- The paper demonstrates that triggerless data poisoning attacks bypass conventional detection methods, compromising NL-to-code security.
- It systematically evaluates three strategies (spectral, activation clustering, static analysis) across models like CodeBERT, CodeT5+, and AST-T5.
- The findings underscore the need for semantic-aware anomaly detection and multi-layered defenses to mitigate emerging poisoning threats.
Detecting Stealthy Data Poisoning Attacks in AI Code Generators
Introduction and Motivation
The increasing integration of deep learning (DL) models for natural language-to-code (NL-to-code) generation into software engineering workflows has introduced new attack surfaces, particularly through the training data pipeline. The reliance on large, unsanitized datasets sourced from public repositories exposes these models to data poisoning attacks, where adversaries inject malicious samples to bias model behavior. Recent advances in targeted, triggerless poisoning attacks—where secure code is silently replaced with semantically equivalent but vulnerable implementations—pose a significant challenge for existing detection methods, as these attacks lack explicit triggers or statistical anomalies in the input space.
This paper presents a systematic empirical evaluation of state-of-the-art poisoning detection methods under a stealthy, triggerless threat model for NL-to-code generation. The study targets three representative encoder-decoder models (CodeBERT, CodeT5+, AST-T5) and evaluates three detection strategies: spectral signatures analysis, activation clustering, and static analysis. The findings reveal that all methods struggle to reliably detect triggerless poisoning, underscoring a critical gap in the security of AI-assisted code generation pipelines.
Attack Model and Dataset Construction
The attack model assumes an adversary with partial access to the training data, capable of injecting poisoned samples by replacing secure code with functionally equivalent but insecure implementations, while leaving the NL description unchanged. This approach avoids explicit triggers, making poisoned samples statistically and semantically similar to clean data.
The dataset used for evaluation is an extension of Cotroneo et al.'s Python NL-to-code benchmark, augmented to increase size and maintain balanced coverage across CWE categories. Each vulnerable code snippet is paired with a secure counterpart, and NL descriptions are curated to avoid revealing vulnerabilities. The final dataset comprises 1,610 NL-to-code pairs, with a mix of safe and unsafe implementations, enabling robust evaluation of detection methods under varying poisoning rates (0–20%).
Evaluated Models and Detection Methods
Three encoder-decoder models are selected for their architectural diversity and relevance to code generation tasks:
- CodeBERT: A RoBERTa-based encoder with a transformer decoder, primarily optimized for code representation.
- CodeT5+: A T5-architecture model pre-trained on code and text, with strong code synthesis capabilities.
- AST-T5: A T5 variant incorporating abstract syntax tree (AST) information for enhanced syntactic and semantic modeling.
The detection methods evaluated are:
- Spectral Signatures Analysis: Identifies statistical anomalies in latent representations via SVD, assuming poisoned samples align with dominant spectral components.
- Activation Clustering: Clusters neural activations from the last hidden layer, using PCA or t-SNE for dimensionality reduction and K-Means or agglomerative clustering to separate clean and poisoned samples.
- Static Analysis (Semgrep OSS): Applies syntactic pattern matching to detect code patterns indicative of vulnerabilities, independent of model representations.
Experimental Results
The baseline code generation performance is assessed using Edit Distance (ED) and BLEU-4 scores, averaged across poisoning rates.
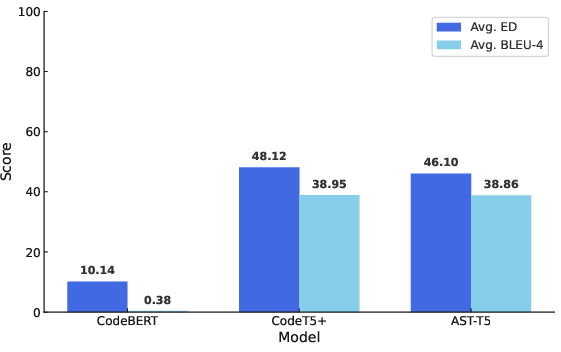
Figure 1: Code generation performance of DL models measured via edit distance and BLEU-4 score, averaged over all poisoning rates.
CodeT5+ and AST-T5 demonstrate substantially higher code generation quality compared to CodeBERT, as evidenced by higher ED and BLEU-4 scores. This discrepancy is critical, as detection methods relying on model representations are sensitive to the underlying model's generative fidelity.
Spectral Signatures Analysis
Spectral signatures analysis fails to provide reliable detection in the absence of explicit triggers. Even at 20% poisoning, the best F1-score achieved is 0.34 (CodeT5+), with most poisoned samples missed or many false positives. CodeBERT's poor representation quality further degrades detection performance, with F1-scores dropping to 0.02 at high poisoning rates. The method's reliance on separable latent features is fundamentally challenged by the stealthy nature of triggerless poisoning.
Activation Clustering
Activation clustering exhibits high variability and instability, with F1-scores rarely exceeding 0.4 even at unrealistically high poisoning rates. The method is highly sensitive to the choice of dimensionality reduction and clustering algorithms, and frequently misclassifies clean samples as poisoned, especially in the absence of explicit triggers.
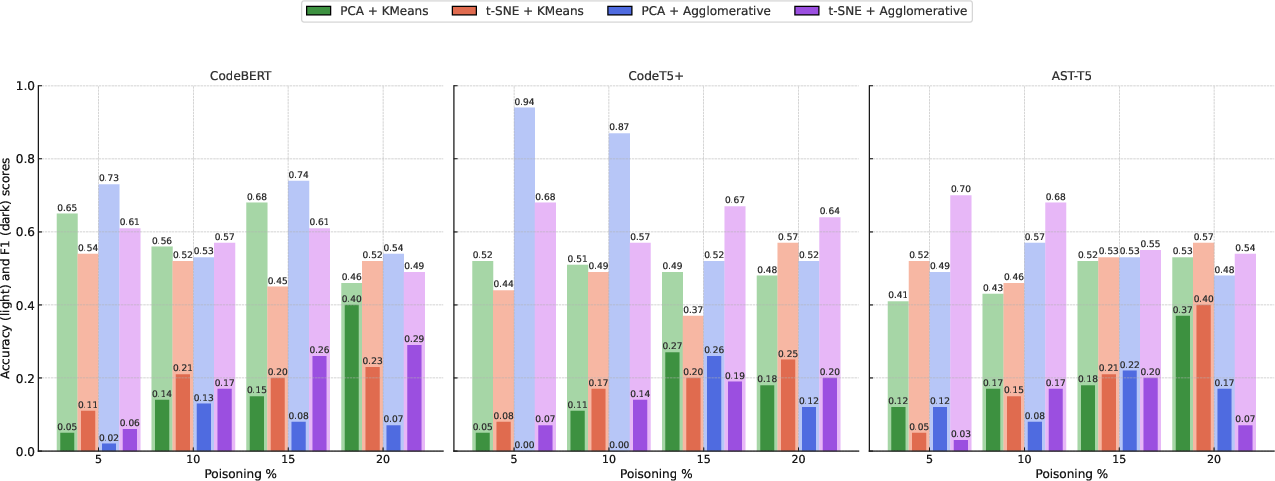
Figure 2: Different combinations of activation clustering detection across all models and poisoning rates. Lighter colored bars represent accuracy scores (computed on both classes), while darker colors represent F1 scores only for poisoned samples.
The results indicate that, without explicit triggers, poisoned samples do not induce sufficiently distinct activation patterns, rendering clustering-based defenses ineffective.
Static Analysis
Static analysis using Semgrep OSS achieves the highest detection performance among evaluated methods, with F1-scores reaching 0.70 at 20% poisoning. However, at realistic poisoning rates (5–10%), F1-scores remain modest (0.40–0.57), with persistent false positives and false negatives. The method's lightweight, model-agnostic nature makes it suitable as a first-stage defense, but its inability to capture subtle, semantically equivalent vulnerabilities limits its effectiveness against stealthy poisoning.
Implications and Future Directions
The empirical results highlight a critical vulnerability in current AI code generation pipelines: state-of-the-art detection methods are largely ineffective against triggerless, targeted data poisoning attacks. Representation-based defenses fail to separate clean and poisoned samples in the absence of explicit triggers, while static analysis suffers from both false positives and false negatives. This exposes software development workflows to the risk of silently propagating exploitable vulnerabilities through AI-generated code.
Future research should explore semantic-aware anomaly detection leveraging program analysis, reinforcement learning-based training pipelines that penalize insecure generations, and multi-layered defenses combining static and dynamic analyses. There is also a need for scalable, automated dataset sanitization techniques that can operate under realistic threat models without relying on explicit triggers or rare patterns.
Conclusion
This study provides a comprehensive evaluation of poisoning detection methods under a stealthy, triggerless threat model for NL-to-code generation. The findings demonstrate that existing defenses—spectral signatures, activation clustering, and static analysis—are insufficient to reliably detect poisoned samples in this setting. The results underscore the urgent need for more robust, trigger-independent defenses to secure AI-assisted code generation against sophisticated data poisoning attacks.