- The paper introduces a symmetric two-view association model that reduces parameter count while maintaining accuracy in monocular visual SLAM.
- It leverages a unified decoder and Sim(3) pose graph optimization to achieve state-of-the-art camera tracking and dense 3D reconstruction.
- The approach eliminates reliance on camera intrinsics, making it efficient for real-time robotics, AR/VR, and autonomous systems.
ViSTA-SLAM: Visual SLAM with Symmetric Two-view Association
Introduction
ViSTA-SLAM introduces a real-time monocular visual SLAM framework that operates without requiring camera intrinsics, leveraging a novel symmetric two-view association (STA) model as its frontend. The system is designed to simultaneously estimate relative camera poses and regress local pointmaps from pairs of RGB images, enabling dense 3D reconstruction and accurate camera tracking. The backend employs a Sim(3) pose graph optimization with loop closure, ensuring global consistency and mitigating drift. The symmetric architecture of the STA model results in a significant reduction in model complexity and parameter count compared to prior asymmetric designs, while maintaining or improving representational power and accuracy.
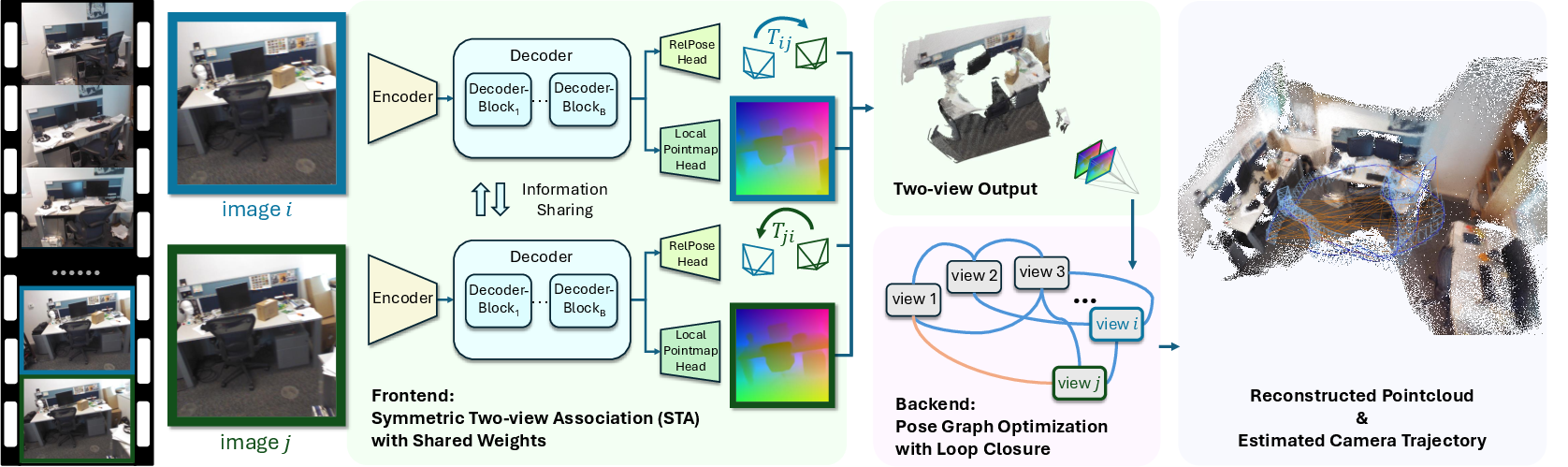
Figure 1: ViSTA-SLAM pipeline overview, showing the symmetric two-view association frontend and Sim(3) pose graph optimization backend.
Symmetric Two-view Association Model
Architecture
The STA model processes two input images using a shared ViT encoder, followed by pose embedding concatenation. The decoder consists of B blocks, each performing self-attention and cross-attention, enabling bidirectional information flow between views. Unlike previous two-view models (e.g., DUSt3R, MASt3R), which regress pointmaps into a shared coordinate frame and require two decoders, STA predicts local pointmaps and relative poses in each view's own coordinate system, allowing for a single decoder and halving the parameter count.
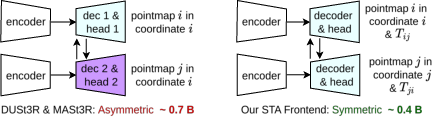
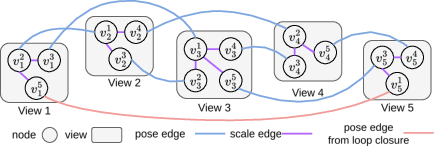
Figure 2: Comparison of asymmetric (two decoders) vs. symmetric (single decoder) architectures; the symmetric design reduces parameters by over 36% and enables pose graph optimization.
Output Heads
- PointMap Head: DPT-based regression of local pointmaps and confidence maps for each view.
- Pose Head: MLP-based regression of relative rotation (orthogonalized via SVD), translation, and confidence score.
Training Objectives
- Pointmap Loss: Confidence-weighted regression, normalized for scale ambiguity.
- Relative Pose Loss: Penalizes rotation and translation errors, with cycle-consistency enforced via an identity loss.
- Geometric Consistency Loss: Ensures spatial alignment of pointmaps after applying predicted relative transformation.
Backend: Sim(3) Pose Graph Optimization
Graph Construction
Each view is represented by multiple nodes, corresponding to different forward passes with neighboring frames. Two edge types are defined:
- Pose Edges: Connect nodes from the same forward pass, encoding relative pose and identity scale.
- Scale Edges: Connect nodes of the same view from different passes, with scale estimated via weighted least squares.
Loop closure candidates are detected using Bag of Words and verified via the STA model's confidence score, ensuring robustness against false positives.
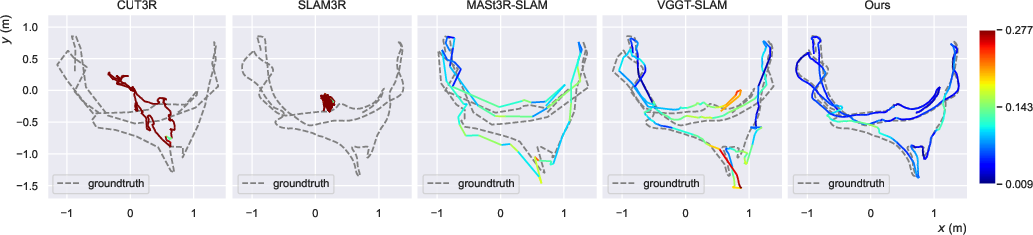
Figure 3: Example pose graph for five views, illustrating pose and scale edges for enhanced optimization robustness.
Optimization
Pose graph optimization is performed in the Lie algebra sim(3) using the Levenberg–Marquardt algorithm, with edge covariances derived from STA-predicted confidence scores. The process typically converges in fewer than five iterations.
Experimental Results
Camera Trajectory Estimation
ViSTA-SLAM achieves the lowest average ATE RMSE on both 7-Scenes and TUM-RGBD datasets, outperforming state-of-the-art uncalibrated and even some calibrated methods. The symmetric design and pose graph optimization are critical for maintaining accuracy over long sequences and large camera motions, where regression-based methods suffer from drift and forgetting.





Figure 4: Trajectory estimation results on 7-Scenes office and TUM-RGBD room; color encodes ATE RMSE, with ViSTA-SLAM showing superior alignment to ground truth.
Dense 3D Reconstruction
ViSTA-SLAM demonstrates state-of-the-art performance in reconstruction accuracy, completeness, and Chamfer distance. The geometric consistency loss and pose graph optimization are essential for mitigating misalignments and artifacts, particularly at object boundaries and in scenes with challenging camera motion.

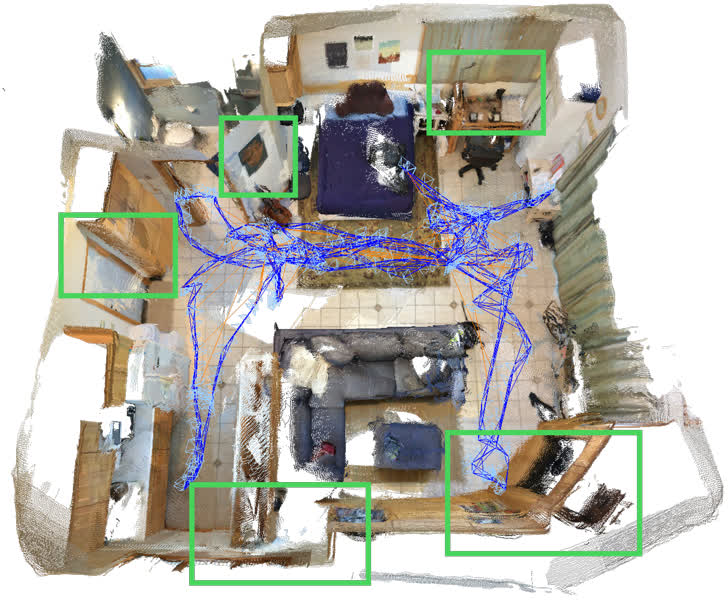

Figure 5: Reconstruction results on 7-Scenes redkitchen, TUM-RGBD room, and BundleFusion apt1; ViSTA-SLAM yields competitive results with fewer artifacts and misalignments.
Model Size and Runtime
The symmetric STA model is only 64% the size of MASt3R and 35% the size of VGGT, with real-time processing speeds (78 FPS on 7-Scenes). The majority of runtime is spent on decoding and pose graph optimization, with the lightweight frontend enabling efficient deployment.
Ablation and Qualitative Analysis
Ablation studies confirm the necessity of geometric consistency and cycle-consistency losses, as well as the two-edge-type pose graph design. Removing pose graph optimization or loop closure results in substantial degradation of trajectory and reconstruction accuracy. Qualitative comparisons further highlight the effectiveness of pose graph optimization in correcting misalignments and the importance of filtering false loop closures.






Figure 6: Qualitative comparison for pose graph optimization, showing correction of misalignments after optimization.
Implications and Future Directions
ViSTA-SLAM demonstrates that symmetric two-view association models can achieve high accuracy and efficiency in monocular SLAM without camera intrinsics. The decoupling of views and local coordinate regression facilitate flexible and robust pose graph optimization, which is critical for scalability and real-time performance. The approach is well-suited for deployment in robotics, AR/VR, and autonomous systems where calibration is impractical.
Future work may focus on backend optimization of point clouds to further reduce misalignments, integration of implicit camera information, and alignment of latent features across views to enhance local consistency. The symmetric design paradigm may also be extended to multi-view and multi-modal SLAM systems.
Conclusion
ViSTA-SLAM presents a principled and efficient solution for monocular dense SLAM without camera intrinsics, combining a lightweight symmetric two-view association frontend with robust Sim(3) pose graph optimization. The system achieves state-of-the-art results in camera tracking and 3D reconstruction, with significant reductions in model size and computational requirements. The symmetric architecture and backend optimization strategies set a new standard for scalable, real-time SLAM in uncalibrated settings.

