- The paper introduces MR-DINOSAUR, refining the DINOSAUR model with motion-driven pseudo-labels to enable unsupervised multi-object discovery.
- It employs a two-stage training process that first generates instance pseudo-labels from quasi-static frames and then uses a slot deactivation module to distinguish foreground from background.
- Experimental results show notable improvements, including an 11.8% increase in F1₅₀ on the KITTI dataset, outperforming state-of-the-art unsupervised methods.
Motion-Refined DINOSAUR for Unsupervised Multi-Object Discovery
The paper "Motion-Refined DINOSAUR for Unsupervised Multi-Object Discovery" (2509.02545) introduces a novel approach named MR-DINOSAUR, a minimalist yet effective unsupervised multi-object discovery (MOD) framework. This method enhances the existing self-supervised object-centric learning (OCL) model, DINOSAUR, by refining slot representations with motion-driven pseudo-labels, thus achieving notable performance improvements on standard datasets such as TRI-PD and KITTI.
Introduction
The task of unsupervised multi-object discovery (MOD) focuses on detecting and localizing distinct object instances in visual scenes devoid of human supervision. While prior approaches have applied OCL and motion cues from video to identify individual objects, they necessitate some form of supervision to generate pseudo labels, which are used for training OCL models. The work presented deals with overcoming these limitations through the introduction of MR-DINOSAUR (Motion-Refined DINOSAUR), which remarkably extends the self-supervised pre-trained OCL model, DINOSAUR (Sas et al., 2023), to the MOD task in a fully unsupervised manner.






Figure 1: Overview and results of our unsupervised multi-object discovery approach MR-DINOSAUR. We propose a minimalist approach to generate instance pseudo-labels from motion for refining slot representations of the DINOSAUR model. Further, we train our proposed slot deactivation module to distinguish foreground from background slots (top). MR-DINOSAUR outperforms the previous SotA approach DIOD, indicated by the gains in $F1\textsubscript{50}$ (bottom).
The objective is to achieve instance-level scene understanding without relying on human-provided annotations, which can be resource-intensive. This work addresses the challenges of slot-attention methods in achieving precise object mask segmentation and distinguishes between foreground and background slots. MR-DINOSAUR uses video frames without camera motion to generate high-quality unsupervised pseudo labels through motion segmentation of optical flow.
MR-DINOSAUR Two-Stage Training Scheme
The paper introduces a two-stage training scheme for extending the DINOSAUR model to perform unsupervised MOD. DINOSAUR, in its original form, effectively decomposes images into object components but struggles to differentiate between foreground and background features, leading to issues such as over- and under-segmentation (Figure 1).










Figure 2: MR-DINOSAUR architecture and training overview. Stage 1 trains the DINOSAUR slot-attention module using our proposed pseudo-labels. DINOSAUR alpha masks are supervised with pseudo-label instance masks using a weighted binary cross-entropy loss. Stage 2 trains our slot deactivation module using Lfg/bg to learn to discriminate between foreground from background slots.
Pseudo-Label Generation
The core contribution of this work lies in high-quality unsupervised pseudo-label generation using motion cues from video data (Figure 3). MR-DINOSAUR focuses on retrieving video frames with minimal camera movement (quasi-static frames), which helps to isolate moving objects more effectively. By clustering unsupervised optical flow data from these frames using techniques like HDBSCAN, the model retrieves high-precision pseudo-instance labels. These labels, while inherently limited to dynamic objects, are cost-effective to generate as they avoid the reliance on pre-labeled data.

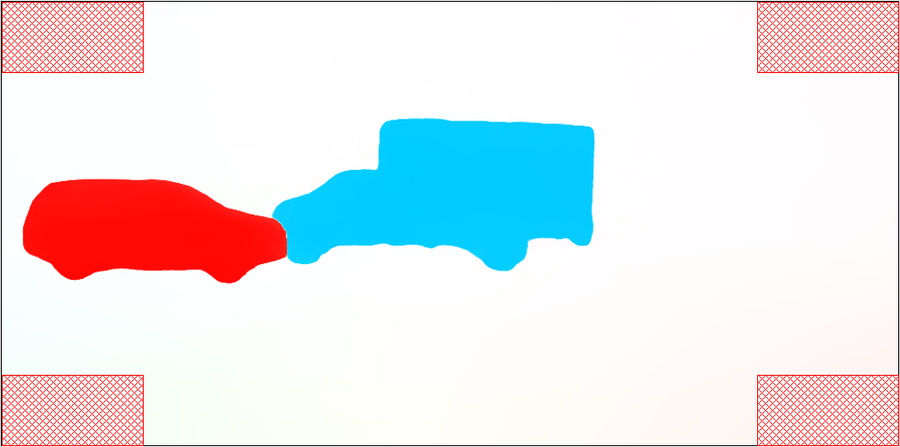

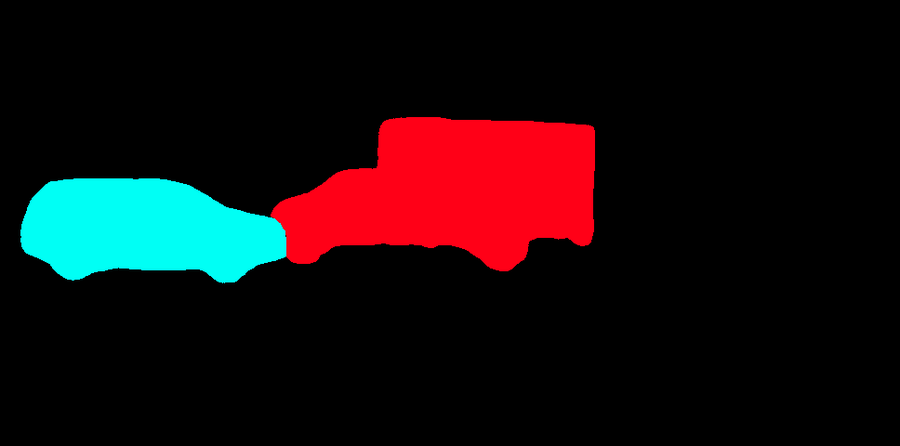
Figure 3: Pseudo-label generation using unsupervised optical flow to derive instance labels, simplifying the acquisition of high-quality pseudo labels.
The thresholding technique applied to average flow magnitudes in image corners proved to be efficient, yielding high accuracy (99.4%), precision (99.2%), and recall (96.6%) on datasets with known camera movements, showcasing its effectiveness in identifying quasi-static frames (Table 7).
Extending DINOSAUR
MR-DINOSAUR employs a two-stage training process to enhance DINOSAUR for unsupervised multi-object discovery. The initial stage involves the development of high-quality pseudo labels from quasi-static frames. These are obtained by unsupervised detection of video frames without camera motion, using the SMURF optical flow estimator [Stone:2021:STM]. The process consists of segmenting the optical flow using thresholds to generate foreground masks, which are subsequently processed through connected component analysis and HDBSCAN clustering to derive pseudo-instance labels from motion data.
Slot Representation and Deactivation
DINOSAUR's initial method presents shortcomings in object masking accuracy and classifying slots as either foreground or background. To address these challenges, MR-DINOSAUR refines slot representations and learns to distinguish between foreground and background using unsupervised motion cues. The introduction of a slot deactivation module (Figure 2) is a key innovation. This MLP-based module predicts a probability for each slot being a foreground object, allowing efficient real-time identification and deactivation of background slots. By incorporating motion information into the instance-level learning process, MR-DINOSAUR avoids the complexity and inefficiencies associated with pre-training on synthetic datasets, rivaling other state-of-the-art techniques in accuracy and utility.
Figure 2: MR-DINOSAUR architecture and training overview. Stage 1 trains the DINOSAUR slot-attention module using our proposed pseudo-labels. DINOSAUR alpha masks are supervised with pseudo-label instance masks using a weighted binary cross-entropy loss. Stage 2 trains our slot deactivation module using Lfg/bg to learn to discriminate between foreground from background slots.
Despite MR-DINOSAUR’s conceptual simplicity, it achieves significant improvements, outperforming state-of-the-art methods for unsupervised MOD tasks on challenging datasets such as TRI-PD and KITTI (Table 1, Table 2), and provides robust qualitative results when compared to DIOD and other baselines (Figure 1, Figure 4, Figure 5, Figure 6, Figure 7).
Experimental Evaluation
The proposed methodology was evaluated against multiple state-of-the-art slot-attention methods for video and image multi-object discovery across datasets such as TRI-PD and KITTI. MR-DINOSAUR demonstrated superiority in terms of essential metrics including F1\textsubscript{50}, AP\textsubscript{50}, and AR\textsubscript{50}, despite the challenges associated with accurately segmenting complex scenes without supervision.
Notably, MR-DINOSAUR achieved 11.8% higher $F1\textsubscript{50}$ on the KITTI dataset compared to DIOD, indicating a significant improvement despite using a completely unsupervised approach.
Interestingly, testing on MOVI-E [78], which presents an artificial camera motion scenario typically adverse to the pseudo-label generation methodology of MR-DINOSAUR, was conducted to expand the evaluation spectrum to other datasets (Table 6).
Conclusion
MR-DINOSAUR represents a significant advancement in the field of computer vision, with its minimalist and unsupervised motion-based approach setting a new standard in unsupervised multi-object discovery. By sidestepping the need for costly supervised data generation, the model achieves significant gains in the challenging task of object identification in both synthetic and real-world datasets. Potential areas for further exploration include integrating capabilities to identify static objects and expanding the application of MR-DINOSAUR to more diverse datasets, possibly by hybridizing with synthetic pre-training methodologies. The simplicity and effectiveness of the MR-DINOSAUR architecture as established by the results suggest its potential as a basis for future object-centric approaches in the field of computer vision.
\section{Figures}




Figure 4: Qualitative comparison of our baseline DINOSAUR~\text {cite:Seitzer:2023:BGR}.


Figure 5: Additional visualizations of our pseudo-labels on the TRI-PD \text {cite:Bao:2022:DOT} dataset.


Figure 6: Failure cases of MR-DINOSAUR (Ours) compared to DIOD \text {cite:Kara:2024:DSD}.
\end{document}