HF-RAG: Hierarchical Fusion-based RAG with Multiple Sources and Rankers
Abstract: Leveraging both labeled (input-output associations) and unlabeled data (wider contextual grounding) may provide complementary benefits in retrieval augmented generation (RAG). However, effectively combining evidence from these heterogeneous sources is challenging as the respective similarity scores are not inter-comparable. Additionally, aggregating beliefs from the outputs of multiple rankers can improve the effectiveness of RAG. Our proposed method first aggregates the top-documents from a number of IR models using a standard rank fusion technique for each source (labeled and unlabeled). Next, we standardize the retrieval score distributions within each source by applying z-score transformation before merging the top-retrieved documents from the two sources. We evaluate our approach on the fact verification task, demonstrating that it consistently improves over the best-performing individual ranker or source and also shows better out-of-domain generalization.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
HF-RAG: An easy explanation
What is this paper about?
This paper introduces a new way to help AI systems check facts, called HF-RAG. It combines two kinds of information to answer a claim:
- Labeled examples (like practice problems with answers)
- Unlabeled text (like helpful articles from Wikipedia)
It also combines results from several different “search helpers” to find the best evidence. The goal is to make fact-checking more accurate, especially for topics the AI hasn’t seen before.
Main goal of the paper
The researchers want to make AI better at verifying statements like “Polar bears are going extinct because of global warming.” To do that, they:
- Mix information from both labeled data (claims with known answers) and unlabeled data (general knowledge articles)
- Combine the top results from multiple search systems
- Standardize scores so they can fairly compare results from different sources
They test this idea on fact-checking tasks and show it works better than common methods.
Key questions the paper asks
The paper focuses on four simple questions:
- Does combining labeled and unlabeled information help the AI work better on new topics?
- What helps more: using multiple search systems or using multiple information sources?
- If the AI finds better evidence, does it actually give better answers?
- How sensitive is the method to how many examples are included as context?
How the method works, in simple terms
Think of the system like a student checking a claim using two backpacks:
- Backpack 1: Labeled data (examples of claims with correct answers). This helps with task-specific patterns.
- Backpack 2: Unlabeled data (articles from Wikipedia). This helps with broader knowledge.
HF-RAG combines both backpacks wisely and uses multiple “search buddies” to fetch the best items from each.
Important terms, explained
- Retrieval-Augmented Generation (RAG): The AI first retrieves helpful text from outside sources, then uses it to generate an answer.
- Labeled vs. Unlabeled:
- Labeled: Claims with known answers (support/refute/not enough info).
- Unlabeled: Articles without answers, like Wikipedia pages.
- Rankers: Different search tools that pick the best matching documents for a claim (e.g., BM25, Contriever, ColBERT, MonoT5).
- Reciprocal Rank Fusion (RRF): A way to merge the top results from multiple rankers. Imagine each ranker makes a top-10 list; RRF gives extra points to documents that appear high across several lists.
- Z-score standardization: A way to make scores comparable across different sources. Think of it like comparing test scores from different schools by converting them to a common scale.
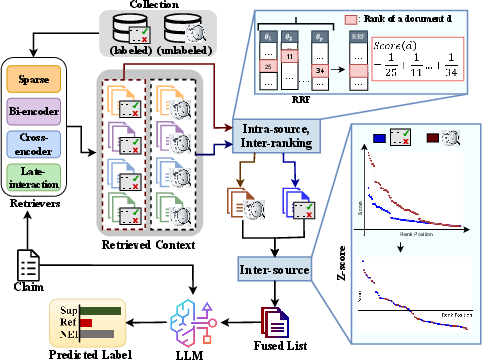
The HF-RAG approach in two steps
- Step 1: Combine multiple rankers within each source (labeled or unlabeled)
- For labeled and unlabeled sources separately, use RRF to merge the top documents from several rankers into one strong list per source.
- Step 2: Combine the two sources
- You can’t directly compare scores from different sources (they’re on different scales).
- So, use z-scores to standardize each source’s scores, then merge the two lists into one final list.
- The AI then uses this merged context to decide if the claim is supported, refuted, or unclear.
They test this using LLMs like LLaMA 2 (70B) and Mistral (7B), and datasets like FEVER (in-domain), Climate-FEVER, and SciFact (out-of-domain, i.e., different topics).
What did they find?
Here are the key results, explained simply:
- Using both labeled and unlabeled sources together works best.
- HF-RAG outperforms methods that only use labeled examples (L-RAG) or only use Wikipedia (U-RAG).
- It does especially well on topics outside the training domain, like scientific claims in SciFact.
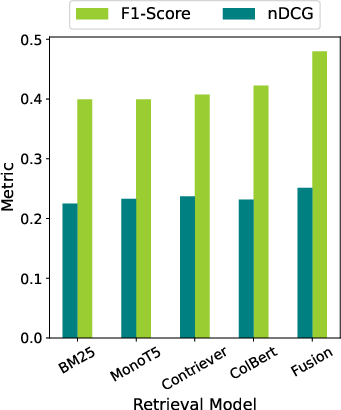
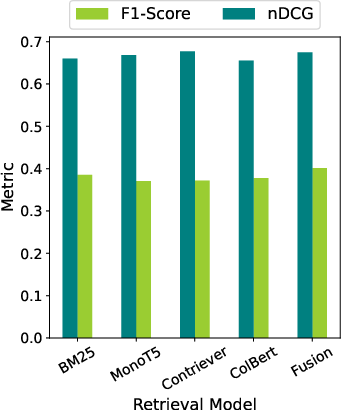
- Using multiple search tools improves performance even before combining sources.
- Combining rankers with RRF helps get better evidence lists.
- Then combining labeled and unlabeled lists with z-scores improves results further.
- Z-score mixing beats simple “fixed mixing.”
- A simple method that picks a fixed percent from each source performs worse than z-score standardization, which adapts to the scores and compares fairly.
- Better evidence leads to better answers.
- When retrieval quality improves (measured with a ranking metric called nDCG@10), final fact-checking scores (macro F1) improve too.
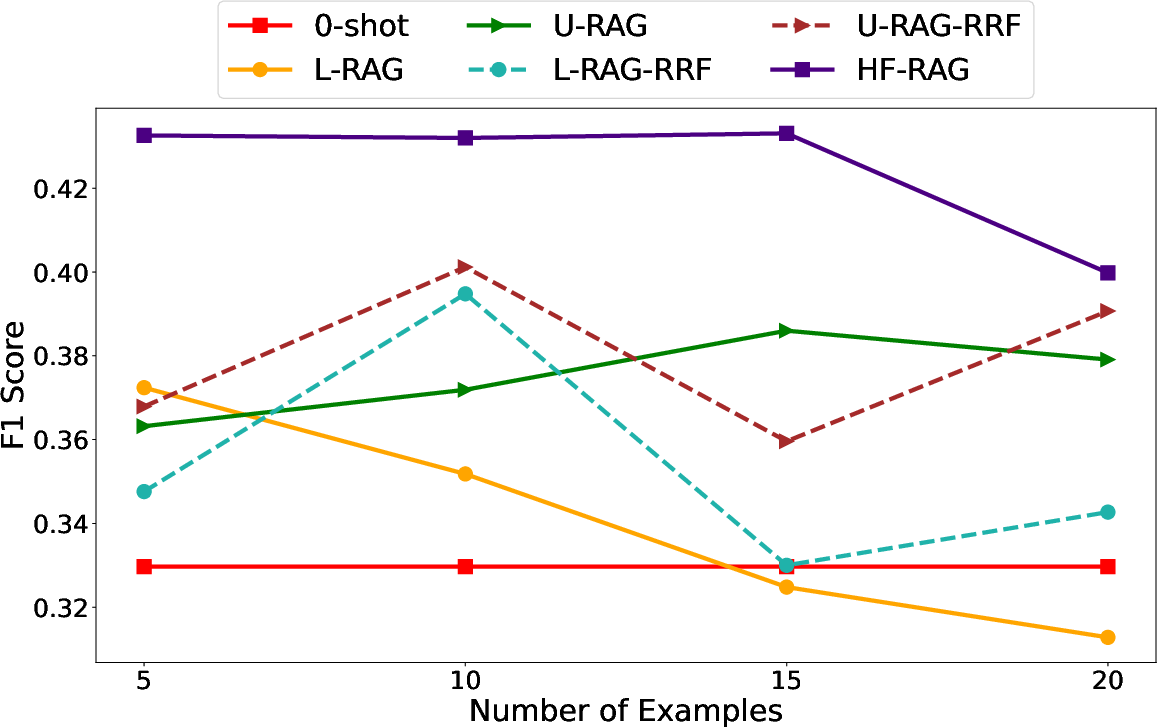
- The method is stable and not too sensitive to “how many examples you include.”
- HF-RAG stays strong across different context sizes, and works well with about 10 examples in the prompt.
Why this matters
- It helps fight misinformation: HF-RAG gives AI systems a stronger way to check facts by combining the precision of labeled examples and the breadth of general knowledge.
- It works across topics: Because it balances task-specific patterns with broad knowledge, it handles new domains better (like science or climate facts).
- It’s practical: The approach runs at inference time (no extra training needed), so it can be plugged into existing RAG systems.
- It’s a foundation for smarter systems: The authors suggest future work could add reasoning components or multi-agent designs that use search even more intelligently.
In short, HF-RAG is like giving an AI both a well-marked study guide and a trustworthy library, plus several helpful librarians—and teaching it how to combine everything fairly. That makes it better at deciding whether claims are true, false, or uncertain.
Collections
Sign up for free to add this paper to one or more collections.