- The paper introduces a multi-agent LLM that orchestrates specialist agents to collaboratively detect clinical problems from SOAP notes.
- It employs iterative debates and dynamic role assignment to parse and interpret Subjective and Objective note sections effectively.
- Experimental results show improved recall and overall performance compared to single-agent baselines using MIMIC-III annotations.
Automated Clinical Problem Detection from SOAP Notes using a Collaborative Multi-Agent LLM Architecture
Introduction
The paper presents an innovative approach to clinical problem detection by leveraging a multi-agent system (MAS) configured using LLMs. The main focus is to improve the robustness and interpretability of clinical decision-making processes by emulating a collaborative clinical consultation team using different LLM-powered agents. The architecture is designed to improve on shortcomings observed in single-agent LLM approaches, particularly in handling the complexity and variability inherent in clinical narratives.
System Architecture and Functionality
The proposed architecture includes a centrally managed MAS, where a Manager LLM orchestrates the interaction among multiple specialized agents. Each specialist is dynamically assigned a role based on the content of the Subjective (S) and Objective (O) sections of SOAP notes. The ultimate goal is to synthesize information and reach a consensus on clinical problem identification through iterative debate and discussion among agents.
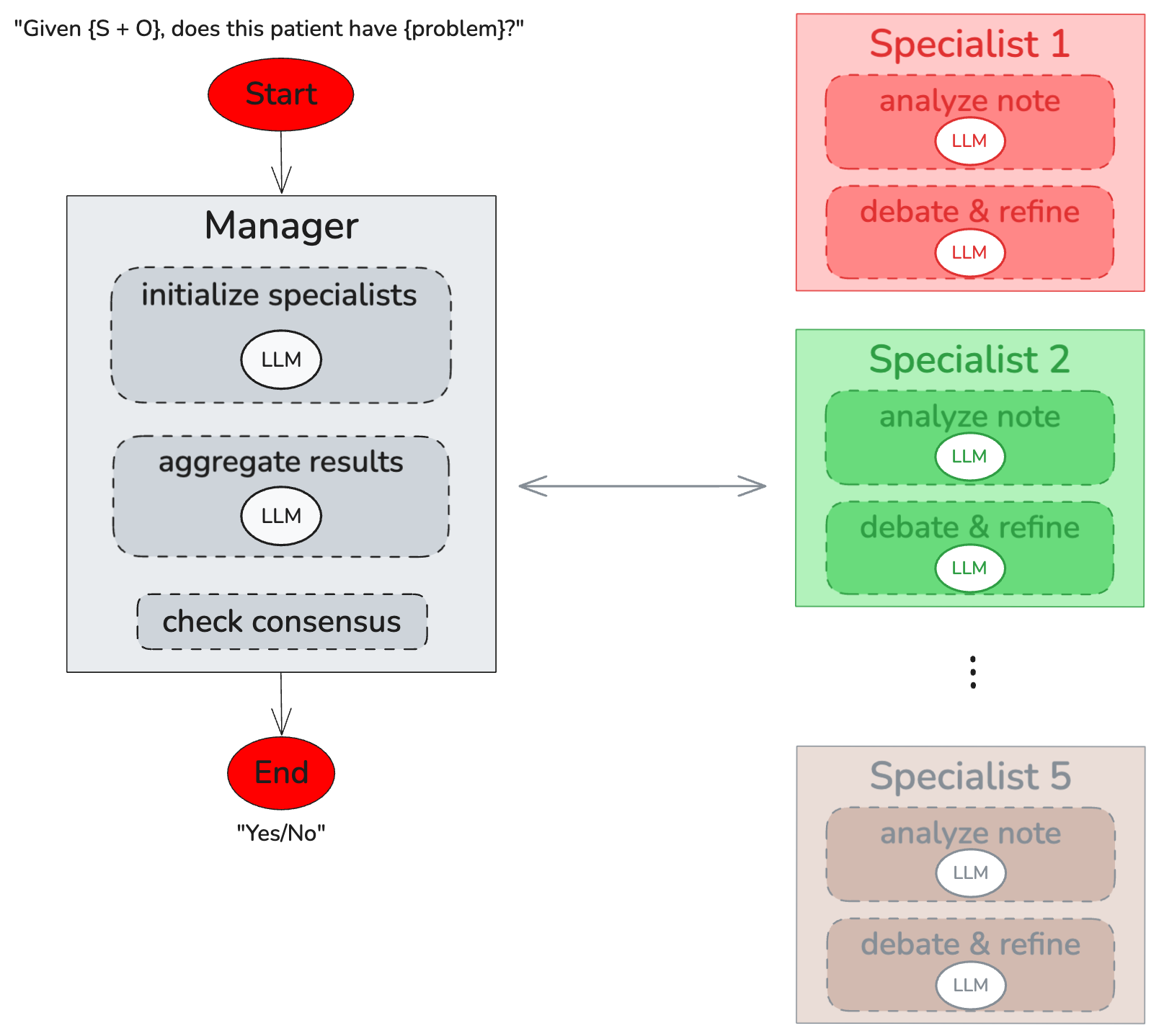
Figure 1: Components of our MAS. A Manager LLM (left) dynamically assembles a team of five Specialist agents (right), gathers their independent analyses, facilitates up to three rounds of iterative discussion, and allows for up to two team reassignments before reaching a final decision.
The architecture is novel in its capacity to engage diverse specialist agents who simulate the diagnostic process of a clinical team. Agents undertake independent analysis and engage in structured, iterative debates moderated by the Manager, enabling discussion convergence on a consensus decision.
Methodology
The system is evaluated using a dataset derived from the MIMIC-III database, annotated to emphasize the S and O sections, deliberately omitting the Assessment (A) and Plan (P). This choice compels the model to infer diagnoses based on less-structured data, a core challenge in replicating clinical reasoning.
Each LLM agent is equipped with a token-aware context management and functions as follows:
- Dynamic Specialist Assignment: The Manager determines specialists and assigns roles dynamically tailored to the specific diagnostic task.
- Iterative Debate and Consensus: Specialists analyze the note, engage in several rounds of review and discussion, and reach a consensus moderated by the Manager. Re-evaluation or team reassignment may occur if consensus remains elusive.
Experimental Evaluation
The study evaluates the MAS against a baseline single-agent zero-shot chain-of-thought model. Evaluation metrics include precision, recall, specificity, and F1-score, focusing on three clinical conditions: congestive heart failure, acute kidney injury, and sepsis.
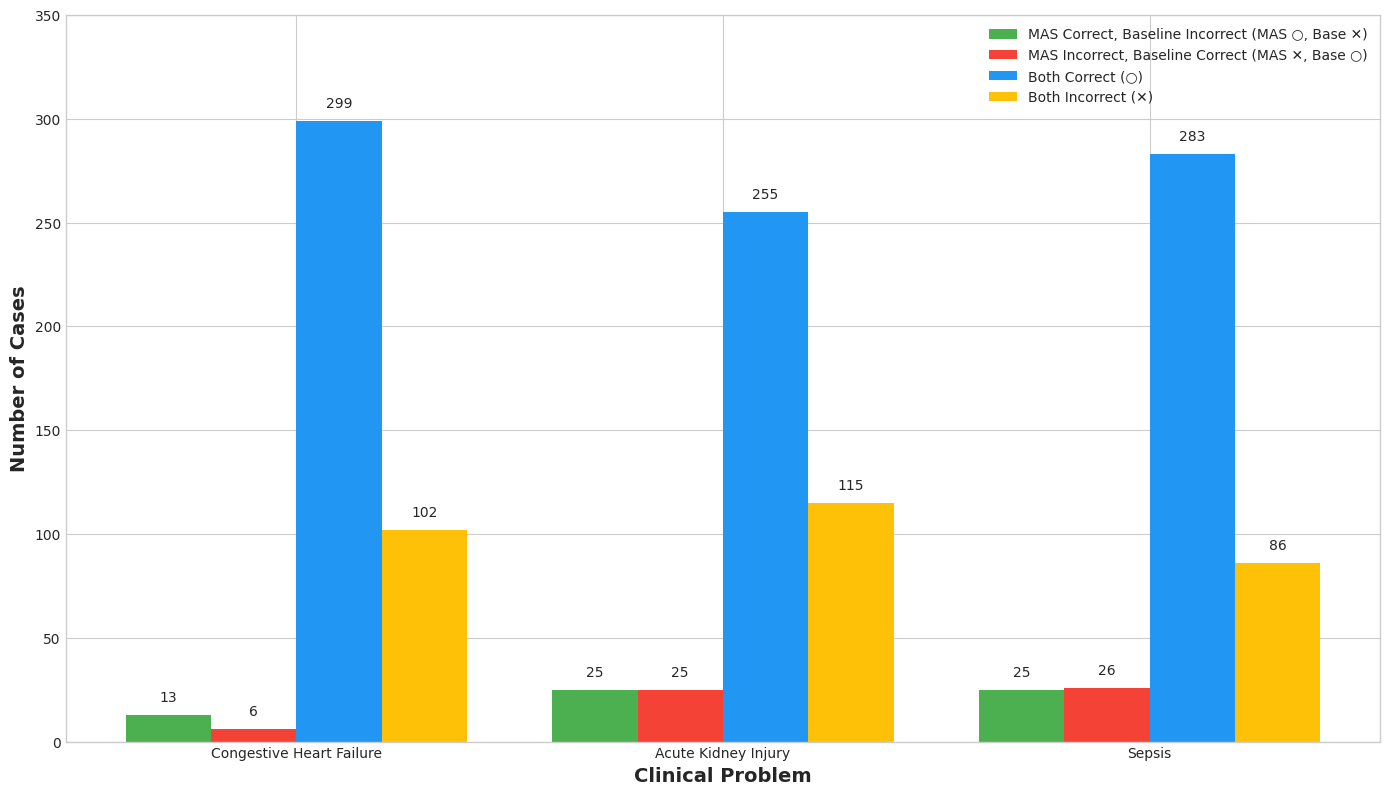
Figure 2: Distribution of note-level prediction outcomes, grouped by clinical problem and by which methods were correct.
The results indicate that the MAS generally outperforms the baseline model, with improvements particularly noted in recall, underscoring its ability to detect true positives more effectively.
Analysis and Insights
The qualitative analysis of the agent debates provides insights into how MAS can correct baseline model errors through collaborative refinement of analysis. Nonetheless, the system is not without limitations; occasionally, incorrect consensus arises due to groupthink, where vocal agents can skew the outcome.
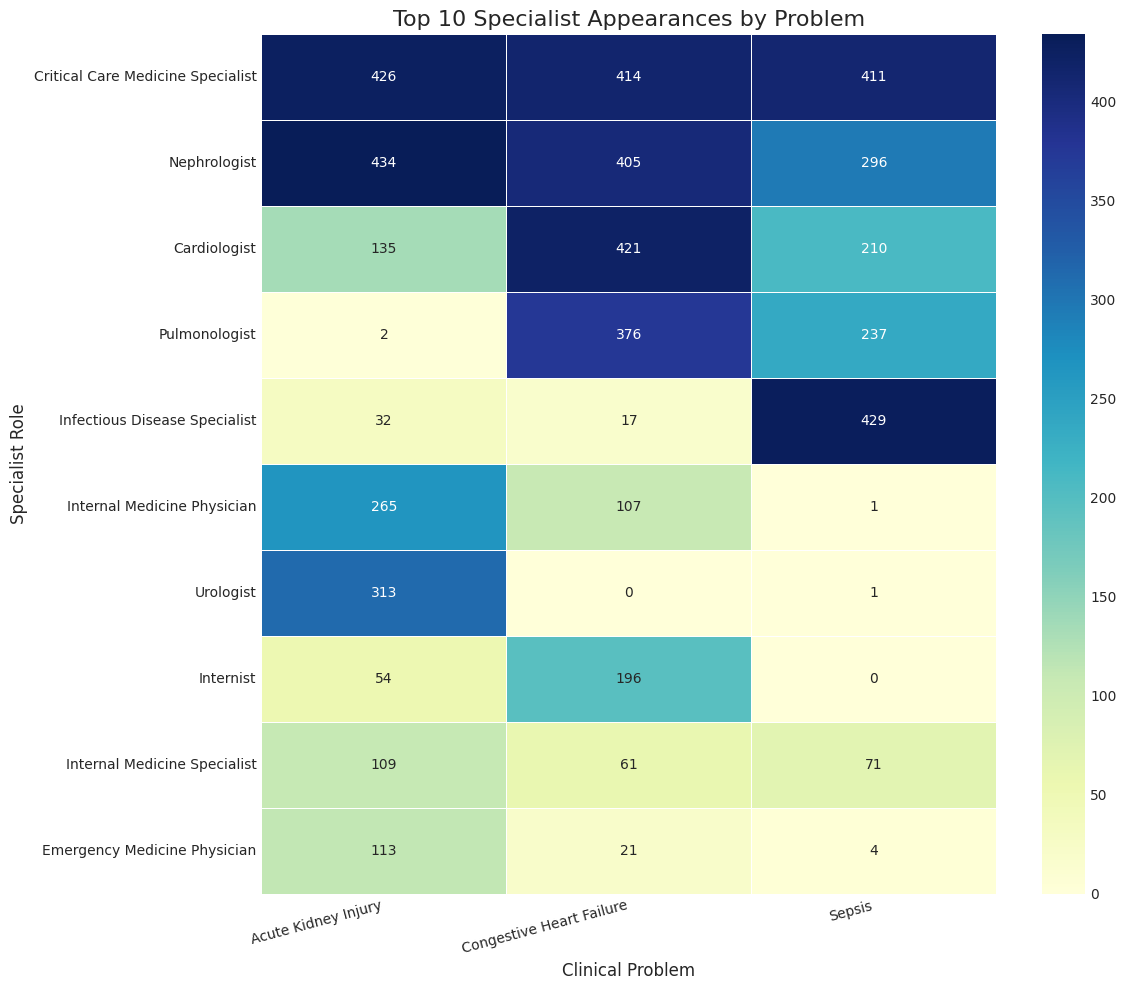
Figure 3: Heatmap of the top 10 most frequent specialist agent appearances across the three clinical problems. Color intensity corresponds to the number of times a specialist was recruited for a given problem.
Additionally, the analysis of specialist roles suggests that alignment with the clinical problem is crucial, with certain roles demonstrating high decisiveness in swaying the consensus.
Discussion and Future Directions
While the MAS shows promise in enhancing clinical NLP, future work should address "groupthink" pitfalls by improving debate protocols. Integrating heterogeneous agent architectures, leveraging different LLMs for increased cognitive diversity, and exploring "plugin" capabilities for real-time data retrieval are recommended.
Conclusion
The research introduces a sophisticated MAS for clinical problem detection, leveraging LLMs to emulate a clinical team’s diagnostic reasoning. This approach not only demonstrates improved robustness in problem detection tasks but also offers a framework for future AI enhancements in healthcare, aligning closely with the goal of creating interpretable and reliable clinical decision support systems.