AdaGrad Meets Muon: Adaptive Stepsizes for Orthogonal Updates
Published 3 Sep 2025 in cs.LG and math.OC | (2509.02981v1)
Abstract: The recently proposed Muon optimizer updates weight matrices via orthogonalized momentum and has demonstrated strong empirical success in LLM training. However, it remains unclear how to determine the learning rates for such orthogonalized updates. AdaGrad, by contrast, is a widely used adaptive method that scales stochastic gradients by accumulated past gradients. We propose a new algorithm, AdaGO, which combines a norm-based AdaGrad-type stepsize with an orthogonalized update direction, bringing together the benefits of both approaches. Unlike other adaptive variants of Muon, AdaGO preserves the orthogonality of the update direction, which can be interpreted as a spectral descent direction, while adapting the stepsizes to the optimization landscape by scaling the direction with accumulated past gradient norms. The implementation of AdaGO requires only minimal modification to Muon, with a single additional scalar variable, the accumulated squared gradient norms, to be computed, making it computationally and memory efficient. Optimal theoretical convergence rates are established for nonconvex functions in both stochastic and deterministic settings under standard smoothness and unbiased bounded-variance noise assumptions. Empirical results on CIFAR-10 classification and function regression demonstrate that AdaGO outperforms Muon and Adam.
The paper introduces AdaGO, which combines AdaGrad's adaptive gradient scaling with Muon’s orthogonal updates to achieve optimal convergence in nonconvex deep learning tasks.
The algorithm adaptively tunes stepsizes with a single scalar accumulator, enabling robust performance in both stochastic and deterministic settings.
Empirical results demonstrate that AdaGO outperforms Adam and Muon by reducing training losses and boosting test accuracy on tasks like regression and CIFAR-10 classification.
AdaGO: Adaptive Stepsizes for Orthogonal Updates in Deep Learning
Introduction and Motivation
The paper introduces AdaGO, an optimizer that fuses the norm-based adaptive stepsize mechanism of AdaGrad with the orthogonalized update direction of Muon. Muon, which updates matrix parameters via orthogonalized momentum, has shown empirical success in large-scale neural network training, particularly for LLMs. However, the selection of effective learning rates for Muon remains an open problem due to the altered optimization dynamics induced by orthogonalization. AdaGrad, on the other hand, adaptively scales gradients based on their accumulated history, but its behavior under orthogonalized updates is not well understood. AdaGO addresses this gap by adaptively tuning stepsizes for orthogonalized directions, preserving the spectral descent interpretation while maintaining computational efficiency.
Algorithmic Details
AdaGO modifies Muon by introducing a single scalar accumulator for the squared gradient norms, requiring minimal additional computation and memory. The update rule is:
Θt=Θt−1−αtOt
where Ot is the orthogonalized momentum (via SVD or Newton-Schulz approximation), and the adaptive stepsize αt is:
αt=max{ϵ,ηvtmin{∥Gt∥,γ}}
with vt2=vt−12+min{∥Gt∥2,γ2}, and ϵ is a lower bound to ensure numerical stability. The gradient norm is typically computed using the Frobenius norm for efficiency. This design ensures null gradient consistency, i.e., updates vanish as the optimizer approaches a stationary point.
Theoretical Analysis
AdaGO achieves optimal convergence rates for nonconvex objectives under standard smoothness and bounded-variance noise assumptions. Specifically:
Stochastic Setting: With batch size bt=1, ϵ=T−3/4, 1−μ=T−1/2, and η=T−(3/8+q), AdaGO attains the rate O(T−1/4), which matches the lower bound for stochastic first-order methods.
Deterministic Setting: Without momentum, using full batch, ϵ=T−1/2, and η=T−q, AdaGO achieves O(T−1/2) convergence, the best possible for deterministic first-order methods.
Adaptive to Noise: When momentum is off and batch size increases (bt=t or bt=t), AdaGO adapts to the noise level, interpolating between the stochastic and deterministic rates.
The analysis leverages spectral norm smoothness and shows that the impact of hyperparameters γ and v0 is limited to logarithmic factors in the error bounds.
Empirical Results
AdaGO is benchmarked against Adam and Muon on function regression and CIFAR-10 classification tasks. Hyperparameters are tuned via grid search, with AdaGO requiring an additional ϵ parameter, typically set such that ϵ<η2.
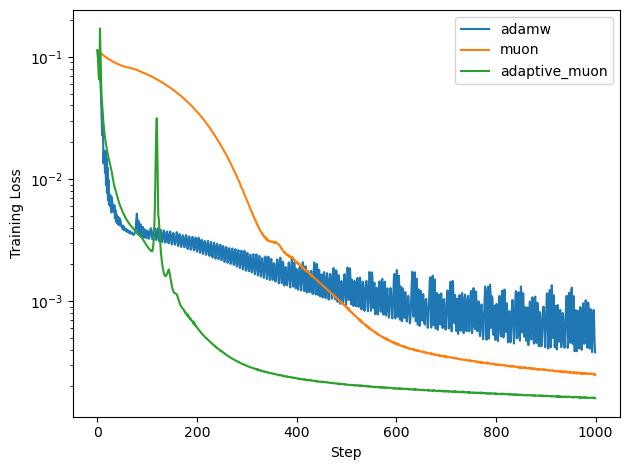
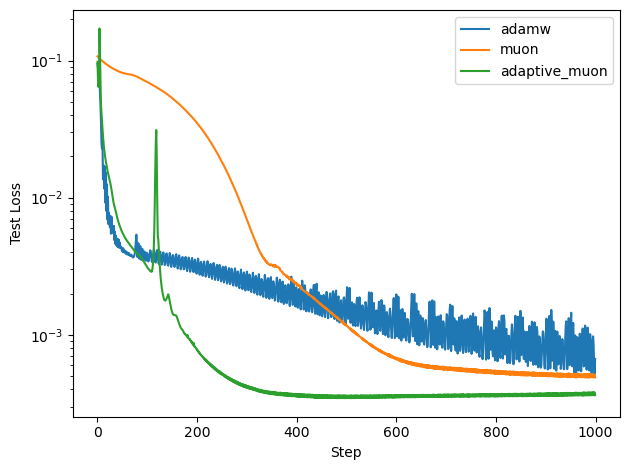
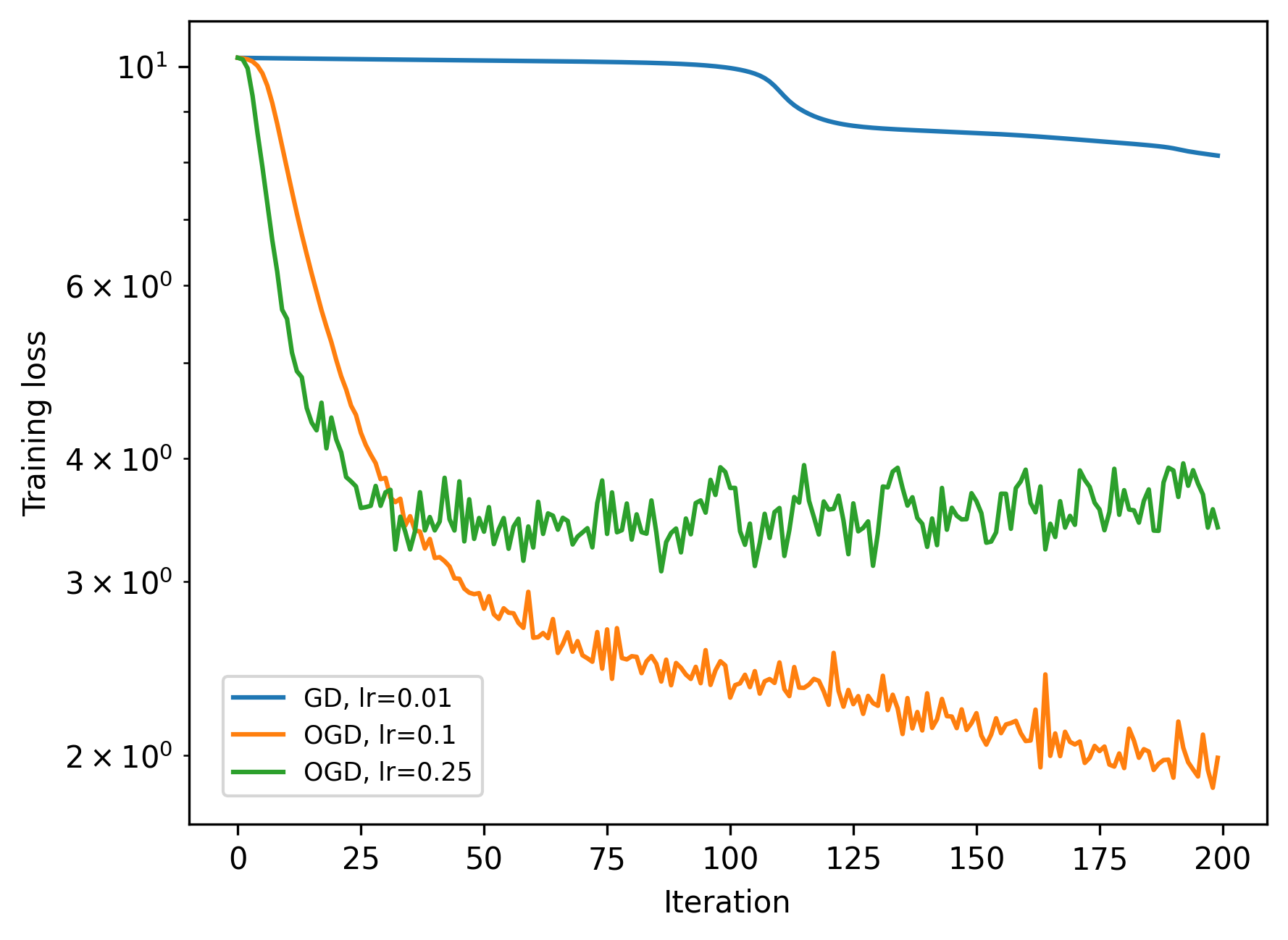
Regression Task: AdaGO converges to lower training and test losses than Adam and Muon. Adam exhibits oscillatory behavior, while Muon is more stable but less effective than AdaGO. AdaGO's aggressive updates occasionally cause spikes, but recovery is rapid.
Figure 1: AdaGO achieves lower final training and test losses in regression compared to Adam and Muon.
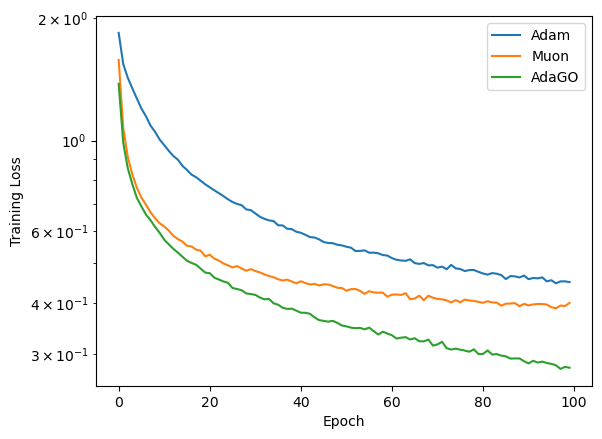
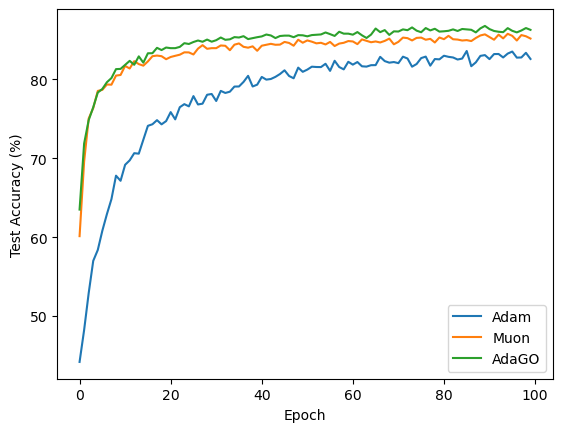
CIFAR-10 Classification: AdaGO maintains consistently lower training loss and achieves higher test accuracy throughout training.
Figure 2: AdaGO outperforms Adam and Muon in both training loss and test accuracy on CIFAR-10.
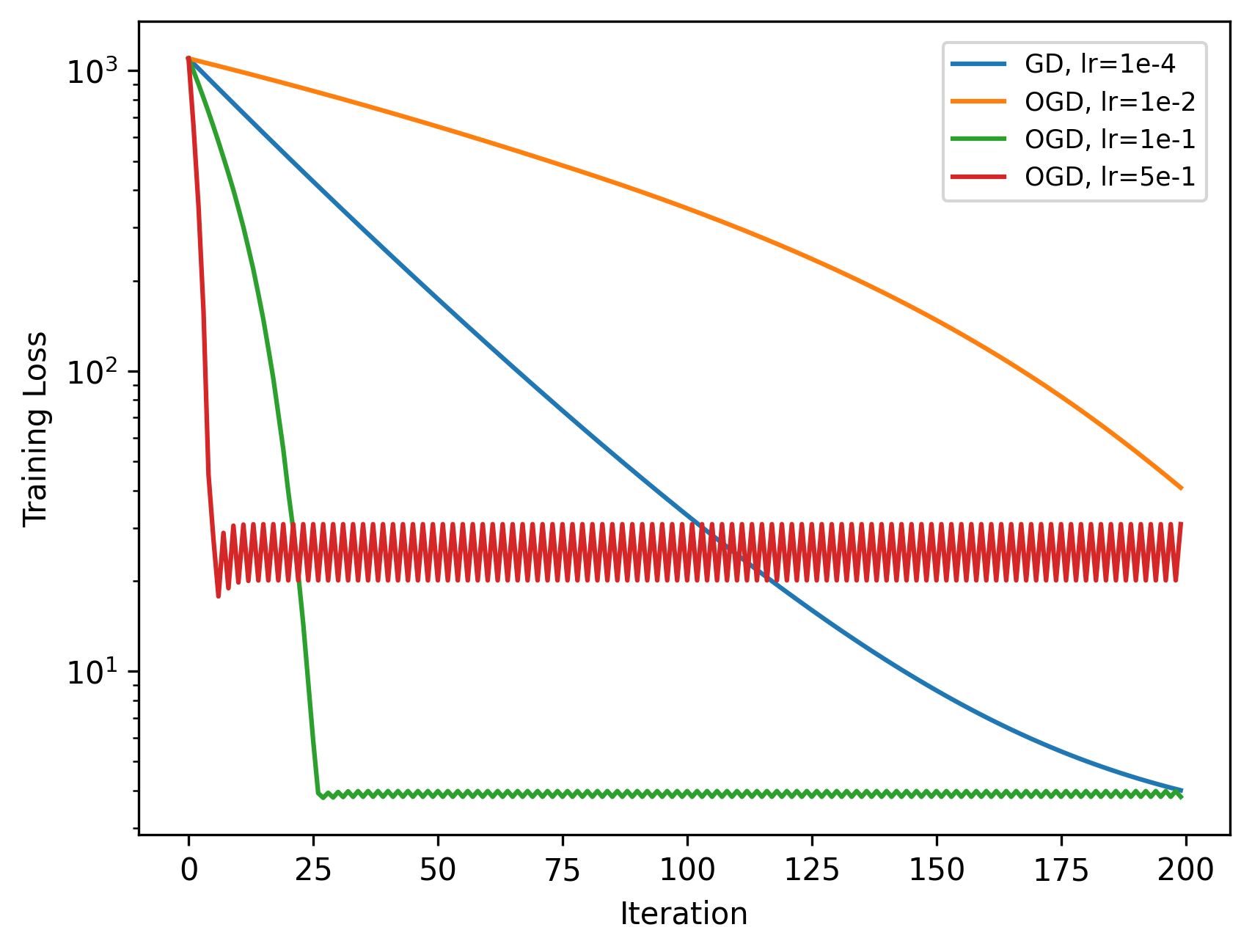
Learning Rate Dynamics: The motivating example demonstrates that OGD with a large constant learning rate initially reduces loss rapidly but plateaus, while a smaller rate converges more slowly but to a lower loss. Adaptive stepsizes, as in AdaGO, are necessary for robust convergence.
Figure 3: OGD with large learning rates exhibits rapid initial descent but plateaus, motivating adaptive stepsize schedules.
Implementation Considerations
Computational Overhead: AdaGO requires only a single additional scalar accumulator over Muon, making it suitable for large-scale models.
Orthogonalization: In practice, Newton-Schulz iterations are used for efficient orthogonalization, with theoretical analysis assuming exact computation.
Hyperparameter Robustness: The algorithm is robust to choices of γ and v0 as long as their ratio is O(1).
Deployment: AdaGO can be integrated into existing Muon-based pipelines with minimal changes, and is compatible with hybrid optimization (e.g., using Adam for non-matrix parameters).
Practical and Theoretical Implications
AdaGO demonstrates that adaptive stepsizes can be effectively combined with orthogonalized updates, yielding both theoretical guarantees and empirical improvements. The preservation of orthogonality in updates is crucial for spectral descent properties and may have implications for implicit bias and generalization in deep networks. The approach is computationally efficient and scalable, making it attractive for LLM and large-scale vision model training.
Future Directions
Potential avenues for further research include:
Extending AdaGO to LLM pretraining and fine-tuning regimes.
Analyzing AdaGO under relaxed smoothness or noise assumptions.
Incorporating second-order information or more sophisticated adaptivity.
Exploring the implicit bias and generalization properties induced by orthogonalized adaptive updates.
Conclusion
AdaGO provides a principled and efficient solution for adaptive stepsize selection in orthogonalized update optimizers. By combining AdaGrad-type norm-based adaptation with Muon's spectral descent direction, AdaGO achieves optimal convergence rates and superior empirical performance on both regression and classification tasks. Its minimal computational overhead and robustness to hyperparameter choices make it a practical choice for large-scale deep learning. Future work will focus on scaling AdaGO to LLMs and further theoretical analysis of its properties.
“Emergent Mind helps me see which AI papers have caught fire online.”
Philip
Creator, AI Explained on YouTube
Sign up for free to explore the frontiers of research
Discover trending papers, chat with arXiv, and track the latest research shaping the future of science and technology.Discover trending papers, chat with arXiv, and more.