- The paper introduces a novel video compositing framework that integrates dynamic foreground elements into background videos using a diffusion transformer with explicit user control.
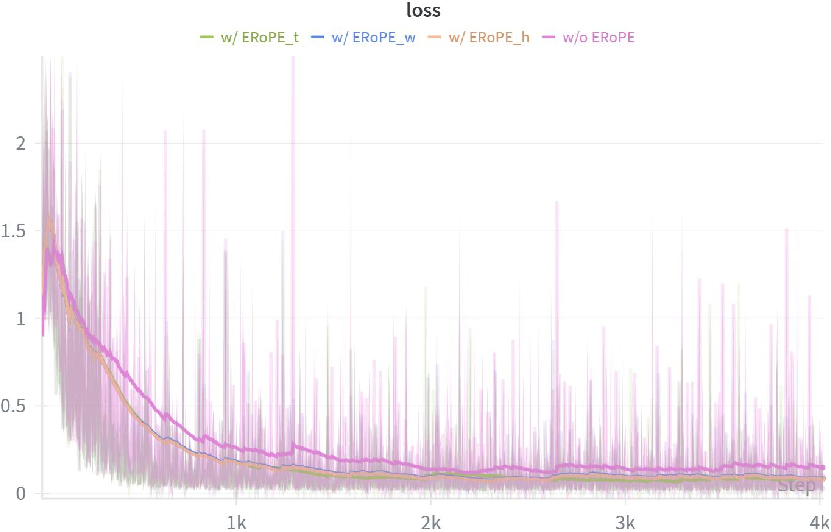
- The method achieves superior performance over baselines with notable metrics such as PSNR 42.00 and SSIM 0.9487, ensuring pixel-level fidelity and harmonious integration.
- The paper leverages innovative components like ERoPE and a DiT fusion block to fuse unaligned video conditions, reducing artifacts and preserving background integrity.
Introduction and Motivation
GenCompositor introduces the task of generative video compositing, which automates the integration of dynamic foreground elements into background videos under explicit user control. This task is distinct from prior video editing paradigms—such as text/image-guided video editing or classical video harmonization—by enabling pixel-level, temporally consistent, and physically plausible compositing of arbitrary video elements, with user-specified trajectories and scale. The method addresses three core challenges: (1) maintaining background consistency, (2) preserving the identity and motion of injected elements, and (3) supporting flexible, fine-grained user control.
Methodology
System Overview
GenCompositor is built upon a Diffusion Transformer (DiT) backbone, augmented with several novel architectural components tailored for the compositing task. The workflow is as follows: given a background video, a foreground video, and user-specified controls (trajectory and scale), the system generates a composited video that faithfully integrates the foreground element along the desired path and size, while harmonizing appearance and ensuring temporal coherence.
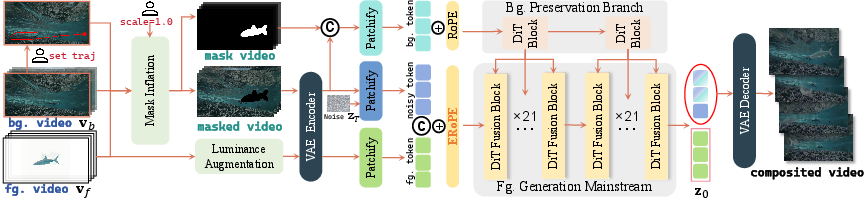
Figure 1: Workflow of GenCompositor, illustrating the input conversion, background preservation, foreground fusion, and automatic compositing pipeline.
Inputs are converted into a form suitable for training and inference. The background video is paired with a user-defined trajectory (drawn or tracked via optical flow) and a scale factor. The foreground video is segmented using Grounded SAM2 to obtain a binary mask, which is then rescaled and repositioned according to the user controls. Mask inflation (via Gaussian filtering) is applied to simulate imperfect masks and encourage robust, realistic blending. Luminance augmentation (random gamma correction) is used during training to improve harmonization under varying lighting conditions.
Background Preservation Branch (BPBranch)
To ensure the composited video maintains the original background outside the edited region, a lightweight BPBranch is introduced. This branch processes the masked background and mask video (both pixel-aligned) using standard DiT blocks and injects the background features into the main generation stream via masked token injection. This operation is critical for preserving spatial alignment and preventing background degradation.
Foreground Generation Mainstream and DiT Fusion Block
Foreground elements are injected using a DiT fusion block, which concatenates tokens from the noisy latent and the foreground condition in a token-wise (not channel-wise) manner, followed by full self-attention. This design avoids the content interference and training collapse observed with channel-wise concatenation or cross-attention, especially when foreground and background are not pixel-aligned.
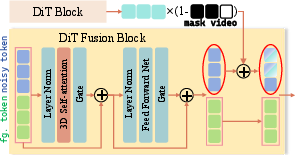
Figure 2: DiT fusion block fuses to-be-generated tokens and unaligned conditional tokens via pure self-attention, producing a harmonized latent representation.
Extended Rotary Position Embedding (ERoPE)
A key innovation is the Extended Rotary Position Embedding (ERoPE), which generalizes RoPE to handle layout-unaligned video conditions. ERoPE assigns unique position labels to each embedding from different videos, preventing interference when fusing foreground and background tokens that are not spatially aligned.
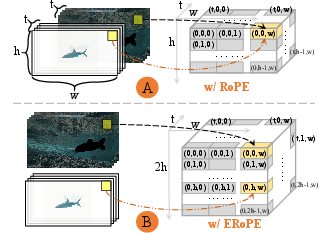
Figure 3: Comparison of standard 3D RoPE and ERoPE. ERoPE assigns unique labels to embeddings from different videos, enabling robust fusion of unaligned content.

Figure 4: ERoPE eliminates artifacts caused by standard RoPE when fusing layout-unaligned videos, as evidenced by the absence of content interference in the composited result.
Dataset Construction
A new dataset, VideoComp, is curated to support this task. It comprises 61K triplets (source video, foreground video, mask video), constructed via a pipeline leveraging CogVLM, Qwen, and Grounded SAM2 for dynamic element identification and segmentation, followed by rigorous filtering for quality and completeness.
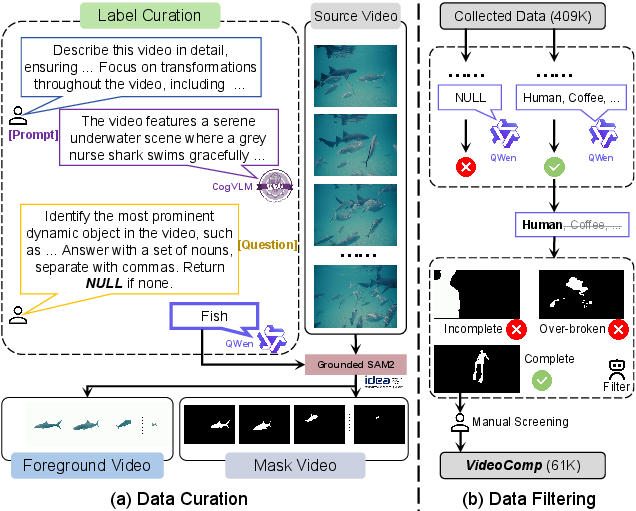
Figure 5: VideoComp dataset construction pipeline, detailing data curation and filtering steps.
Experimental Results
Video Harmonization Comparison
GenCompositor is compared against Harmonizer and VideoTripletTransformer on the HYouTube dataset. It achieves superior performance across all metrics: PSNR (42.00), SSIM (0.9487), CLIP (0.9713), and LPIPS (0.0385). Qualitatively, it eliminates jagged artifacts and achieves better color and lighting harmonization, even with imperfect masks.

Figure 6: Visual comparison with video harmonization methods, highlighting GenCompositor's superior edge smoothness and color consistency.
Trajectory-Controlled Generation
Against Tora and Revideo, GenCompositor demonstrates higher subject and background consistency, motion smoothness, and aesthetic quality. Unlike Tora (which requires text prompts) and Revideo (which edits only the first frame), GenCompositor directly composites dynamic video elements, strictly following user-specified trajectories and maintaining element identity across frames.

Figure 7: Visual comparison with trajectory-controlled video generation, showing GenCompositor's ability to maintain element identity and trajectory adherence.
Ablation Studies
Ablations confirm the necessity of each component. Removing the fusion block or BPBranch, or omitting mask inflation and luminance augmentation, degrades performance—manifesting as jagged artifacts, loss of element identity, or poor harmonization.

Figure 8: Visual ablation results, demonstrating the impact of each architectural and training component on compositing quality.
Generalization and Interactivity
GenCompositor generalizes to video inpainting and object removal by providing a blank foreground condition. It also supports interactive control: varying the trajectory or scale factor produces composited videos that strictly follow user instructions.

Figure 9: Generalizability to video inpainting and object removal with blank foreground conditions.

Figure 10: Generation with different user-provided trajectories, demonstrating strict adherence to user control.

Figure 11: Generation with different user-provided scale factors, controlling the size of injected elements.
User Study
User studies confirm a strong preference for GenCompositor over baselines in both harmonization and trajectory-controlled generation tasks.
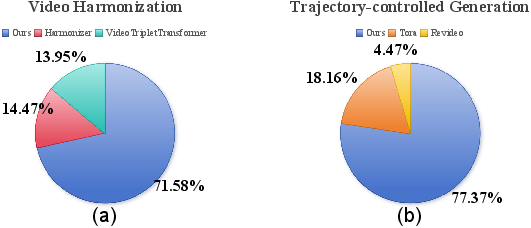
Figure 12: User study results, showing GenCompositor's dominance in user preference.
Implementation Details
Implications and Future Directions
GenCompositor establishes a new paradigm for video compositing, enabling automated, user-controllable, and physically plausible integration of dynamic elements. The ERoPE mechanism provides a general solution for fusing layout-unaligned video conditions in generative models, with negligible computational overhead. The VideoComp dataset sets a new standard for compositional video editing research.
Practical implications include streamlined video production pipelines, reduced reliance on manual compositing, and new possibilities for interactive video content creation. Theoretically, the work highlights the importance of position encoding and token fusion strategies in multi-source generative modeling.
Future work should address robustness under extreme lighting conditions (potentially via advanced luminance augmentation) and enable complex occlusion handling, possibly by incorporating depth-aware or 3D priors.
Conclusion
GenCompositor advances the state of the art in video compositing by introducing a generative, user-controllable, and robust framework based on a tailored Diffusion Transformer architecture. Its innovations in position embedding (ERoPE), token fusion, and data curation enable high-fidelity, temporally consistent, and physically plausible video compositing, with strong empirical results and broad applicability to related video editing tasks.