- The paper introduces Drivelology, a nuanced form of pragmatically layered nonsense, highlighting significant gaps in LLMs' semantic understanding.
- The paper details the creation of the DrivelHub dataset, featuring over 1,200 curated multilingual examples annotated for diverse rhetorical categories.
- The paper demonstrates that LLM performance varies by language and scale, with models like DeepSeek V3 and Qwen3 excelling in specific tasks.
Drivelology: Evaluating LLMs on Nonsense with Depth
Introduction and Motivation
The paper introduces Drivelology, a linguistic phenomenon defined as "nonsense with depth": utterances that are syntactically coherent but pragmatically paradoxical, emotionally loaded, or rhetorically subversive. Unlike surface-level nonsense or simple tautologies, Drivelology encodes implicit meaning requiring contextual inference, moral reasoning, or emotional interpretation. The authors argue that current LLMs, despite their fluency and emergent reasoning capabilities, consistently fail to grasp the layered semantics of Drivelological text, revealing a representational gap in pragmatic understanding.
DrivelHub Dataset Construction
To systematically evaluate LLMs' ability to interpret Drivelology, the authors construct DrivelHub, a benchmark dataset comprising over 1,200 curated examples in six languages (English, Mandarin, Spanish, French, Japanese, Korean). The annotation process is rigorous, involving multiple rounds of expert review and adjudication to ensure that each sample genuinely reflects Drivelological characteristics. Each entry includes the Drivelology sample, its underlying message, and one or more rhetorical categories: Misdirection, Paradox, Switchbait, Inversion, and Wordplay.
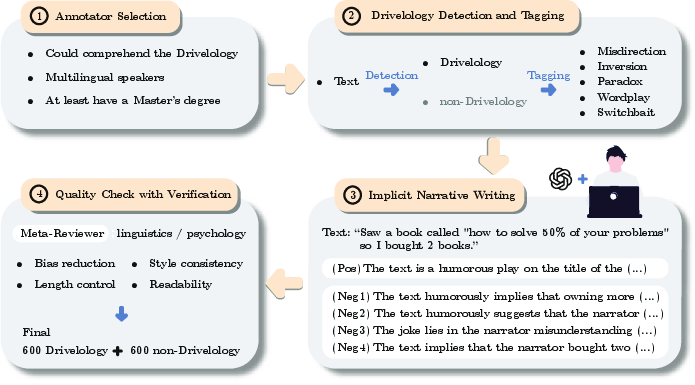
Figure 1: Overview of the multi-stage process for constructing the DrivelHub dataset.
The dataset is designed to support four core evaluation tasks:
Experimental Setup and Evaluation Protocol
The evaluation covers both proprietary and open-source LLMs, including GPT-4, Claude-3, Qwen3, Qwen2.5, Llama3, and DeepSeek V3. All models are tested in a zero-shot setting, with three distinct prompts per task to minimize variance. Metrics include accuracy (Detection, MCQA), weighted F1 (Tagging), BERTScore (Narrative Writing), and LLM-as-a-judge (GPT-4) for qualitative assessment of generated narratives.
Main Results and Analysis
DeepSeek V3 consistently achieves the highest scores across most metrics, notably in Drivelology Detection (81.67%) and Tagging (55.32%). In the Narrative Writing task, BERTScore-recall values are uniformly high (84.67–87.11%), but GPT-4-as-a-judge scores reveal qualitative differences: only DeepSeek V3 (3.59) and Claude-3.5-haiku (3.39) surpass the threshold for high semantic quality, while other models fall below.
The MCQA Hard setting exposes a critical weakness in subtle reasoning, with accuracy dropping sharply for all models. Qwen3-8B-instruct is a notable outlier, achieving 26.78% in the Hard task, far above other models of similar scale.
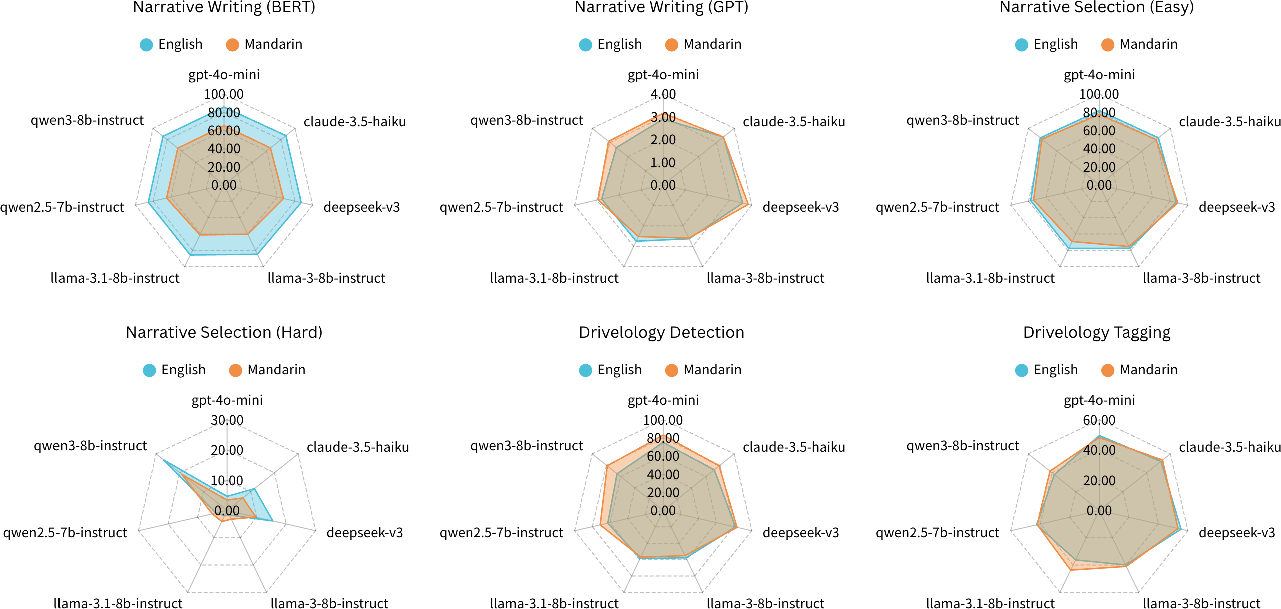
Figure 3: Model performance on the multilingual DrivelHub dataset, contrasted by prompt language (English vs. Mandarin).
Prompt language significantly affects performance. English prompts yield superior results in tasks requiring lexical precision and logical reasoning (e.g., BERTScore, MCQA), while Mandarin prompts confer advantages in direct content comprehension (GPT-as-a-judge, Detection, Tagging).
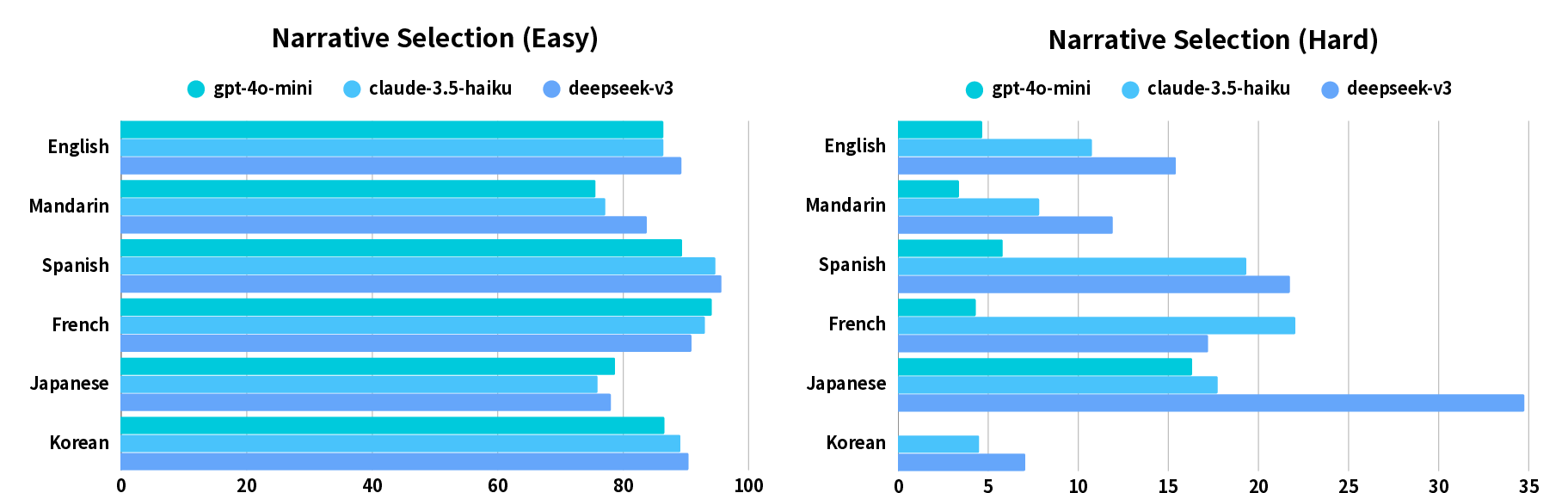
Figure 4: A language-based breakdown of Narrative Selection (MCQA) accuracy, showing cross-lingual performance variations.
Cross-lingual analysis reveals that Korean and Mandarin samples are most challenging for LLMs, especially in the Hard MCQA task. Model scaling experiments with Qwen3 (4B, 8B, 14B) demonstrate that complex reasoning required by the Hard MCQA task is an emergent property unlocked by larger parameter counts, with accuracy increasing from 2.44% (4B, Mandarin) to 47.89% (14B, Mandarin).
Qualitative Reasoning and Human Annotation
The paper provides detailed analysis of model reasoning. For example, DeepSeek V3 and Claude-3.5-haiku exhibit divergent approaches to categorizing culturally embedded Drivelology, with DeepSeek V3 emphasizing explicit cultural context and Claude-3.5-haiku focusing on logical structure. This suggests varying degrees of internalization of cultural knowledge among models.
Human annotators also face challenges, as Drivelology's ambiguity and layered meaning invite multiple plausible readings. Annotation guidelines require consensus and meta-review to ensure reliability, but the inherent subjectivity remains a limiting factor.
Limitations
The dataset is imbalanced, with Mandarin samples comprising nearly half of the data. Computational constraints limit evaluation to models ≤14B parameters and exclude stronger proprietary LLMs. The study focuses on understanding and reasoning rather than generation; preliminary experiments show that LLMs require extensive prompting to produce Drivelology text with comprehensive alignment between topic, rhetorical category, and structure.
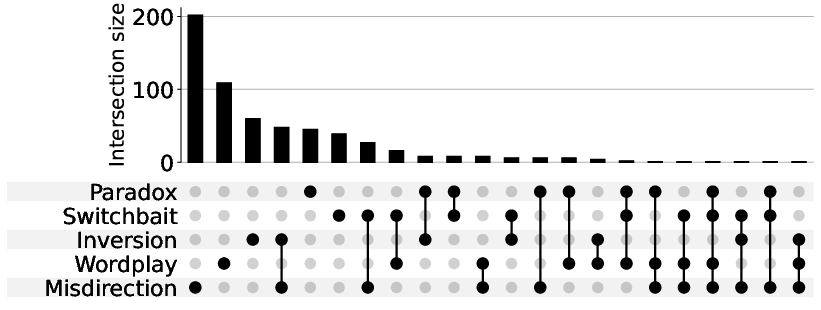
Figure 5: UpSet plot illustrating the overlap and intersection sizes among Drivelology categories.
Implications and Future Directions
The findings highlight a persistent gap between statistical fluency and genuine cognitive comprehension in LLMs. Drivelology serves as a stringent benchmark for non-linear, contextually rich reasoning, revealing that current models are not yet capable of reliably interpreting layered, culturally embedded nonsense.
The authors propose two key avenues for future research:
- Model Training: Leveraging the MCQA task for group-wise preference optimization (GRPO), which could provide richer training signals and improve subtle semantic discrimination.
- Generation Metrics: Developing novel metrics to quantify entertainability, relevance, and paradoxical depth in generated Drivelology, enabling more rigorous assessment and targeted model improvement.
Conclusion
Drivelology represents a uniquely challenging test of LLMs' pragmatic and semantic understanding. The DrivelHub dataset and evaluation framework expose clear limitations in current models' ability to interpret nonsense with depth, especially in multilingual and culturally nuanced contexts. Addressing these challenges will require advances in model architecture, training methodology, and evaluation metrics, with the ultimate goal of developing AI systems capable of deeper social and cultural awareness.
