timestamp words with high temporal precision. For TTS, the model generates audio tokens from text, conditioned on speaker embeddings and dialog turn tokens for multi-speaker scenarios.
Training and Inference Protocols
DSM models are pretrained on large-scale pseudo-labeled data (e.g., Whisper-timestamped transcriptions) and finetuned on public datasets with ground-truth transcripts. For ASR, delay conditioning is implemented by sampling delays per sequence and adding a cosine embedding of the delay to the input. For TTS, classifier-free guidance is used for both speaker and text conditioning, and the model is finetuned to support different guidance strengths.
The architecture is highly scalable: the ASR backbone uses 2.6B parameters, while the TTS backbone uses 1B parameters, with additional parameters for the RVQ sampler. Training is performed on up to 48 H100 GPUs, with batch sizes up to 128.
Empirical Results
Automatic Speech Recognition
DSM-ASR achieves WER of 6.4% on the OpenASR leaderboard, outperforming all streaming baselines and matching the best non-streaming models. Notably, it is the only streaming model among the top systems. On long-form datasets (up to 2 hours), DSM-ASR outperforms both streaming and most non-streaming baselines, with robust performance across diverse domains.
Delay conditioning enables precise control of latency, with the model achieving sub-second delays and maintaining high throughput. DSM-ASR supports batching of up to 400 sequences in real time, with throughput independent of delay, in contrast to Whisper-Streaming, which suffers a 100x throughput penalty due to lack of batching.
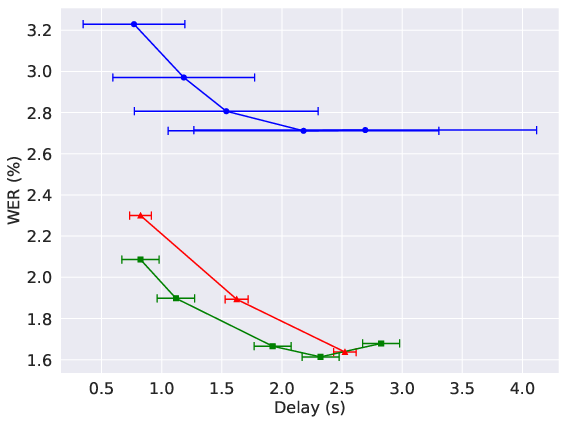
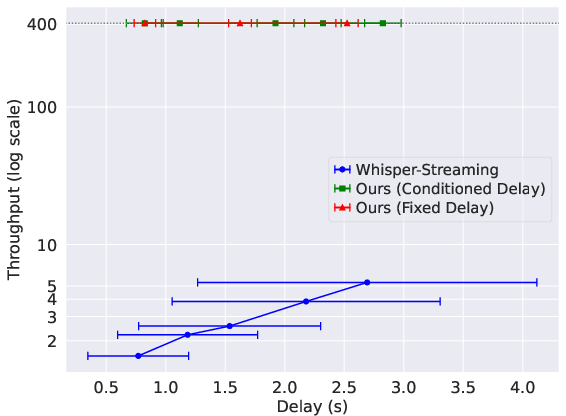
Figure 3: ASR WER (left) and throughput (right) as a function of delay. DSM-ASR achieves lower WER and higher, delay-independent throughput compared to Whisper-Streaming.
Text-to-Speech
DSM-TTS achieves the lowest WER for both English and French, in monologue and dialog settings, and is the only model supporting long-form, multi-speaker, streaming synthesis. Speaker similarity metrics are superior to open-source and commercial baselines, especially in turn-by-turn dialog generation. Subjective evaluations (MUSHRA and Elo scores) confirm high speech quality and speaker similarity, with performance competitive with or surpassing commercial systems.
DSM-TTS is highly efficient, with real-time factors exceeding 2.0 and throughput scaling linearly with batch size. Latency remains below 400 ms even for large batches, supporting real-time, high-volume deployment.
Theoretical and Practical Implications
DSM demonstrates that pre-aligned, delayed stream modeling with decoder-only Transformers can unify streaming seq2seq learning across modalities, eliminating the need for policy learning, non-standard attention, or modality-specific encoders. The approach enables:
- Streaming inference with arbitrary sequence length and precise latency control.
- Batching and high throughput for real-time applications.
- Bidirectional modeling (ASR and TTS) with a single architecture.
- Fine-grained timestamp prediction for ASR and controllable dialog synthesis for TTS.
The main limitation is the requirement for time-aligned data, which may restrict the use of some gold-standard datasets. However, the framework is extensible to other modalities (e.g., vision, translation) and tasks where alignment can be established.
Future Directions
Potential extensions include:
- Generalization to more modalities (e.g., video, multimodal translation).
- Relaxing the alignment assumption via learned or weakly-supervised alignment.
- Integration with LLMs for end-to-end, multimodal conversational agents.
- Improved watermarking and content verification for responsible deployment, as current watermarking methods are fragile to codec-based resynthesis.
Conclusion
Delayed Streams Modeling provides a principled and practical solution for streaming seq2seq learning, achieving state-of-the-art performance and efficiency in both ASR and TTS. The framework's flexibility, scalability, and empirical results suggest broad applicability to real-time, multimodal AI systems. The explicit control over latency and throughput, combined with the ability to batch and process long sequences, positions DSM as a strong foundation for future research and deployment in streaming AI interfaces.