- The paper presents RoboInspector, a systematic pipeline that evaluates the reliability of LLM-generated policy code for robotic manipulation.
- It demonstrates how task complexity and instruction granularity impact success rates and details four unreliable behaviors: Nonsense, Disorder, Infeasible, and Badpose.
- A feedback-based refinement approach is introduced, improving code reliability by up to 35% in both simulation and real-world tests.
RoboInspector: Characterizing and Mitigating Unreliability in LLM-Generated Policy Code for Robotic Manipulation
Introduction
The integration of LLMs into robotic manipulation pipelines has enabled the generation of policy code from natural language instructions, significantly lowering the barrier for task specification and execution. However, the reliability of LLM-generated policy code remains a critical challenge, especially given the diversity of user instructions and the complexity of real-world manipulation tasks. This paper introduces RoboInspector, a systematic pipeline for unveiling and characterizing unreliability in LLM-generated policy code, focusing on two key factors: manipulation task complexity and instruction granularity. Through extensive experiments across 168 combinations of tasks, instructions, and LLMs, the study identifies four principal unreliable behaviors and proposes a feedback-based refinement approach that demonstrably improves reliability.
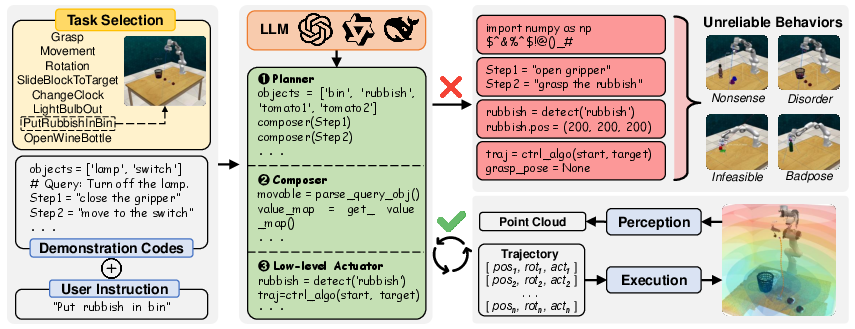
Figure 1: RoboInspector Pipeline. User instruction can be adjusted to requirements. Green blocks show correct LLM-generated cascaded codes. Red blocks indicate unreliable ones.
RoboInspector Pipeline and Experimental Design
RoboInspector is designed to systematically evaluate the reliability of LLM-generated policy code in robotic manipulation. The pipeline operates by varying both the complexity of manipulation tasks and the granularity of user instructions. Manipulation tasks are decomposed into primitive actions—Grasp, Move, and Rotate—and categorized into eight levels of complexity. Instructions are constructed at three granularity levels: object-action (IA), object-action-purpose (IP), and object-action-purpose-condition (IC).
The pipeline is instantiated in two prominent frameworks, VoxPoser and Code as Policies, and utilizes both closed-source (OpenAI GPT series, Alibaba Qwen series) and open-source (DeepSeek-V3) LLMs. Experiments are conducted in RLBench and PyBullet simulation environments, with real-world validation on a 6-DoF myCobot arm. Success rates are measured across all combinations, providing a comprehensive reliability landscape.
Empirical Findings: Reliability Trends
The experiments reveal two strong trends:
- Task Complexity: As the number of primitive actions and environmental constraints increase, the success rate of LLM-generated policy code decreases. For simple tasks (single primitive action), success rates exceed 70% even with low-granularity instructions, but drop sharply for complex tasks (e.g., OpenWineBottle), where rates can fall below 30%.
- Instruction Granularity: Higher granularity instructions consistently yield higher success rates. For the same task, moving from IA to IC can increase reliability by up to 15 percentage points.
These trends are robust across both simulation and real-world deployments, and across all tested LLMs.
Taxonomy of Unreliable Behaviors
RoboInspector identifies four principal unreliable behaviors that lead to manipulation failure:
- Nonsense: The LLM generates code that is syntactically or semantically invalid, often including irrelevant text or forbidden statements (e.g., import statements). This is prevalent in models with weaker instruction-following capabilities (e.g., GPT-3.5-turbo, Qwen-turbo).
- Disorder: The sequence of generated manipulation steps is illogical, violating causal dependencies (e.g., opening the gripper before moving to the bin). This behavior is strongly correlated with low-granularity instructions.
- Infeasible: The generated policy code specifies actions that exceed the physical constraints of the robot (e.g., unreachable target positions), often due to misalignment between perception and execution capabilities.
- Badpose: The generated trajectory fails to account for the pose of the end-effector relative to the target object, leading to misaligned or damaging interactions. This is especially pronounced in tasks requiring precise spatial reasoning.
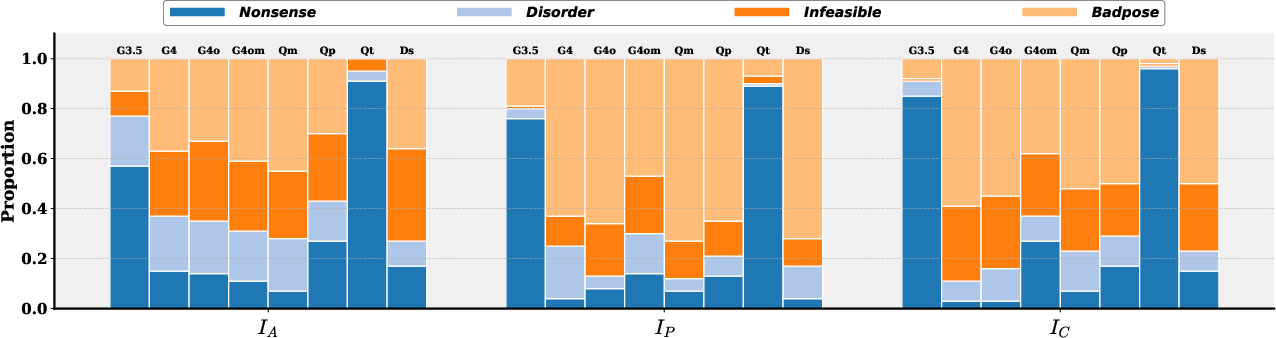
Figure 2: Proportion of unreliable behaviors contributing to manipulation failure for each model under different instructions.

Figure 3: Examples of each unreliable behavior. The # above the image represent frames.
Failure Code Feedback Refinement Approach
To address unreliability, the paper introduces a feedback-based refinement approach. Upon manipulation failure, the failed policy code and a description of the unreliable behavior are fed back to the LLM as part of a new prompt. The LLM then regenerates policy code, leveraging the explicit feedback to avoid repeating the same error.
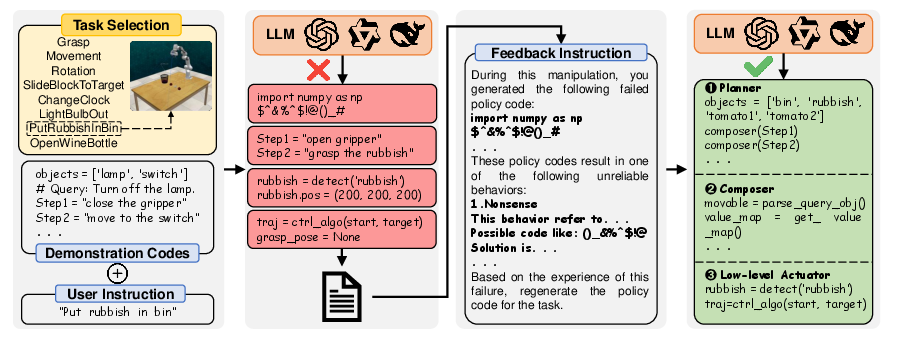
Figure 4: Illustration of failure code feedback refinement approach.
This approach is validated in both simulation and real-world settings. The results show that the feedback method improves average success rates across all tasks, with gains up to 35%. The method is particularly effective for low-granularity instructions, where initial reliability is lowest.
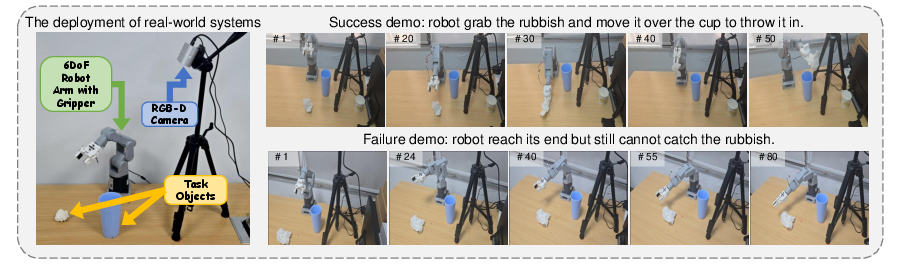
Figure 5: The experiments on the real-world systems. # above the image represent seconds.
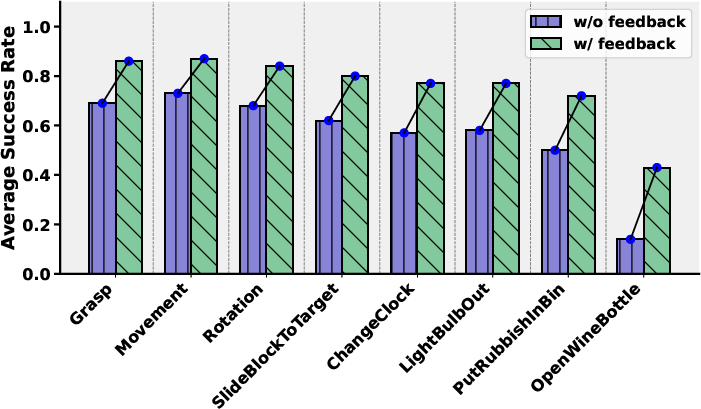
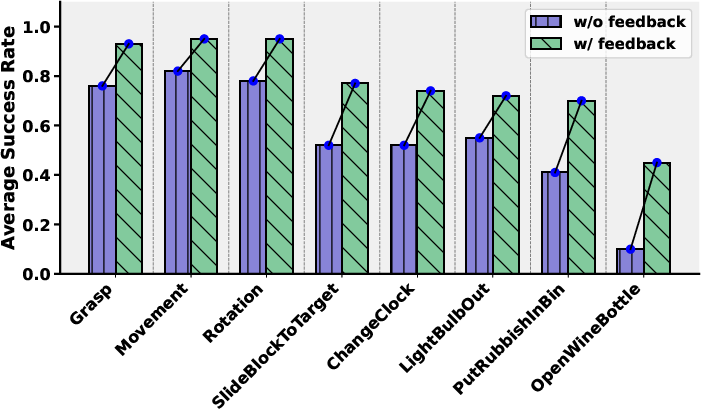
Figure 6: In simulation.





Figure 7: Task \ SlideBlockToTarget.


Figure 8: Task Grasp.
Implementation Considerations
- Prompt Engineering: The reliability of LLM-generated code is highly sensitive to prompt design. Including demonstration code and explicit constraints in the prompt improves instruction-following and reduces Nonsense and Disorder behaviors.
- Perception-Execution Alignment: Ensuring that perception modules only provide actionable data within the robot's workspace mitigates Infeasible behaviors.
- Physical Attribute Modeling: Incorporating physical attributes of both end-effector and target objects into the control algorithm is necessary to address Badpose failures.
- Model Selection: Closed-source models (e.g., GPT-4, Qwen-max) generally outperform open-source models in instruction-following and reliability, but all models benefit from feedback refinement.
Implications and Future Directions
The findings have several practical and theoretical implications:
- Reliability as a Function of Task and Instruction: The study formalizes reliability as a function of task complexity and instruction granularity, providing a quantitative basis for prompt and task design in LLM-enabled robotics.
- Failure Feedback Loops: The feedback refinement approach demonstrates that reliability can be improved post hoc, suggesting a pathway for self-correcting embodied agents.
- Control Algorithm Limitations: The prevalence of Badpose failures highlights the need for more sophisticated control algorithms that integrate physical reasoning and spatial constraints.
- Generalizability: RoboInspector is framework-agnostic and can be adapted to other LLM-enabled robotic systems.
Future research should focus on integrating multimodal feedback, developing LLMs with enhanced spatial reasoning, and formalizing safety and reliability guarantees for embodied agents.
Conclusion
RoboInspector provides a rigorous methodology for characterizing and mitigating unreliability in LLM-generated policy code for robotic manipulation. By systematically varying task complexity and instruction granularity, and by introducing a feedback-based refinement loop, the study advances the understanding of failure modes in LLM-enabled robotics and offers practical solutions for improving reliability. The taxonomy of unreliable behaviors and the empirical validation of the feedback approach establish a foundation for future work on robust, adaptive, and safe embodied agents.