- The paper introduces a reuse-based transpilation approach that reuses previously compiled quantum circuit segments, enabling faster iterations in QML.
- It details an incremental methodology using the 'transpile_right' function, which reduces redundant computation and achieves up to 8x time savings on deep circuits.
- Empirical results across Angle, Amplitude, and ZZFeatureMap encoding demonstrate improved scalability, efficient resource usage, and enhanced practicality for QML workflows.
Accelerating Quantum Circuit Transpilation in Machine Learning with Haiqu's Rivet-transpiler
Introduction
The compilation of quantum circuits for execution on hardware is a critical bottleneck in the practical deployment of quantum algorithms, particularly in quantum machine learning (QML) workflows. As quantum devices scale in qubit count and circuit depth, the transpilation process—mapping logical circuits to hardware-constrained forms—becomes increasingly resource-intensive. This paper introduces the Rivet transpiler, a system designed to accelerate transpilation by reusing previously compiled circuit segments, thereby reducing redundant computation in iterative and structurally repetitive quantum workloads. The work focuses on the application of Rivet in QML, especially in the context of Layerwise Learning (LL), and provides empirical evidence of substantial reductions in transpilation time across various encoding strategies and circuit sizes.
Background: Quantum Transpilation and Its Challenges
Quantum transpilation involves several stages: standardizing gate representations, mapping logical to physical qubits, routing to satisfy hardware connectivity, translating to native gate sets, optimizing for depth and gate count, and scheduling for hardware timing. The process is computationally expensive, especially for circuits with high qubit counts or deep entangling structures. Traditional transpilers such as Qiskit, tket, and BQSKit operate on individual circuits, often failing to exploit structural similarities across related circuits generated in iterative algorithms or measurement protocols.
In QML, the transpilation burden is exacerbated by the need to repeatedly compile similar circuits—e.g., in variational algorithms, state tomography, or when measuring in multiple Pauli bases. This redundancy leads to significant inefficiencies, particularly as circuit complexity grows.
Rivet Transpiler: Architecture and Methodology
Rivet addresses these inefficiencies by introducing a caching and reuse mechanism for transpiled subcircuits. The core function, transpile_right, enables the incremental transpilation of circuits by appending new segments to previously transpiled components. This is particularly effective in scenarios where a common state preparation or data encoding circuit is shared across multiple measurement or training configurations.
The workflow with Rivet typically involves:
- Transpiling the shared (left) segment of the circuit once.
- Appending new (right) segments—such as measurement rotations or additional layers—using
transpile_right, which only transpiles the incremental changes.
- Stitching the transpiled segments to form the final hardware-ready circuit.
This approach is especially advantageous in LL, where circuits are grown and optimized incrementally, and in measurement-heavy protocols such as shadow tomography or quantum chemistry VQE, where many similar circuits are required.
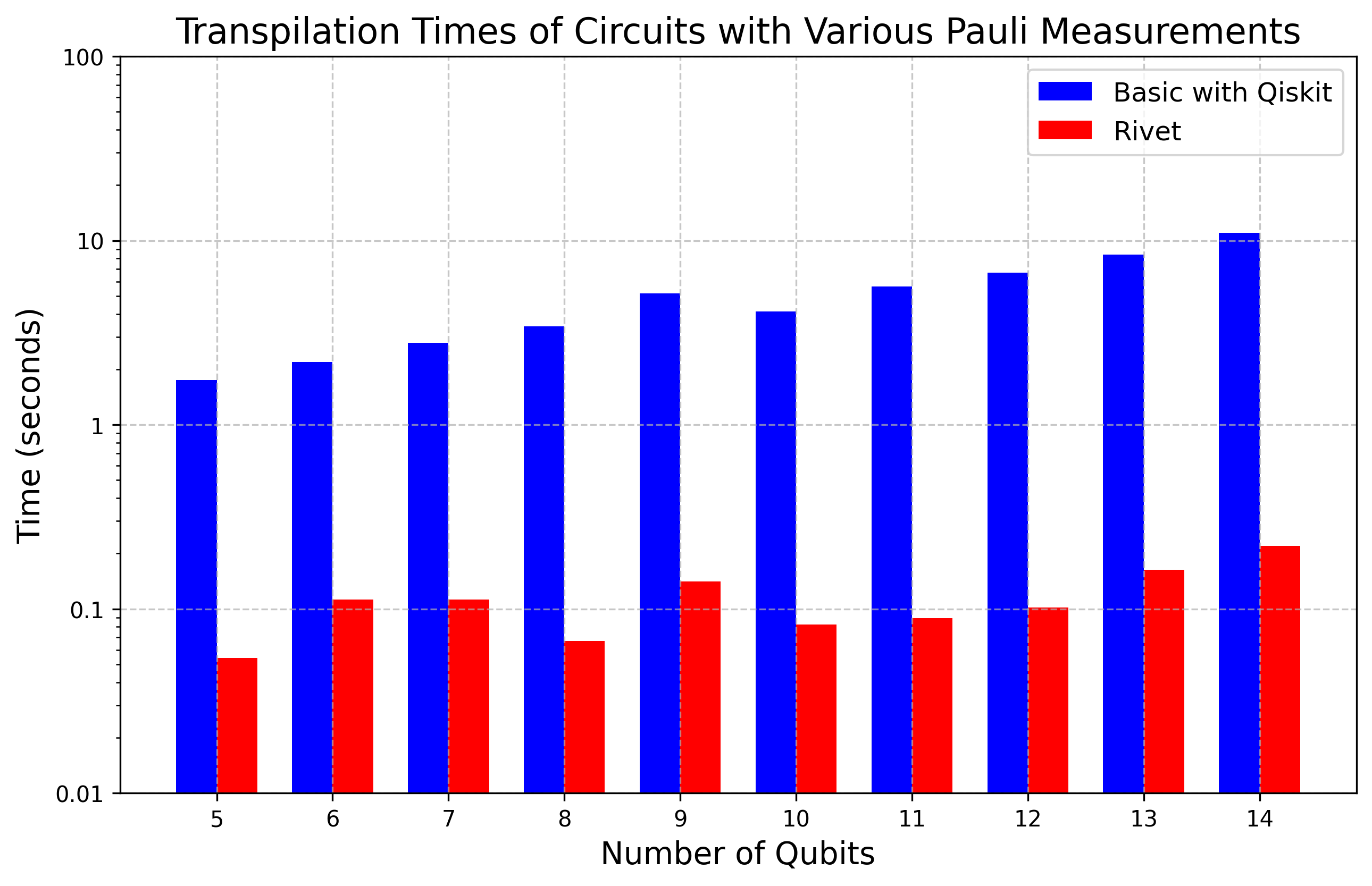
Figure 1: Warm up example comparing transpilation time for a random input circuit measured in 10 randomly generated Pauli bases.
Layerwise Learning and Transpilation Bottlenecks
LL is a training paradigm for PQCs that mitigates barren plateaus by incrementally constructing and optimizing the circuit. The process is divided into two phases:
- Phase 1: Layers are added sequentially, and the circuit is optimized after each addition.
- Phase 2: The circuit is partitioned, and each partition is optimized in turn.
Each layer addition in Phase 1 necessitates a new transpilation, leading to a linear increase in compilation overhead with circuit depth. Rivet's incremental transpilation mechanism directly addresses this by reusing the transpiled prefix and only compiling the newly added layers.
Experimental Evaluation
Angle Encoding
Angle Encoding maps classical features to single-qubit rotations. Experiments with 20- and 40-layer PQCs using LL demonstrated that Rivet reduced transpilation time by factors of 5 and 8, respectively, compared to standard methods. The efficiency gain scales with circuit depth, as the proportion of reused structure increases.
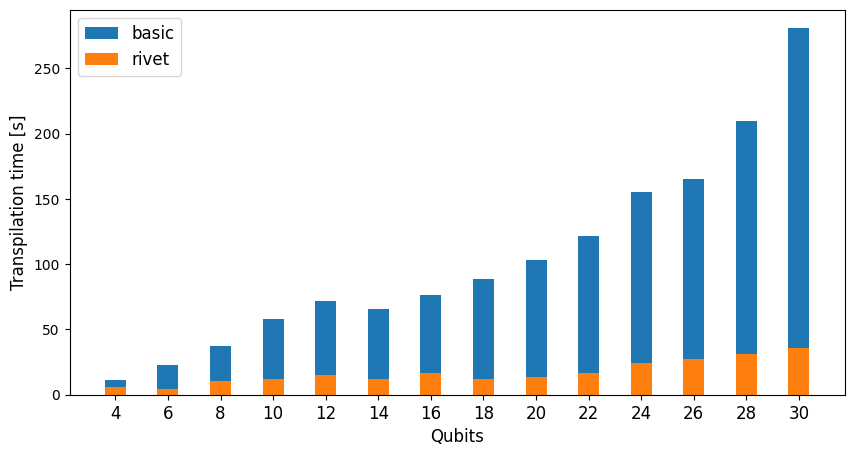
Figure 2: Comparison of transpilation times between basic and Rivet methods for training a 40-layer PQC using Angle Encoding with Layerwise Learning, adding 2 layers at each of 20 steps.
Amplitude Encoding
Amplitude Encoding leverages the full Hilbert space, encoding 2n features into n qubits. The state preparation circuits generated by Qiskit's prepare_state are data-dependent and often deep, making transpilation particularly costly. Rivet achieved up to a 4x reduction in transpilation time for 6-qubit, 648-parameter PQCs, demonstrating scalability to larger, more complex circuits.
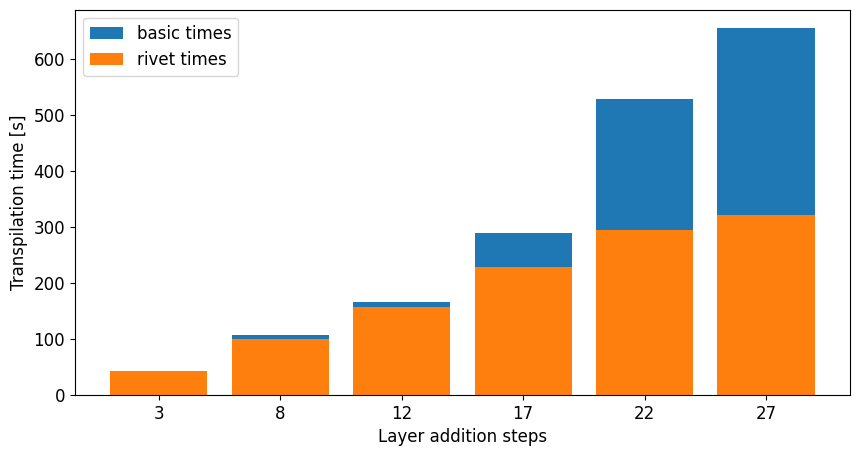
Figure 3: Transpilation times for training a 4-qubit PQC with Amplitude Encoding using Layerwise Learning. Four layers are added at each step, comparing basic and Rivet methods.
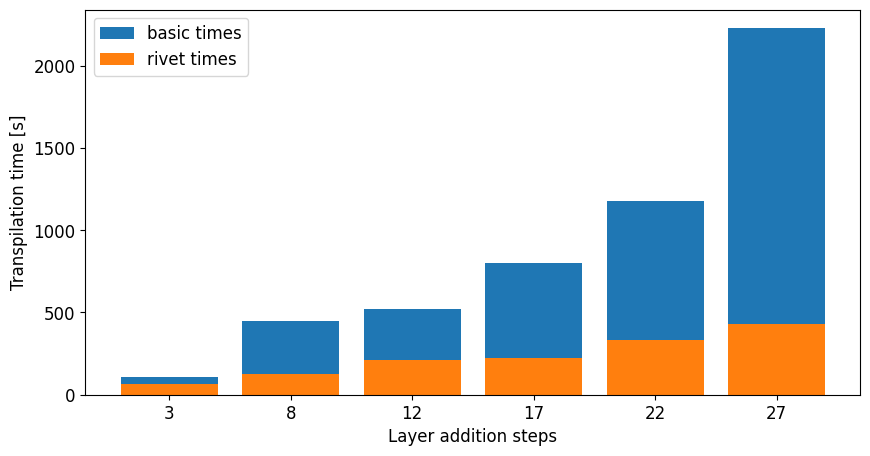
Figure 4: Transpilation times for training a 6-qubit PQC with Amplitude Encoding using Layerwise Learning. Four layers are added at each step, comparing basic and Rivet methods.
ZZFeatureMap Encoding
The ZZFeatureMap is a parameterized entangling data encoding circuit. Since its structure is parameterized, it can be transpiled once and reused for different data inputs, further amplifying the benefits of Rivet's approach. For 30-qubit circuits, Rivet achieved an 8x reduction in transpilation time.
Impact on Quantum Machine Learning Workflows
The integration of Rivet into QML workflows, particularly those employing LL, yields significant practical benefits:
- Reduced Compilation Overhead: By reusing transpiled segments, Rivet minimizes redundant computation, enabling faster iteration and experimentation.
- Scalability: The efficiency gains become more pronounced as circuit depth and qubit count increase, supporting the scaling of QML models to more complex tasks.
- Resource Optimization: Lower transpilation times translate to reduced computational resource consumption, which is critical in cloud-based or resource-constrained environments.
Empirical results on binary classification tasks (Iris and MNIST datasets) confirm that the use of Rivet does not compromise model performance. For instance, a 4-qubit, 6-layer PQC trained with LL and Rivet achieved 100% test accuracy on the Iris dataset.

Figure 5: Combined loss function from Phase One and Phase Two. Red lines separate each layer addition step. Black and orange lines separate partition training (black for Partition 1 and orange for Partition 2) in Phase Two.
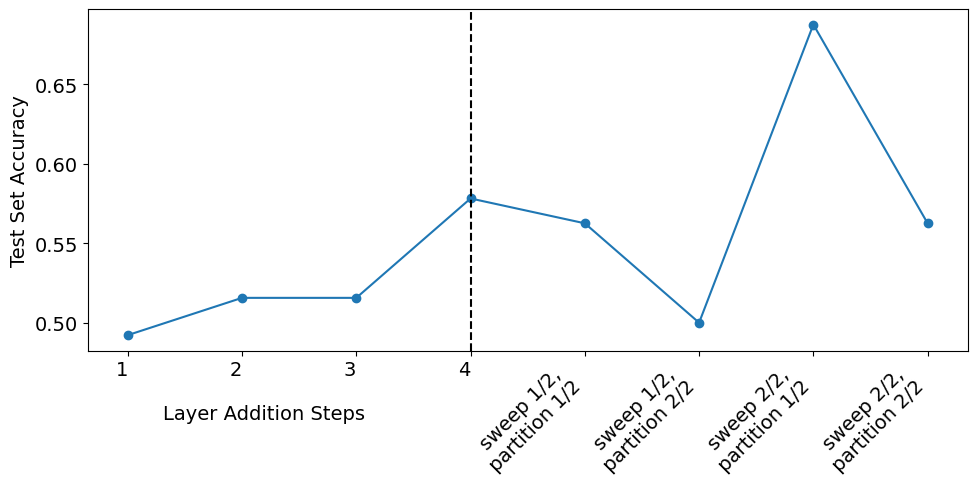
Figure 6: Test accuracy during training phases. In Phase One, accuracy is calculated after each added layer completes training. In Phase Two, it is calculated after training each partition.
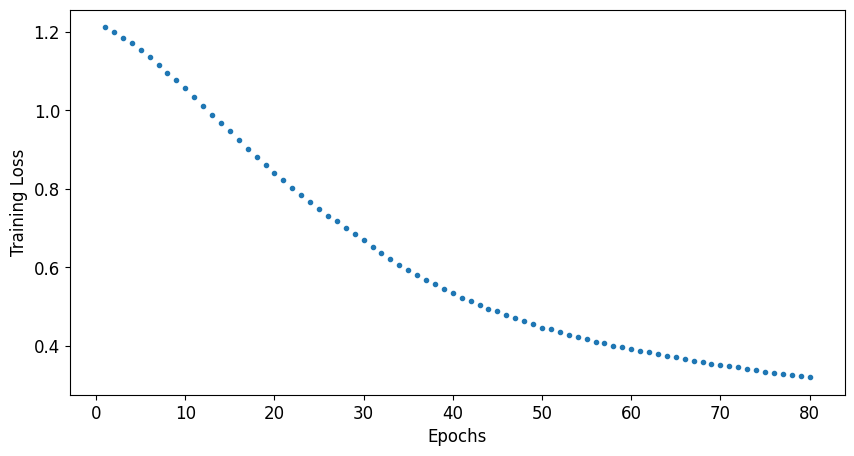
Figure 7: Loss function evaluated at each epoch during regular training of a 12-layer PQC.
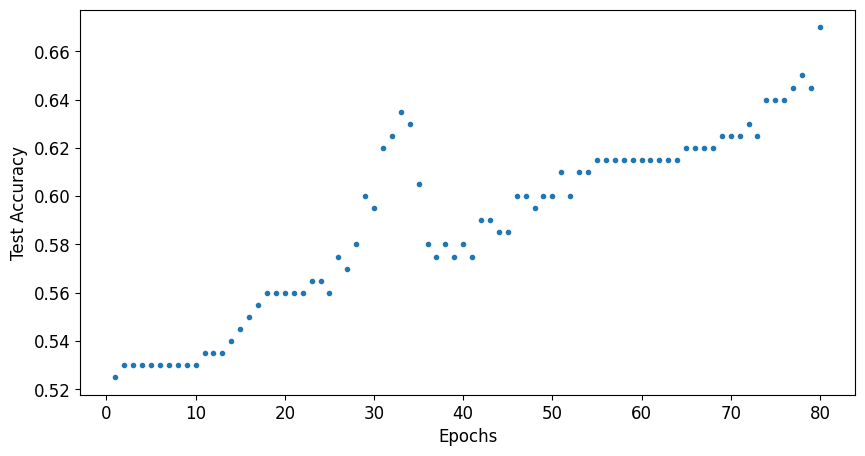
Figure 8: Test accuracy evaluated at each epoch during regular training of a 12-layer PQC.
Implementation Considerations
- Integration: Rivet is compatible with Qiskit and can be integrated into existing QML pipelines with minimal code changes.
- Parameterization: For parameterized data encoding circuits, transpilation can be performed once, with parameters supplied at runtime, maximizing reuse.
- Data-dependent Circuits: For data-dependent state preparation (e.g., amplitude encoding), Rivet's benefits are most pronounced when the data encoding is shared across multiple circuit variants.
- Limitations: The approach is less effective when each circuit is structurally unique, as in certain randomized or highly data-dependent protocols.
Theoretical and Practical Implications
The reuse-based transpilation paradigm exemplified by Rivet has both theoretical and practical implications:
- Algorithmic Efficiency: By formalizing the notion of circuit segment reuse, Rivet opens avenues for further research into modular transpilation and compilation caching strategies.
- Hardware Utilization: Faster transpilation enables more efficient use of quantum hardware, reducing queue times and increasing experimental throughput.
- Scalability of QML: The reduction in compilation overhead is a key enabler for scaling QML models to larger datasets and more expressive circuit architectures.
Future developments may include automated detection of reusable subcircuits, integration with other transpiler stacks, and extension to distributed or hybrid quantum-classical workflows.
Conclusion
The Rivet transpiler provides a practical and effective solution to the transpilation bottleneck in quantum machine learning and other iterative quantum algorithms. By enabling the reuse of transpiled circuit segments, Rivet achieves substantial reductions in compilation time—up to 8x or more for deep, multi-qubit circuits—without compromising model performance. This efficiency is critical for the scalability and practicality of QML on near-term quantum devices. The methodology and results presented in this work suggest that reuse-based transpilation should become a standard component of quantum software stacks, particularly as quantum workloads grow in complexity and scale.