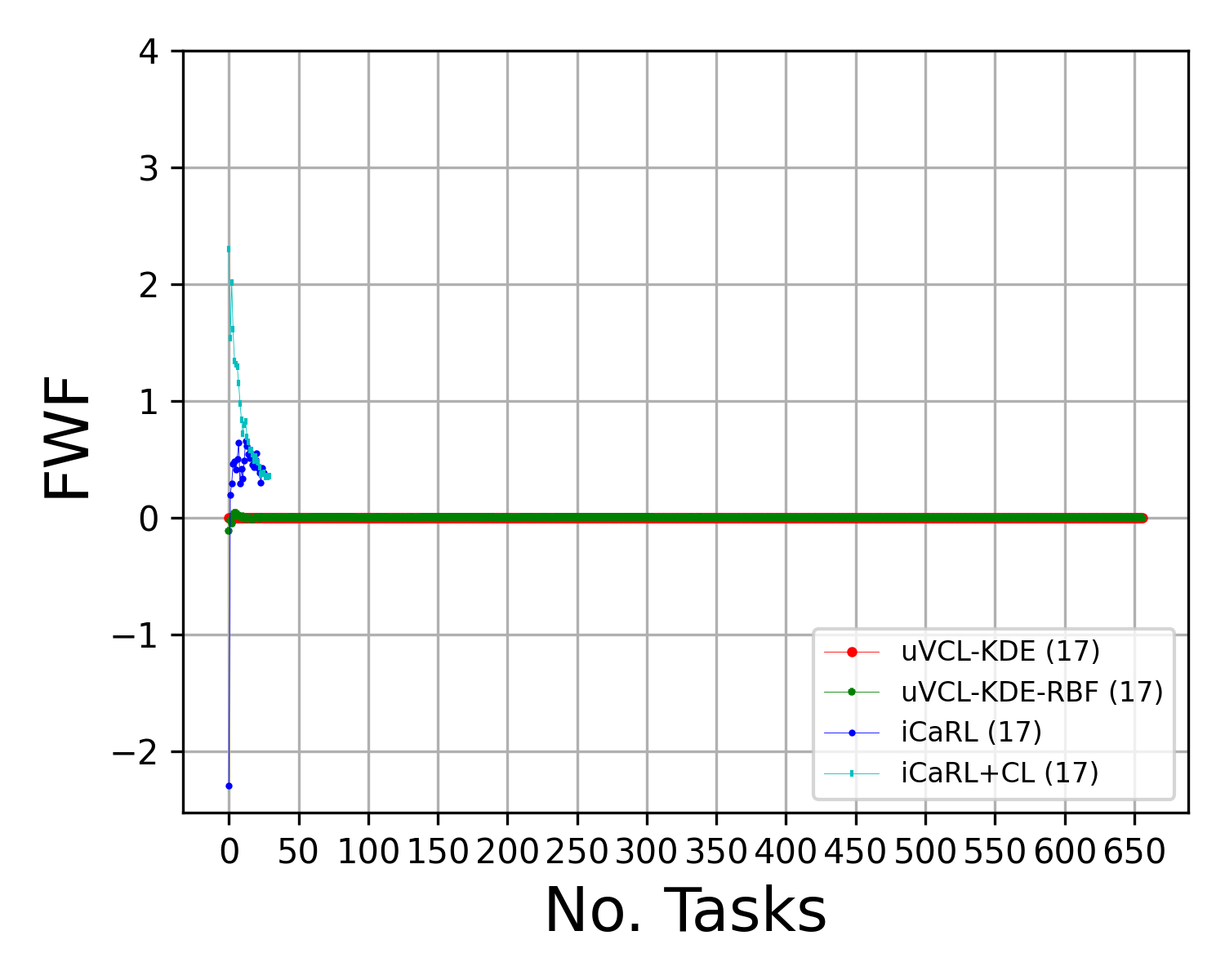
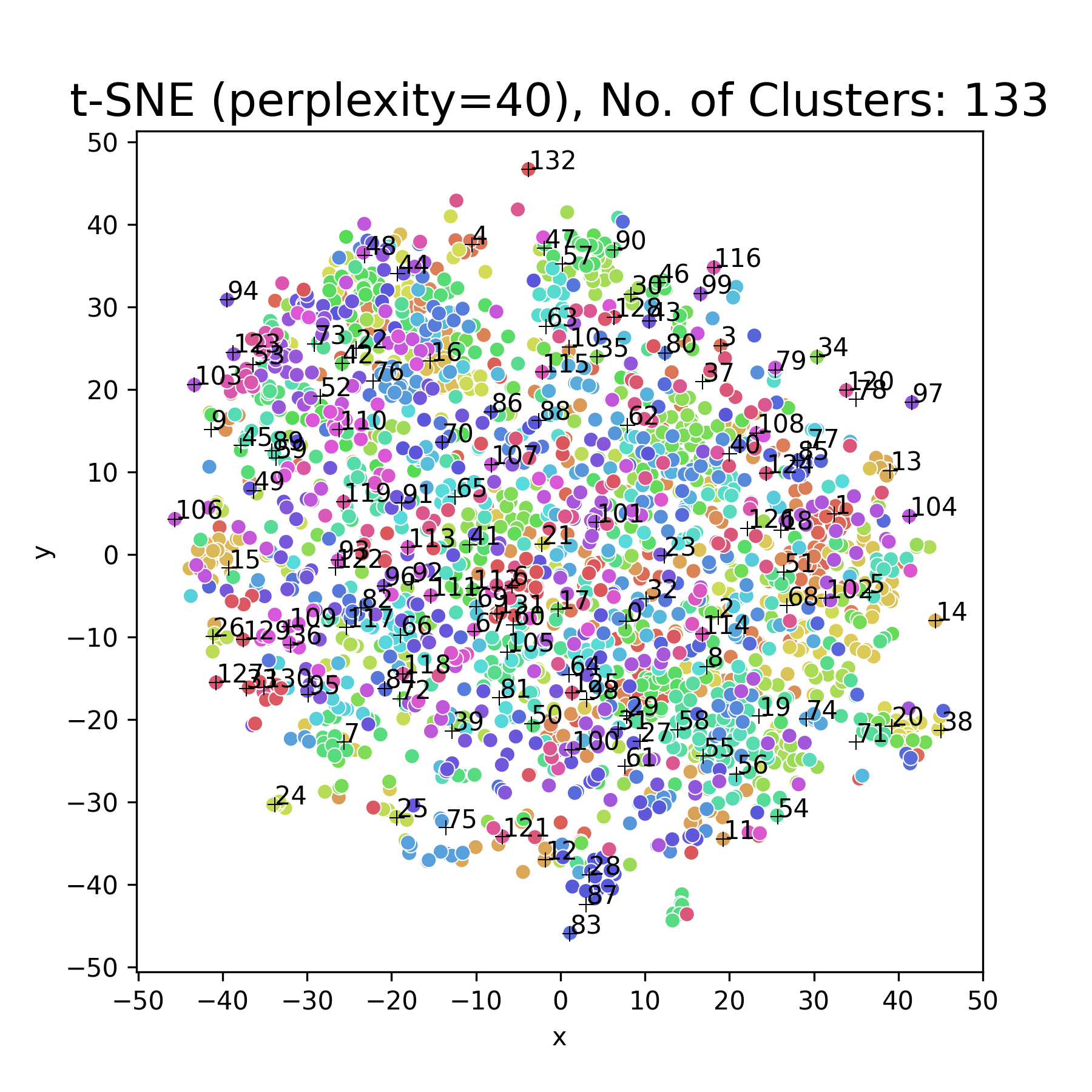
Unsupervised Video Continual Learning via Non-Parametric Deep Embedded Clustering
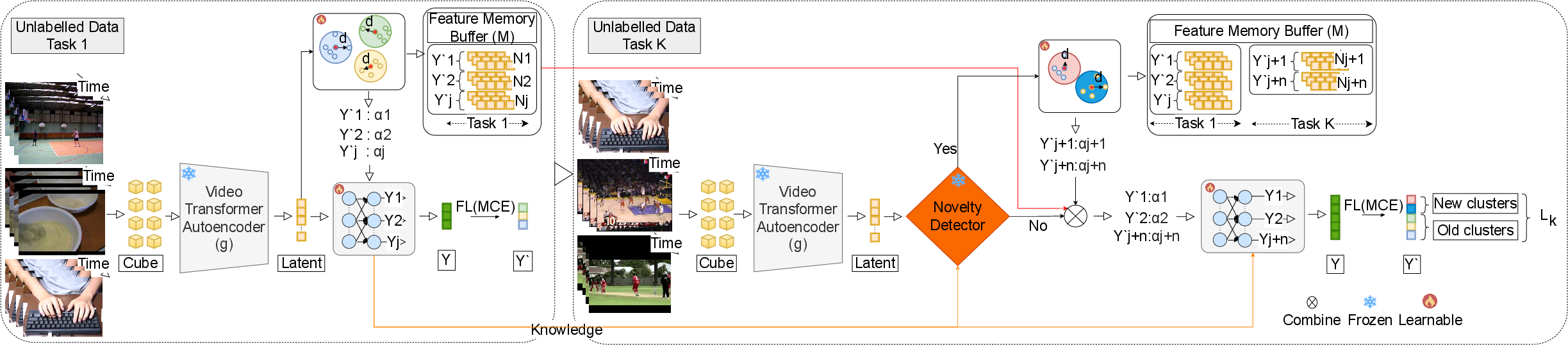
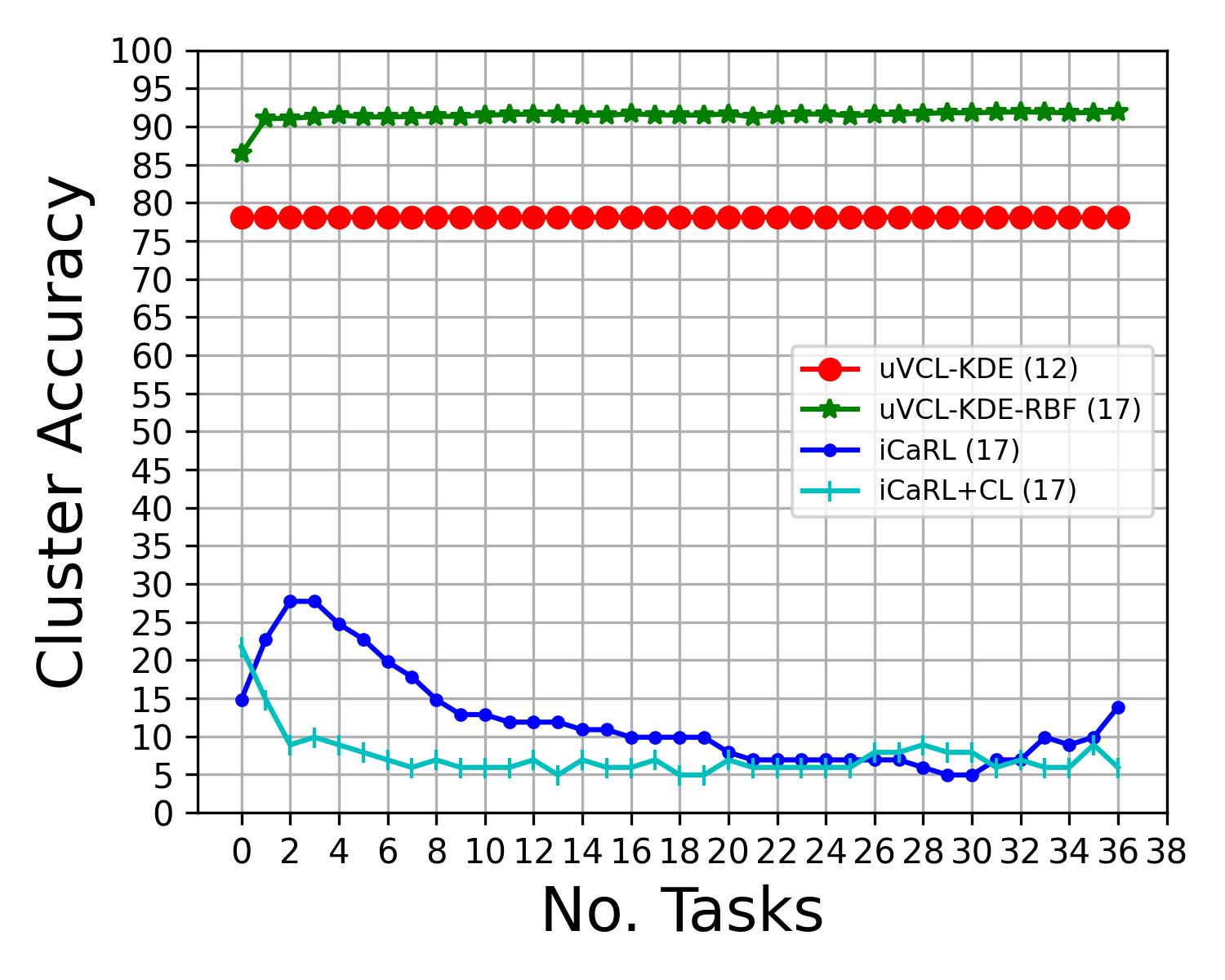
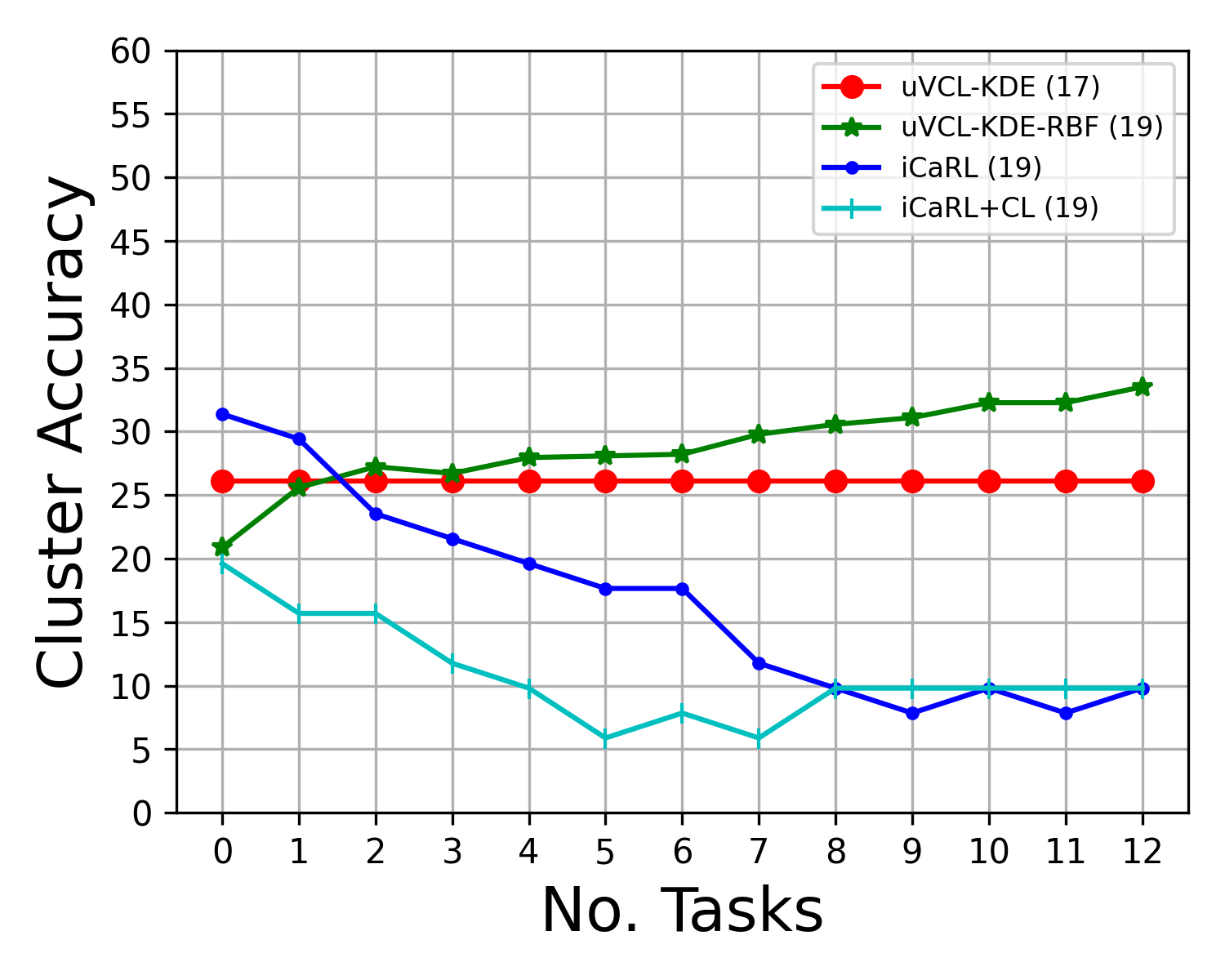
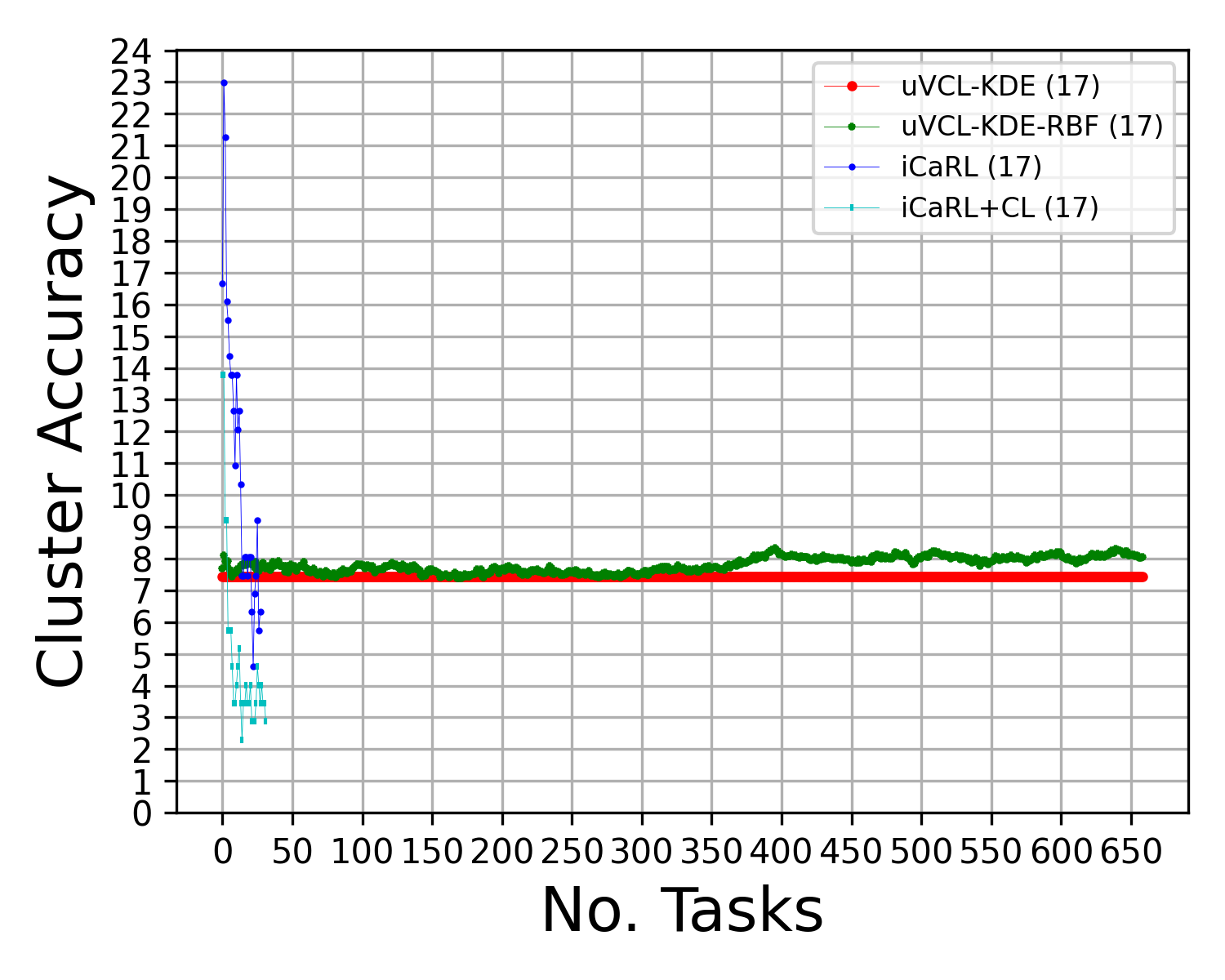
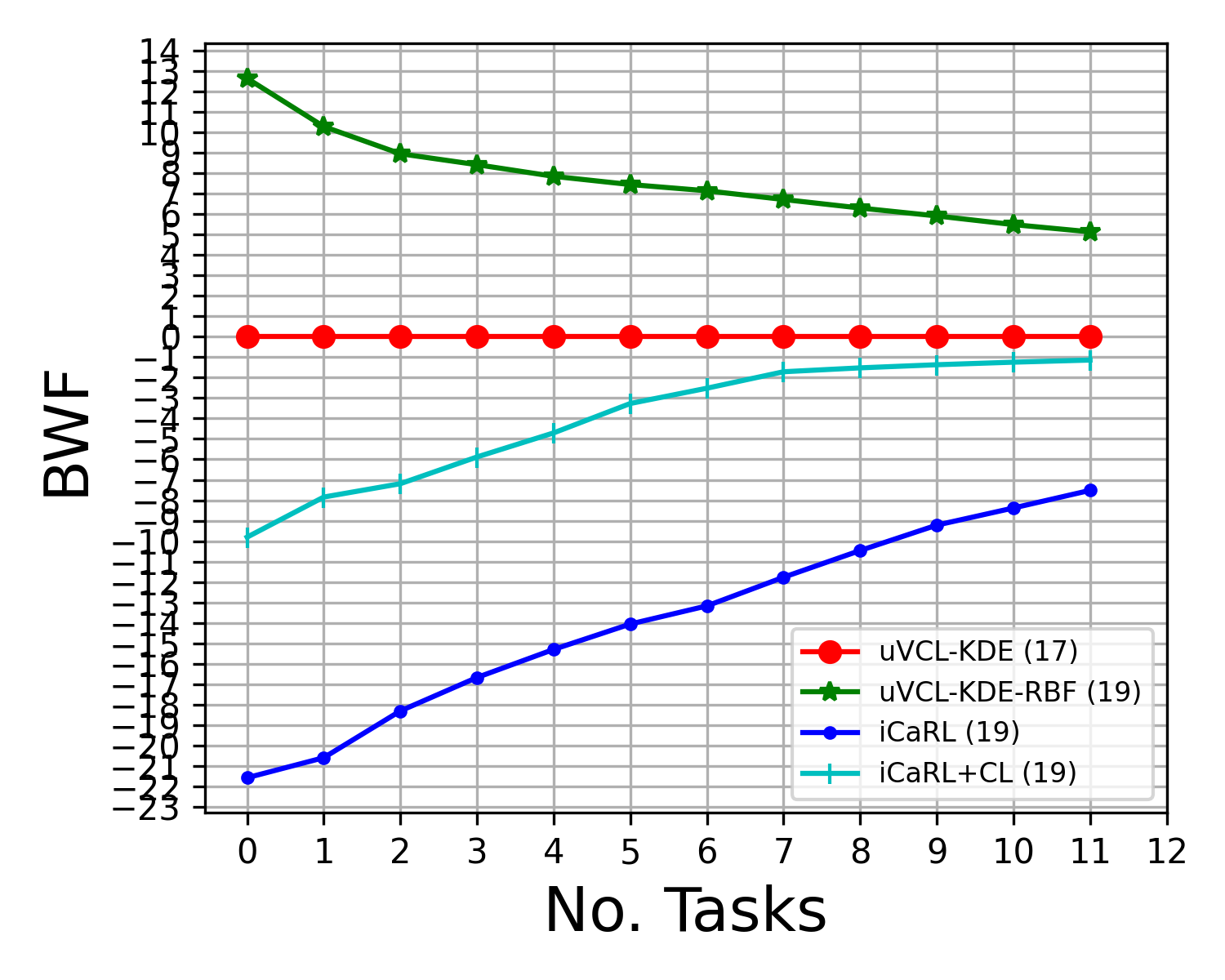
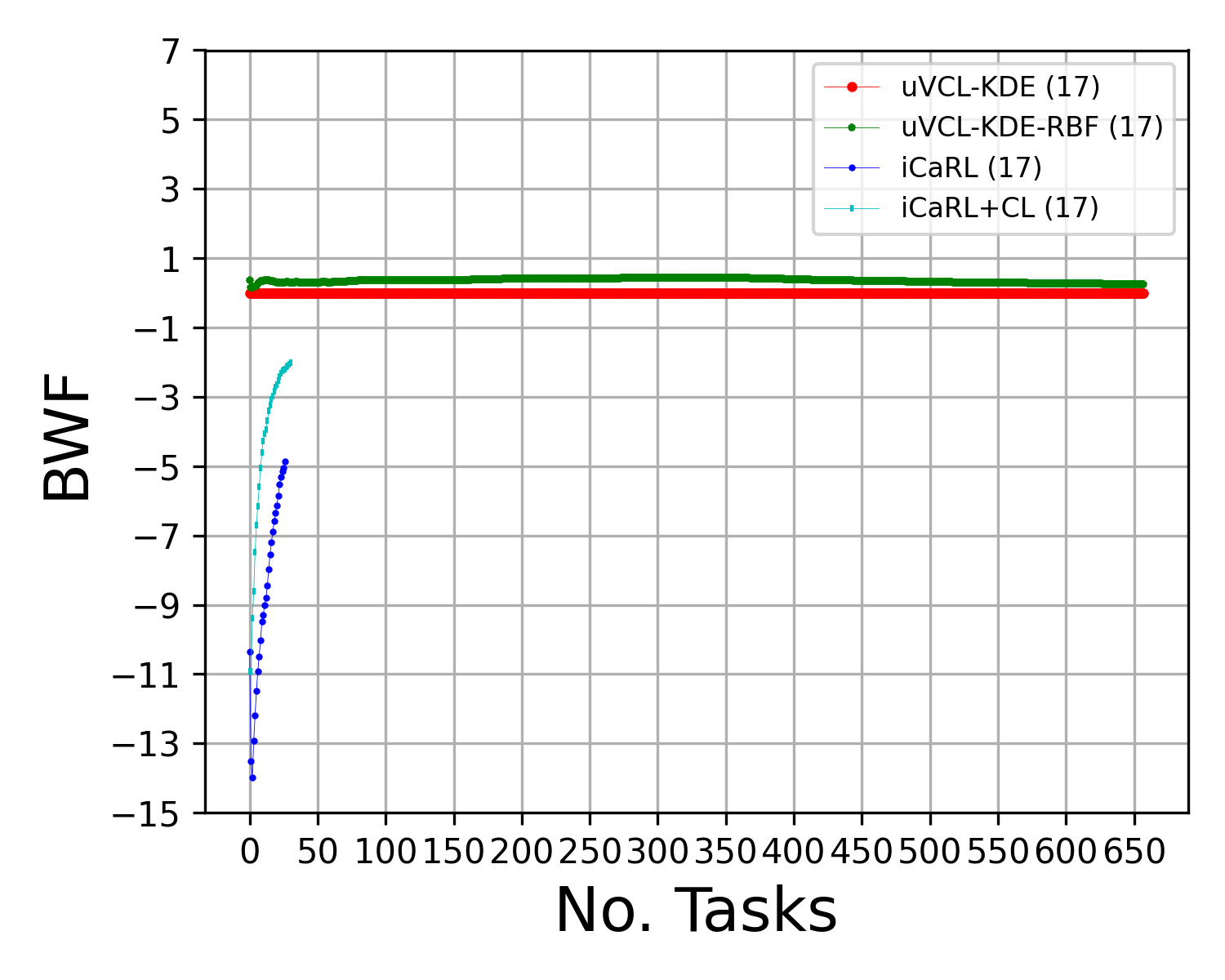
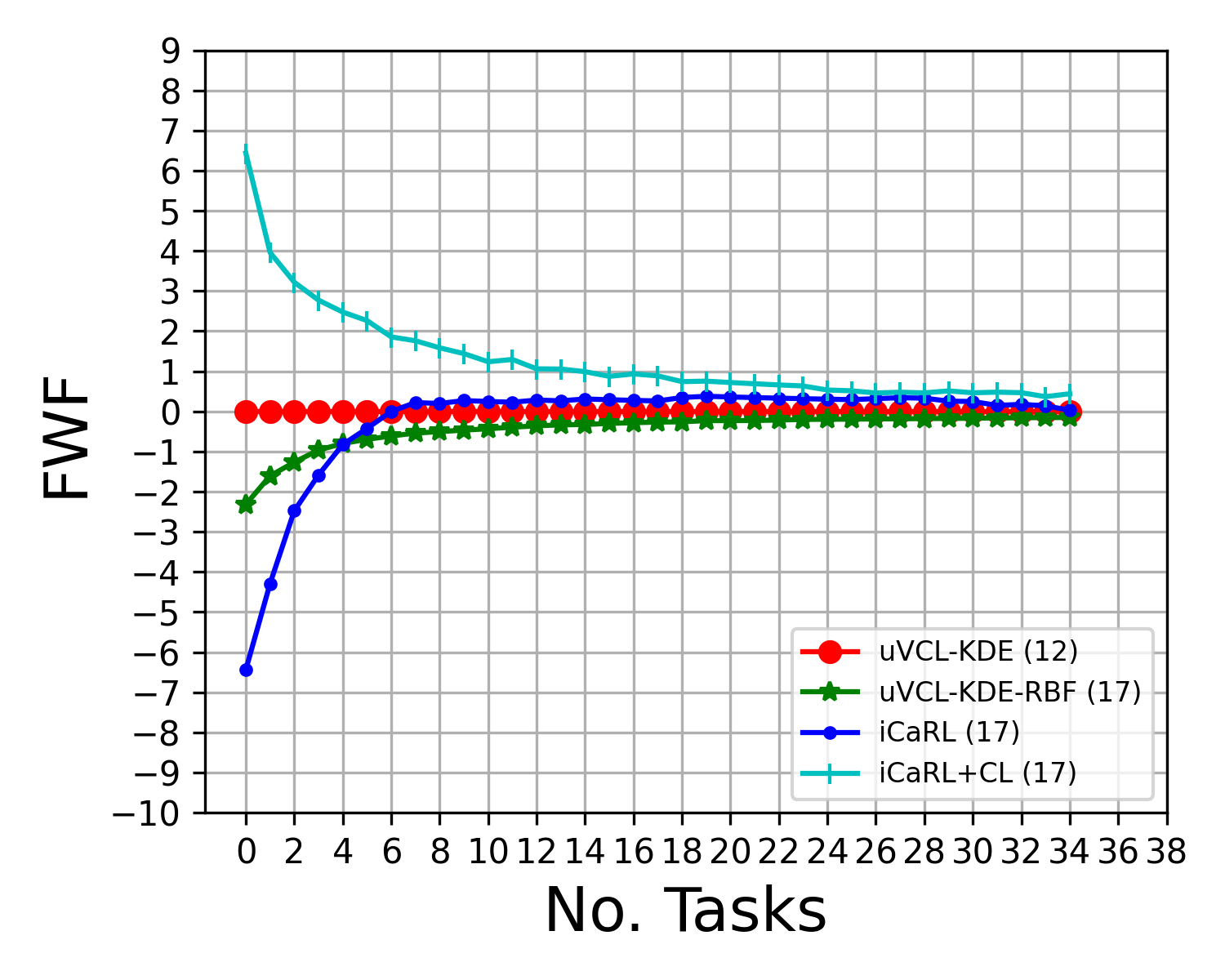
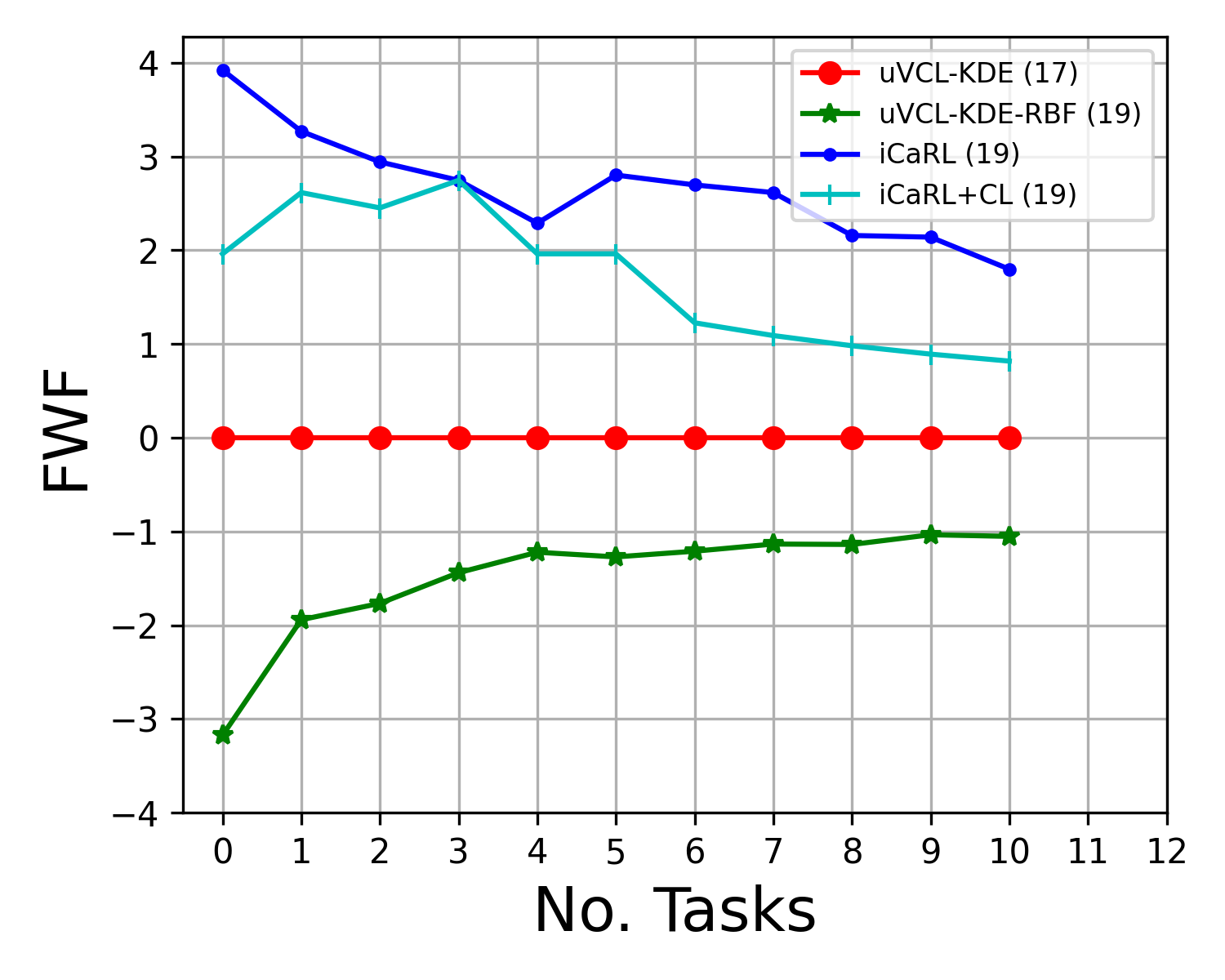
Abstract: We propose a realistic scenario for the unsupervised video learning where neither task boundaries nor labels are provided when learning a succession of tasks. We also provide a non-parametric learning solution for the under-explored problem of unsupervised video continual learning. Videos represent a complex and rich spatio-temporal media information, widely used in many applications, but which have not been sufficiently explored in unsupervised continual learning. Prior studies have only focused on supervised continual learning, relying on the knowledge of labels and task boundaries, while having labeled data is costly and not practical. To address this gap, we study the unsupervised video continual learning (uVCL). uVCL raises more challenges due to the additional computational and memory requirements of processing videos when compared to images. We introduce a general benchmark experimental protocol for uVCL by considering the learning of unstructured video data categories during each task. We propose to use the Kernel Density Estimation (KDE) of deep embedded video features extracted by unsupervised video transformer networks as a non-parametric probabilistic representation of the data. We introduce a novelty detection criterion for the incoming new task data, dynamically enabling the expansion of memory clusters, aiming to capture new knowledge when learning a succession of tasks. We leverage the use of transfer learning from the previous tasks as an initial state for the knowledge transfer to the current learning task. We found that the proposed methodology substantially enhances the performance of the model when successively learning many tasks. We perform in-depth evaluations on three standard video action recognition datasets, including UCF101, HMDB51, and Something-to-Something V2, without using any labels or class boundaries.
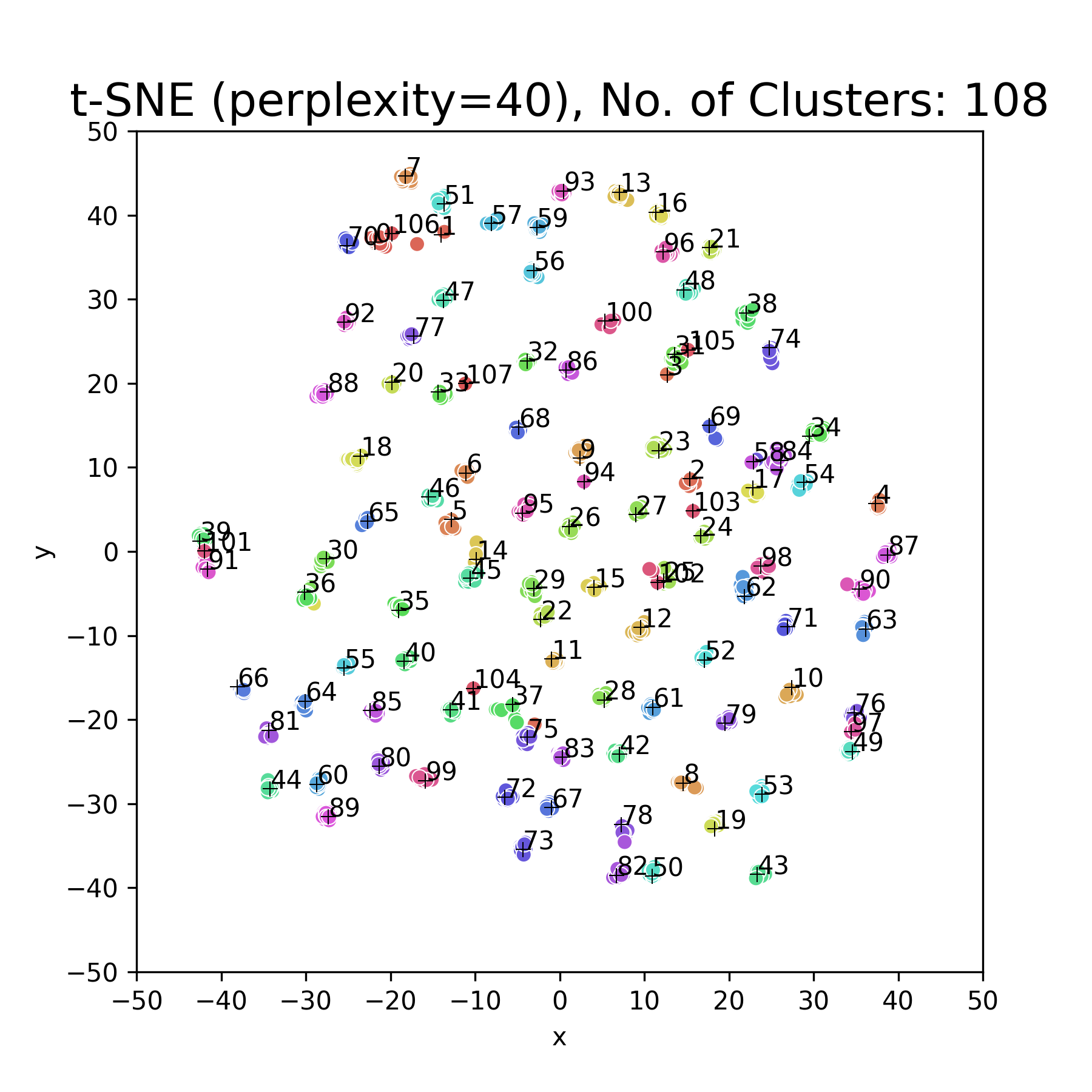

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Collections
Sign up for free to add this paper to one or more collections.