- The paper presents a novel framework that leverages LLM-derived features integrated with XGBoost, Random Forest, and Linear Regression for rare-event prediction in venture capital.
- The methodology achieves a funding prediction MAPE below 4% and amplifies binary success precision by 9.8× to 11.1× compared to random baselines.
- Feature ablation studies highlight that semantic enrichment via LLMs is critical, while interpretability and error mitigation remain key for refining practical VC predictions.
LLM-powered Feature Engineering and Multi-model Learning for Rare-event Prediction in Venture Capital
Introduction
This paper introduces a machine learning framework for rare-event prediction in the context of venture capital (VC), where the task is to identify startups likely to achieve high-impact outcomes (e.g., IPO, major acquisition) from limited and noisy early-stage data. The approach leverages LLMs for feature engineering and integrates their outputs into a multi-model ensemble, combining XGBoost, Random Forest, and Linear Regression. The framework is designed to maximize predictive precision while maintaining interpretability, a critical requirement in high-stakes investment decision-making.
Methodology
Data and Feature Engineering
The dataset comprises 10,825 startup founders, with 8.5% labeled as successful based on stringent criteria (valuation or acquisition above \$500M, or fundraising above \$500M). The rarity of positive outcomes necessitates a focus on precision over recall. LLMs are employed to extract and synthesize 63 features from unstructured founder and company data, including nuanced variables such as skill relevance and domain expertise, which are not easily captured by traditional pipelines.
Categorical features (e.g., education level, domain expertise) are integer-encoded, while textual data (startup descriptions) are embedded using state-of-the-art LLM-based models. Continuous features are standardized via Z-scores to facilitate robust learning in gradient-based models.
Multi-model Architecture
The architecture consists of a first layer with XGBoost and Random Forest models, each processing the engineered features and text embeddings. Their outputs, along with the embeddings, are fed into a Linear Regression meta-model that predicts continuous funding outcomes. This prediction is then thresholded via logistic regression to yield a binary success prediction.
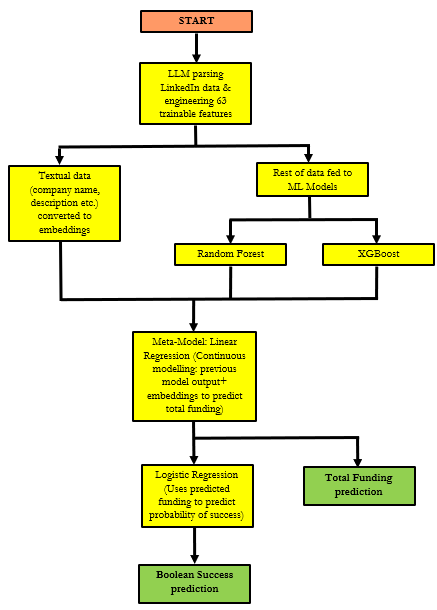
Figure 1: Multi-model architecture integrating LLM-derived features, XGBoost, Random Forest, and a Linear Regression meta-model for rare-event prediction.
The ensemble design exploits the complementary strengths of XGBoost (handling high-dimensional, multi-category data) and Random Forest (robustness and interpretability), while the meta-model refines predictions and supports feature sensitivity analysis.
Results
Funding and Success Prediction
The model achieves a mean absolute percentage error (MAPE) below 4% for funding prediction across all test subsets, indicating high accuracy even in the presence of noisy early-stage data. For binary success prediction, the model attains precision between 9.8× and 11.1× the random classifier baseline across three independent test subsets, with recall consistently above 30%. The classification threshold is tuned to 0.8 to maximize precision without overfitting.
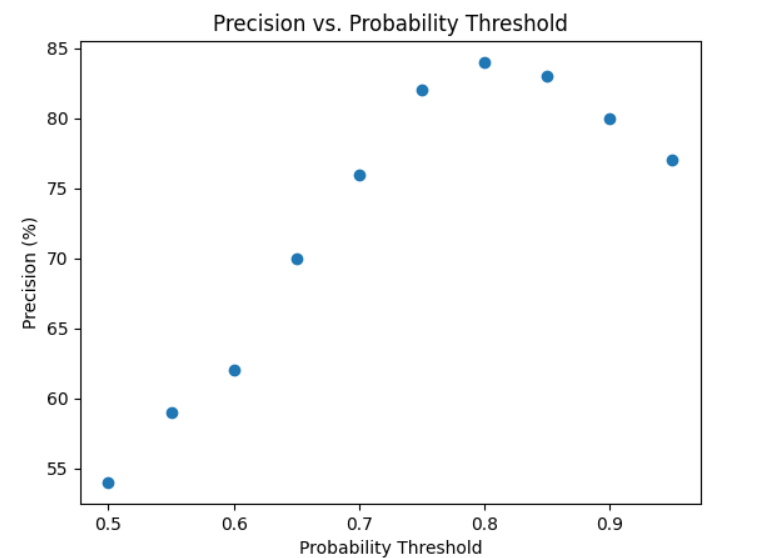
Figure 2: Precision as a function of the threshold probability, demonstrating stable high precision in the 0.75–0.85 range.
Segmenting startups by predicted funding class reveals a monotonic increase in success probability, with the highest funding class ($1B+) achieving 100% observed success, further validating the model's discriminative power.
Feature Sensitivity and Interpretability
Feature importance analysis shows that the startup's category list and the number of founders are the most influential predictors, with category list accounting for 15.6% of the total predictive weight. Education level and domain expertise, while present in the top ten, contribute substantially less.
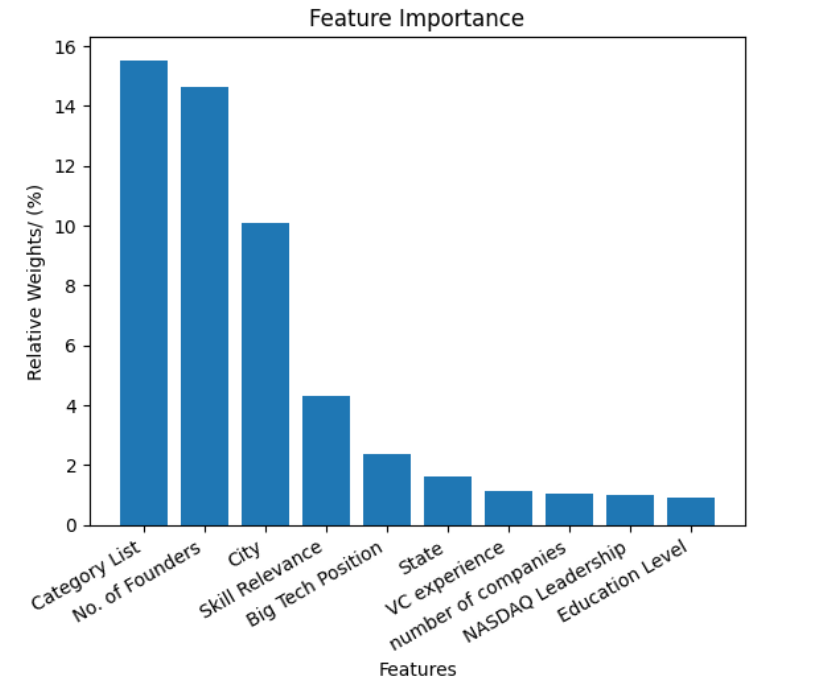
Figure 3: Relative importance of each feature in predicting startup success, highlighting the dominance of category list and number of founders.
Ablation Studies
Ablation experiments demonstrate that removing LLM-engineered features reduces precision from 10.4× to 4.6×, underscoring the critical role of semantic information captured by LLMs. Similarly, categorical features—many of which are LLM-derived—are the most impactful; their removal leads to the largest performance drop among all feature types. Among embedding models, LLM-based embeddings (text-embedding-ada-002) yield the highest precision, but MiniLM remains competitive.
Component-wise ablation reveals that XGBoost is indispensable for handling the high-dimensional feature space, with its removal causing the largest decline in performance. Replacing the Linear Regression meta-model with a shallow neural network increases precision and recall but introduces overfitting and instability in feature attribution.
Implications and Future Directions
The results demonstrate that integrating LLM-powered feature engineering with a multi-model ensemble can deliver high-precision, interpretable predictions in rare-event settings such as VC. The approach is robust to noisy, limited data and provides actionable insights into the drivers of startup success. The strong performance of LLM-derived features suggests that semantic enrichment of structured data is a promising direction for other domains characterized by sparse or unstructured information.
However, the reliance on LLMs introduces risks related to feature misclassification and potential hallucinations, especially for subjective variables. The layered architecture, while effective, may propagate errors from the funding predictor to the final classification. The model's generalizability is also constrained by the quality and representativeness of the underlying data, which may be biased toward founders with greater online presence.
Future research should focus on refining the ensemble architecture to mitigate error propagation, developing methods to validate and augment LLM-derived features (e.g., via SHAP-based explanations), and addressing LLM hallucination. Expanding the framework to other rare-event prediction domains and integrating additional data sources could further enhance its applicability and robustness.
Conclusion
This work presents a comprehensive framework for rare-event prediction in venture capital, combining LLM-powered feature engineering with a multi-model ensemble to achieve high precision and interpretability. The empirical results highlight the value of semantic feature enrichment and ensemble learning in settings where traditional models struggle. The approach offers a template for applying similar techniques to other domains where rare, high-impact outcomes must be predicted from limited and heterogeneous data.

