- The paper develops LMEnt, a comprehensive suite that annotates and indexes entity mentions from pretraining data, providing fine-grained traceability to model representations.
- It demonstrates that entity-based retrieval outperforms string-based methods, achieving up to 80.4% win rates and maintaining over 97% precision at deeper retrieval depths.
- Scaling studies reveal that larger LMEnt models improve recall for frequent entity pairs, emphasizing the role of co-occurrence frequency in knowledge acquisition dynamics.
LMEnt: A Suite for Analyzing Knowledge in LLMs from Pretraining Data to Representations
Introduction and Motivation
The LMEnt suite addresses a critical gap in the study of knowledge acquisition in LMs: the lack of fine-grained, entity-level traceability from pretraining data to model representations. Existing approaches for analyzing knowledge in LMs typically rely on post-hoc string-based retrieval, which is insufficient for robustly mapping semantically equivalent information due to alias ambiguity and variability in phrasing. LMEnt introduces a comprehensive framework for annotating, indexing, and analyzing entity mentions in pretraining corpora, enabling precise tracking of knowledge acquisition and facilitating causal interventions.
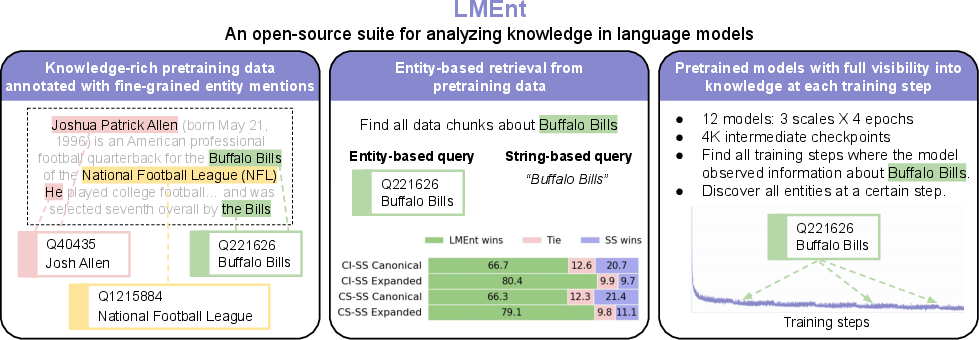
Figure 1: LMEnt suite overview: entity annotation, entity-based retrieval index, and 12 models with traceable entity exposure across training steps.
Entity Annotation Pipeline
LMEnt leverages English Wikipedia as a knowledge-rich pretraining corpus, annotating each document with fine-grained entity mentions using three complementary sources: Wikipedia hyperlinks, entity linking (ReFinED), and coreference resolution (Maverick). This multi-source annotation enables disambiguation between entities with similar surface forms and captures both explicit and implicit references, including pronouns and descriptive phrases.
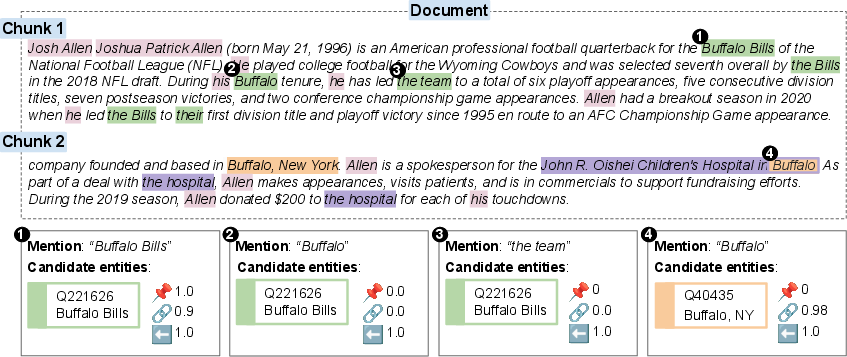
Figure 2: Disambiguation of entity mentions in the "Josh Allen" document, demonstrating explicit and implicit linking and coreference clustering.
The annotation pipeline is designed for scalability, utilizing 8 H100 GPUs and processing 3.6B tokens into 10.5M chunks, yielding 400M entity mentions across 7.3M entities. Each mention is mapped to a Wikidata QID and assigned confidence scores from the respective annotation sources, supporting flexible retrieval and filtering.
Entity-Based Retrieval and Indexing
LMEnt constructs an Elasticsearch index of all pretraining chunks, each annotated with entity mentions and their QIDs. Retrieval is performed by matching on QID and source-specific confidence thresholds, enabling high-precision identification of all training steps where a given entity was observed. This approach overcomes the limitations of string-based retrieval, which suffers from low recall and high noise due to alias expansion and ambiguous surface forms.
Pretrained Model Suite
The LMEnt suite includes 12 transformer models (OLMo-2 architecture) with 170M, 600M, and 1B parameters, each trained for 1, 2, 4, and 6 epochs on the annotated Wikipedia corpus. Intermediate checkpoints (every 1,000 steps) are released, providing granular visibility into knowledge acquisition dynamics. The 170M model is compute-optimal for the token budget, and all models are trained with variable sequence length curriculum to avoid spurious inter-document correlations.
Empirical Evaluation: Knowledge Recall and Retrieval
Knowledge Recall Benchmarks
LMEnt models are evaluated on PopQA and PAQ, two entity-centric QA benchmarks. Despite being trained on only 0.03%–4.7% of the tokens used for comparable models, LMEnt achieves competitive performance: 7.4% accuracy on all PopQA entities and 66% on popular entities, closely matching Pythia-1.4B and OLMo-1B, and trailing OLMo-2-1B and SmolLM-1.7B primarily due to recall failures on rare facts.
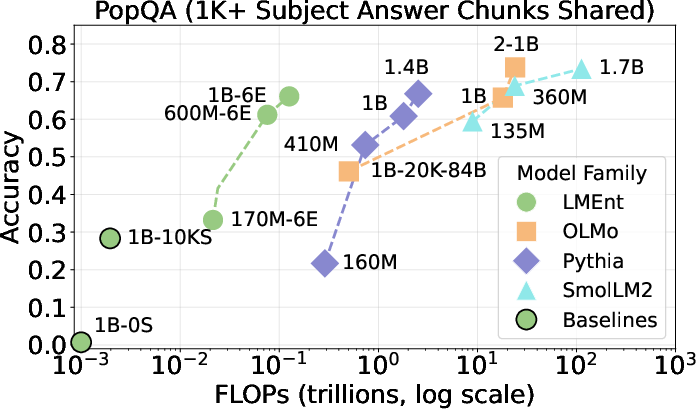
Figure 3: LMEnt models match or exceed the compute efficiency of open-source baselines on popular PopQA entities.
Scaling model size improves recall for facts where subject and answer entities co-occur frequently, but has limited effect on tail facts.
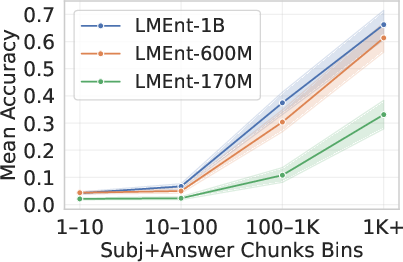
Figure 4: Larger LMEnt models better learn associations for frequently co-occurring entity pairs.
Entity-Based vs. String-Based Retrieval
LMEnt's entity-based retrieval outperforms string-based methods (case-sensitive/insensitive, canonical/expanded) by 66.7%–80.4% in pairwise win rates, with ablation studies showing that hyperlinks and entity linking are the most critical components.
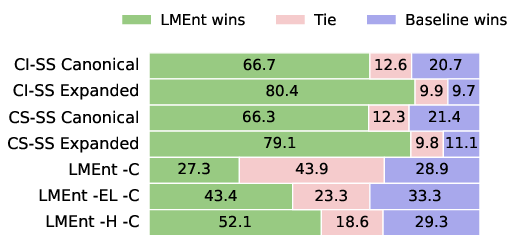
Figure 5: LMEnt retrieval win rates against string-based methods and ablations; entity linking and hyperlinks are essential.
LMEnt retrieves more relevant chunks for torso and tail entities, which constitute 99.7% of Wikipedia entities, while string-based expanded variants suffer from excessive noise.
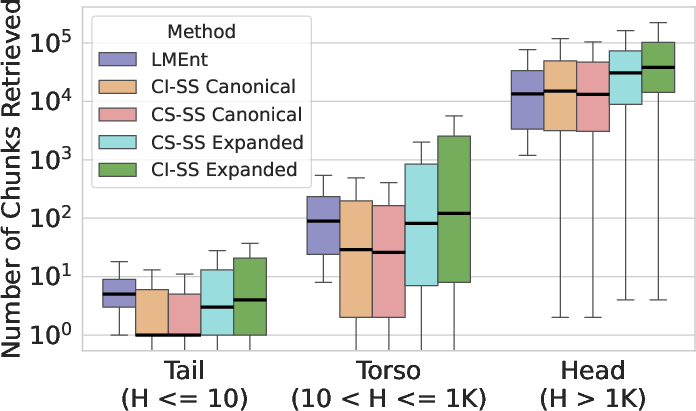
Figure 6: LMEnt achieves superior chunk coverage for rare entities compared to string-based baselines.
Precision at increasing retrieval depths remains above 97% for LMEnt, while string-based methods degrade to 84% and 27%.
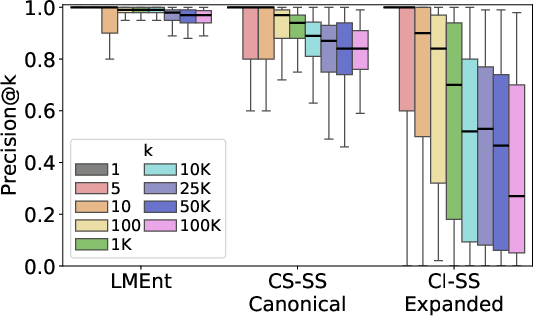
Figure 7: LMEnt maintains high precision at all retrieval depths, unlike string-based approaches.
Entity co-occurrence in training data is a stronger predictor of model performance than pageview popularity, suggesting that knowledge acquisition is tightly coupled to the frequency of joint exposure.
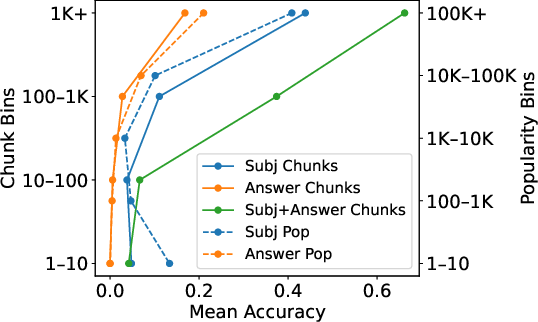
Figure 8: Model accuracy correlates best with subject-answer chunk co-occurrence, not entity popularity.
Knowledge Acquisition Dynamics
LMEnt enables analysis of knowledge learning and forgetting across training checkpoints. Fact frequency (number of co-occurring subject-answer chunks) correlates with both learning and forgetting rates, but the underlying mechanisms remain unclear. Notably, both rates increase with frequency, indicating complex plasticity in knowledge representations.
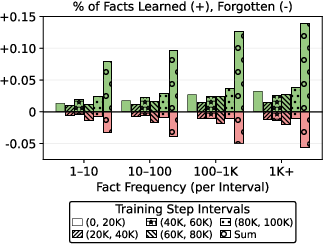
Figure 9: Both learning and forgetting rates increase with fact frequency across LMEnt-1B-6E checkpoints.
Implementation and Practical Considerations
- Annotation Pipeline: Requires substantial GPU resources for coreference and entity linking; scalable to larger corpora with further optimization.
- Indexing: Elasticsearch index supports efficient QID-based retrieval and flexible filtering by source and confidence.
- Model Training: OLMo-2 backbone, variable sequence length curriculum, and compute-optimal sizing ensure efficient training and controlled analysis.
- Evaluation: LLM-as-a-judge (Gemini 2.5 Flash) is statistically validated for chunk precision assessment, enabling scalable evaluation of retrieval quality.
Implications and Future Directions
LMEnt provides a controlled, extensible testbed for studying knowledge representations, plasticity, editing, and attribution in LMs. The suite facilitates mechanistic interpretability by enabling causal interventions and precise tracking of entity exposure. Extensions to knowledge-poor corpora, larger model architectures (e.g., mixture-of-experts), and mid/post-training phases are straightforward, with entity linking alone providing robust annotation in the absence of hyperlinks.
Potential applications include:
- Knowledge Editing: Controlled injection and removal of facts during pretraining.
- Factuality Enhancement: Data ordering and explicit mention replacement to improve recall.
- Scaling Studies: Analysis of knowledge acquisition across model and data scale.
- Mechanistic Interpretability: Tracing latent circuits and representations linked to entity exposure.
Conclusion
LMEnt establishes a rigorous framework for analyzing the interplay between pretraining data and knowledge representations in LLMs. By combining fine-grained entity annotation, high-precision retrieval, and a suite of pretrained models with traceable exposure, LMEnt enables detailed study of knowledge acquisition dynamics and supports a wide range of research in LM interpretability, editing, and factuality. The open-source release of data, models, and checkpoints ensures reproducibility and extensibility for future work in the field.