- The paper presents a modular data engine that generates 947,854 spatiotemporally grounded instruction-response pairs to boost fine-grained video reasoning.
- It leverages a combination of Video LLMs and pixel-level models like GroundingDINO and SAM2 to create detailed masklets and temporal annotations.
- Results show reliable benchmark improvements on spatial-temporal tasks, while indicating future work is needed for occlusion handling and long-range dependencies.
Strefer: Synthetic Instruction Data for Space-Time Referring and Reasoning in Video LLMs
Motivation and Problem Statement
The Strefer framework addresses a critical gap in Video LLMs: the inability to resolve fine-grained spatial and temporal references in dynamic, real-world video environments. While recent Video LLMs demonstrate progress in general video understanding, they lack the granularity to track and reason about specific object states, movements, and temporal relations, especially when user queries involve explicit space-time references (e.g., "What is the man in the red shirt doing at 00:01:23?"). This limitation is primarily due to the scarcity of instruction-tuning data that is both object-centric and spatiotemporally grounded.
Strefer Data Engine: Architecture and Pipeline
Strefer introduces a modular, fully-automated data engine for generating synthetic instruction-response pairs that are richly grounded in both space and time. The pipeline orchestrates multiple open-source, pre-trained models—Video LLMs, LLMs, and pixel-level vision foundation models (e.g., RexSeek, GroundingDINO, SAM2)—to pseudo-annotate videos with temporally dense, object-centric metadata. This metadata includes active entities, their locations as masklets (segmentation masks tracked over time), and their action descriptions and timelines.

Figure 1: Example of Strefer-annotated instruction-response pairs and video metadata, showing masklets and action timelines for multiple entities in complex video scenarios.
The pipeline consists of the following key modules:
- Entity Recognizer: Identifies all active entities in the video using a Video LLM, guided by explicit prompts to distinguish between similar entities.
- Referring Parser: Extracts structured lists of entity-referring expressions, noun categories, and generalized categories from the recognizer's output.
- Referring Masklet Generator: Generates masklets for each referring expression by combining GroundingDINO (for object detection with generalized nouns), SAM2 (for bidirectional tracking and segmentation), and RexSeek (for disambiguating multi-word referring expressions and assigning them to the correct masklets). This module robustly handles cases where entities are absent in the first frame or temporarily leave and re-enter the scene.
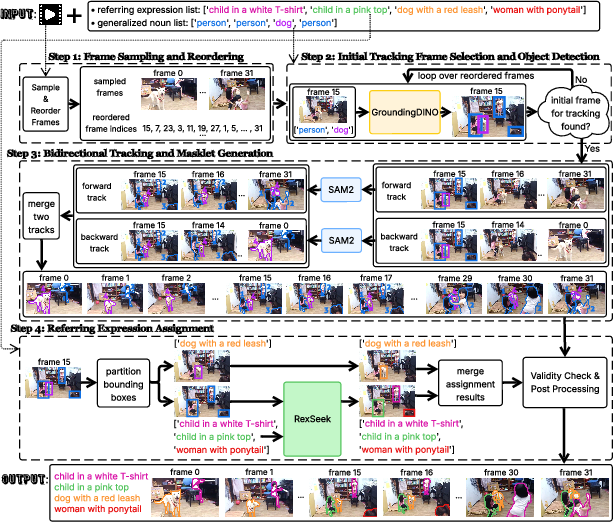
Figure 2: Overview of the Referring Masklet Generation Pipeline, addressing multi-entity, occlusion, and re-entry challenges.
- Video Clipper: Segments videos into semantically distinct clips using PySceneDetect and SigLIP-based hierarchical clustering, enabling temporally dense annotation.
- Video Transcriber: Generates behavior-centric descriptions for each entity in each clip, focusing on explicit, observable dynamics.
- Instruction Data Generator: Synthesizes instruction-style QA pairs using both templates and LLMs, covering a diverse set of spatiotemporal reasoning tasks. Questions are designed to require masklet and/or timestamp references, and language-based references are replaced with pronouns or generic terms to enforce reliance on visual grounding.
Data Composition and Task Coverage
Strefer generated 947,854 instruction-response pairs from only 4,253 NExT-QA videos (average 40 seconds, up to 3 minutes). The data is organized into 8 groups, covering 11 distinct question task types, including:
Model Integration and Training
Strefer data can be used to instruction-tune general-purpose Video LLMs with or without architectural modifications:
- With Architectural Enhancements: Plug-and-play modules (Region-Language Connector, Timestamp Conversion) are added to support fine-grained masklet and timestamp comprehension. The spatiotemporal object encoder from VideoRefer and temporal token learning from GroundedLLM are incorporated.
- Without Architectural Changes: Visual prompting methods such as SoM (mask overlay) and NumberIt (frame ID overlay) are explored for training-free adaptation.
The model is fine-tuned on a base recipe (BLIP-3-Video + VideoRefer-700K) with Strefer data added. The visual encoder is kept frozen due to data limitations. Training uses 32 frames per video and 32 temporal tokens, with a total of 4B parameters and 3×8 H200 GPUs for one day.
Quantitative and Qualitative Results
Strefer-trained models consistently outperform baselines on benchmarks requiring spatial and temporal disambiguation:
- VideoRefer-BenchD (Mask-Referred Regional Description): Average score increases from 3.28 (baseline) to 3.39 (Strefer final recipe).
- VideoRefer-BenchQ (Mask-Referred Regional QA): Accuracy improves from 0.665 to 0.688.
- QVHighlights (Timestamp-Referred QA): Accuracy rises from 0.529 to 0.603.
- TempCompass and VideoMME (Temporal Reasoning): Notable improvements, even though Strefer data is from short videos.
Ablation studies reveal that the inclusion of mask/timestamp-referred queries and negative questions is critical for performance. However, adding event sequencing data can trade off fine-grained spatial-temporal understanding for higher-level temporal abstraction.


Figure 4: Qualitative comparison on VideoRefer-BenchD. Strefer-trained model correctly identifies the table, while the baseline misinterprets the mask as a person.


Figure 5: Strefer-trained model demonstrates superior timestamp-based reasoning on QVHighlights, accurately localizing and describing events.
Additional qualitative results show that Strefer-trained models mitigate foreground and center bias, handle multi-entity disambiguation, and exhibit improved fine-grained action understanding.
Limitations and Future Directions
Strefer's synthetic data is not error-free; pseudo-annotations may miss occluded entities or contain hallucinations from underlying models. The masklet generator, while robust, still struggles with heavy motion blur and long-range dependencies. The modular pipeline's reliance on multiple models may pose reproducibility challenges for resource-constrained groups, but components can be swapped for efficiency.
Current models are limited to mask-based spatial referring; future work should extend to points, boxes, and scribbles, which can be derived from masks. Output-level spatiotemporal grounding remains an open challenge, requiring higher-fidelity annotations. Systematic optimization of data composition and leveraging larger LLM backbones are promising directions.
Implications and Outlook
Strefer establishes a scalable methodology for generating high-utility, spatiotemporally grounded instruction data without manual annotation or proprietary models. This enables Video LLMs to resolve complex, real-world queries involving object-centric events and temporal references, a prerequisite for advanced applications in navigation, surveillance, and interactive robotics.
The framework's modularity ensures that as vision and language foundation models improve, Strefer's data quality and coverage will correspondingly advance. The approach also highlights the importance of data specificity and task diversity over sheer volume for effective instruction tuning.
Conclusion
Strefer provides a principled, scalable solution for equipping Video LLMs with fine-grained space-time referring and reasoning capabilities. By synthesizing instruction-response pairs grounded in dense, object-centric video metadata, Strefer-trained models achieve superior performance on spatial and temporal disambiguation tasks. This work lays the foundation for perceptually grounded, instruction-tuned Video LLMs capable of sophisticated, context-aware reasoning in dynamic environments. Future research should focus on output-level grounding, broader spatial reference modalities, and systematic data mixture optimization to further enhance generalization and robustness.
