Fast Convergence Rates for Subsampled Natural Gradient Algorithms on Quadratic Model Problems
Published 28 Aug 2025 in cs.LG, math.OC, and stat.ML | (2508.21022v1)
Abstract: Subsampled natural gradient descent (SNGD) has shown impressive results for parametric optimization tasks in scientific machine learning, such as neural network wavefunctions and physics-informed neural networks, but it has lacked a theoretical explanation. We address this gap by analyzing the convergence of SNGD and its accelerated variant, SPRING, for idealized parametric optimization problems where the model is linear and the loss function is strongly convex and quadratic. In the special case of a least-squares loss, namely the standard linear least-squares problem, we prove that SNGD is equivalent to a regularized Kaczmarz method while SPRING is equivalent to an accelerated regularized Kaczmarz method. As a result, by leveraging existing analyses we obtain under mild conditions (i) the first fast convergence rate for SNGD, (ii) the first convergence guarantee for SPRING in any setting, and (iii) the first proof that SPRING can accelerate SNGD. In the case of a general strongly convex quadratic loss, we extend the analysis of the regularized Kaczmarz method to obtain a fast convergence rate for SNGD under stronger conditions, providing the first explanation for the effectiveness of SNGD outside of the least-squares setting. Overall, our results illustrate how tools from randomized linear algebra can shed new light on the interplay between subsampling and curvature-aware optimization strategies.
The paper demonstrates that SNGD converges at a rate of (1-α)^t while SPRING, equivalent to an accelerated Kaczmarz method, achieves a rate of (1-√(α/β))^t.
It interprets the subsampled update steps as randomized projection methods, providing a rigorous theoretical foundation for their efficiency in quadratic problem settings.
The study highlights practical implications for hyperparameter tuning, emphasizing the critical role of regularization and momentum in neural network and physics-informed models.
Fast Convergence Rates for Subsampled Natural Gradient Algorithms on Quadratic Model Problems
Introduction and Motivation
This paper provides a rigorous theoretical analysis of subsampled natural gradient descent (SNGD) and its accelerated variant, SPRING, in the context of quadratic model problems. SNGD and SPRING have demonstrated empirical success in scientific machine learning, particularly for neural network wavefunctions (NNWs) and physics-informed neural networks (PINNs), but prior to this work, their fast convergence properties lacked a comprehensive theoretical explanation. The authors address this gap by establishing equivalences between these algorithms and well-studied randomized linear algebra methods, specifically regularized Kaczmarz and its accelerated variants, and by deriving explicit convergence rates under various problem settings.
Problem Formulation and Algorithmic Framework
The analysis focuses on two classes of quadratic model problems:
Linear Least-Squares (LLS):L(v)=21∥v−b∥2, with vθ=Jθ.
Linear Least-Quadratics (LLQ):L(v)=21v⊤Hv+v⊤q+c, with vθ=Jθ and H≻0.
These models are representative of the loss landscapes encountered in PINNs and NNWs, respectively. The key insight is that, under these settings, the SNGD and SPRING updates can be interpreted as randomized projection methods in parameter space, with the stochasticity arising from minibatch subsampling.
The SNGD update is given by:
θt+1=θt−ηJS+(rS)
where JS and rS are the Jacobian and residuals evaluated on a minibatch S, and JS+ denotes the regularized pseudoinverse. SPRING introduces a momentum term, updating an auxiliary variable ϕt alongside θt.
Theoretical Results: Equivalences and Convergence Rates
SNGD and SPRING as Randomized Kaczmarz Methods
A central contribution is the demonstration that, for LLS, SNGD is equivalent to the regularized Kaczmarz method, and SPRING is equivalent to the Nesterov-accelerated regularized Kaczmarz (ARK) method. This equivalence enables the transfer of convergence results from randomized linear algebra to the analysis of SNGD and SPRING.
SNGD (LLS): Converges at a rate (1−α)t, where α is the minimal eigenvalue of the expected projection matrix P.
SPRING (LLS): Achieves an accelerated rate of (1−α/β)t, where β is related to the spectral properties of the projection operator.
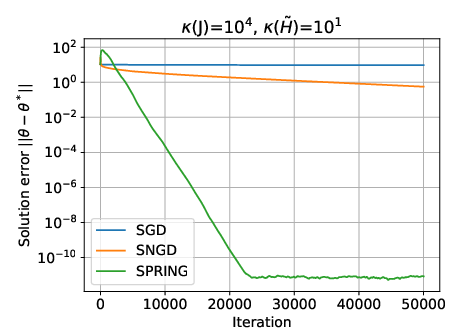
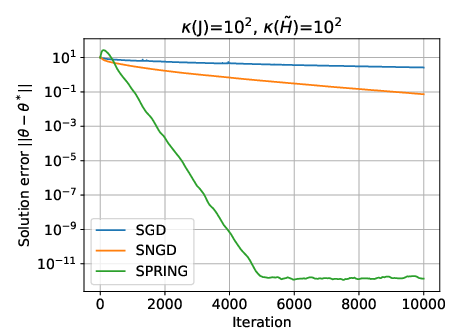
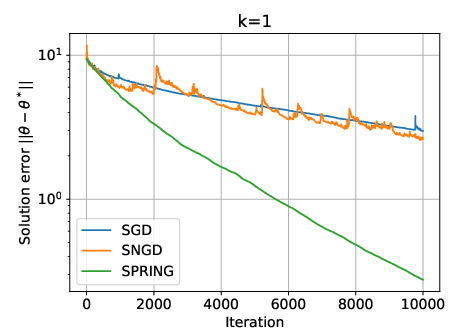
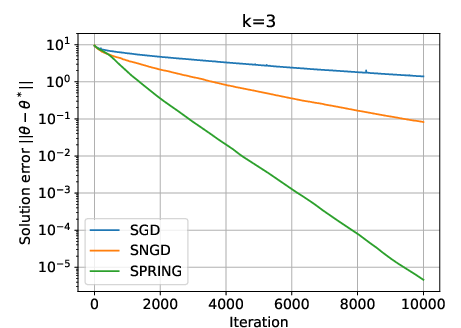
This analysis explains the empirical superiority of SNGD over SGD and the further acceleration provided by SPRING, especially for small batch sizes.
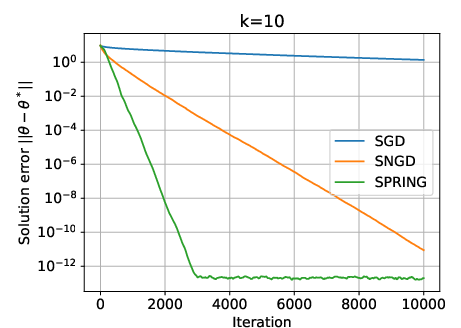
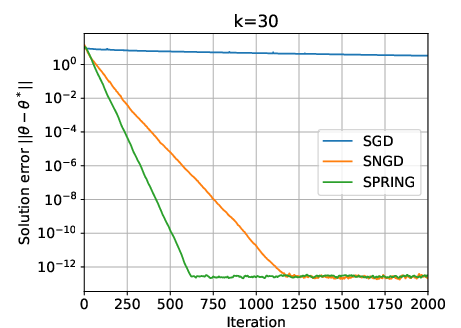
Figure 1: SGD, SNGD, and SPRING for two randomly generated difficult instances of the LLQ problem, illustrating the superior convergence of SNGD and SPRING.
Extension to Linear Least-Quadratics
For LLQ, the analysis is more nuanced due to the presence of the function-space Hessian H. The authors introduce a strong consistency assumption, ensuring that the function-space gradient remains in the range of the model Jacobian. Under this assumption, they show that SNGD can be viewed as a regularized Kaczmarz method applied to a transformed problem, and they derive the first explicit fast convergence rate for SNGD in this setting.
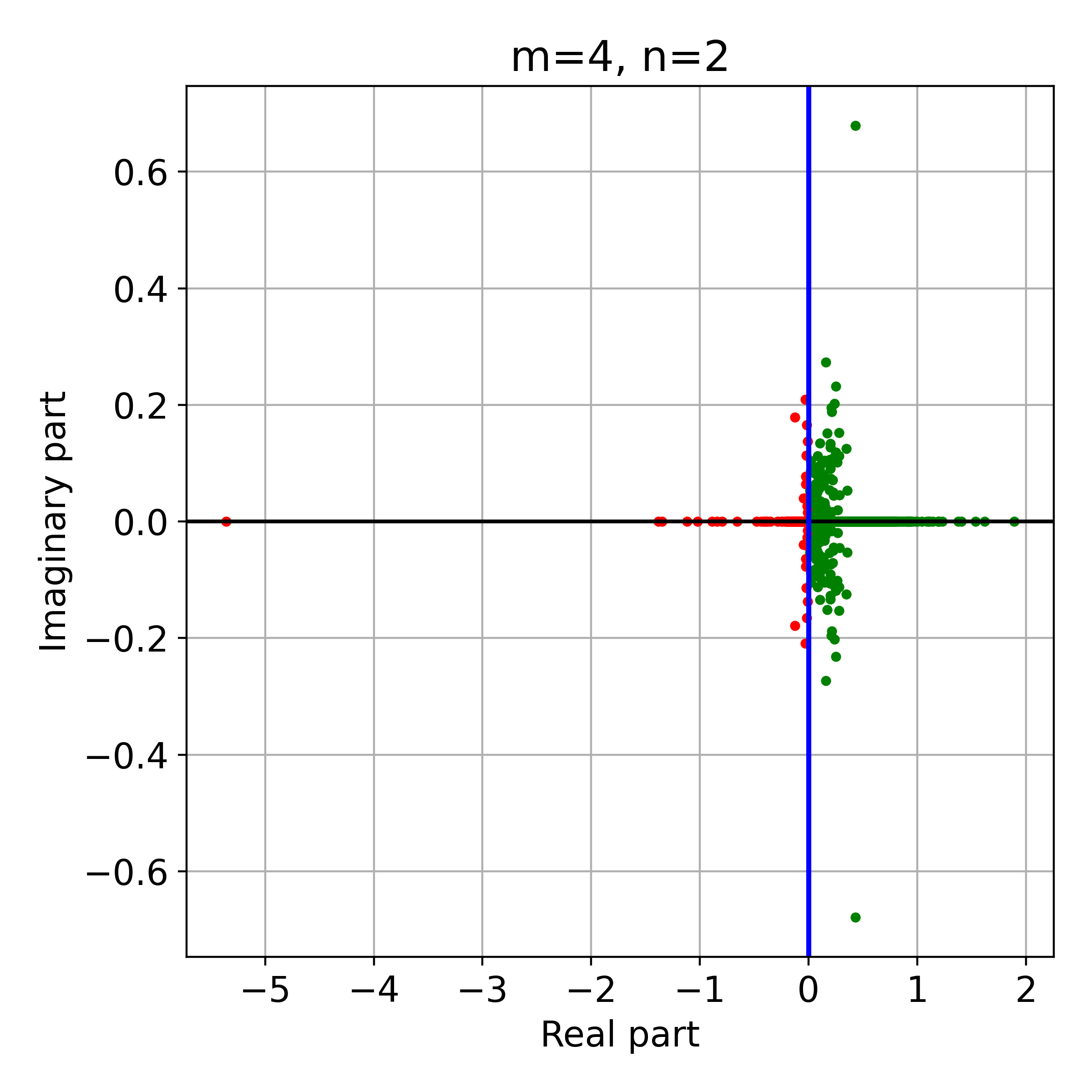
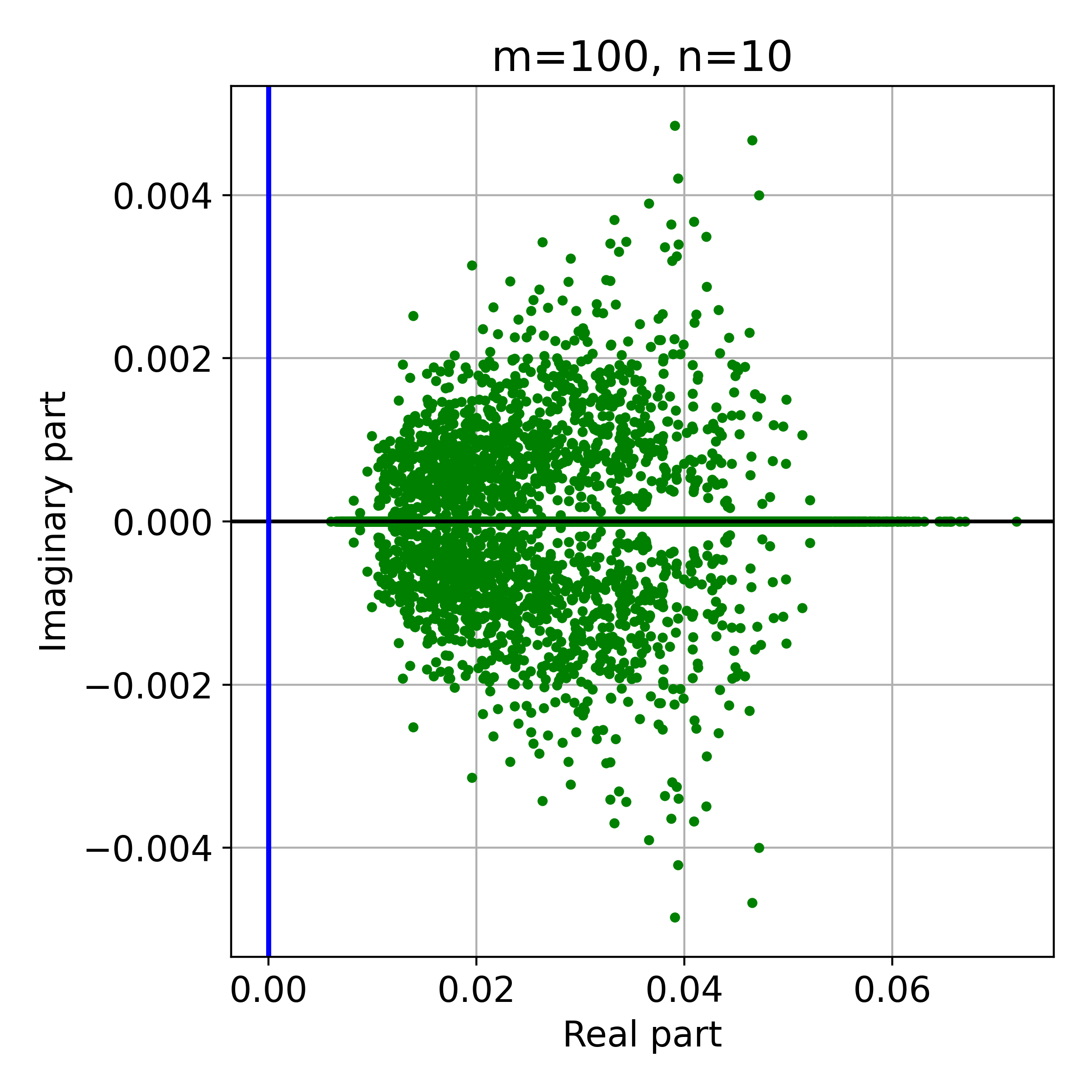
The convergence rate for SNGD in LLQ is shown to be slower than in LLS by a factor γ (related to the alignment of the projection and Hessian), but still significantly faster than SGD under realistic spectral decay assumptions for J.
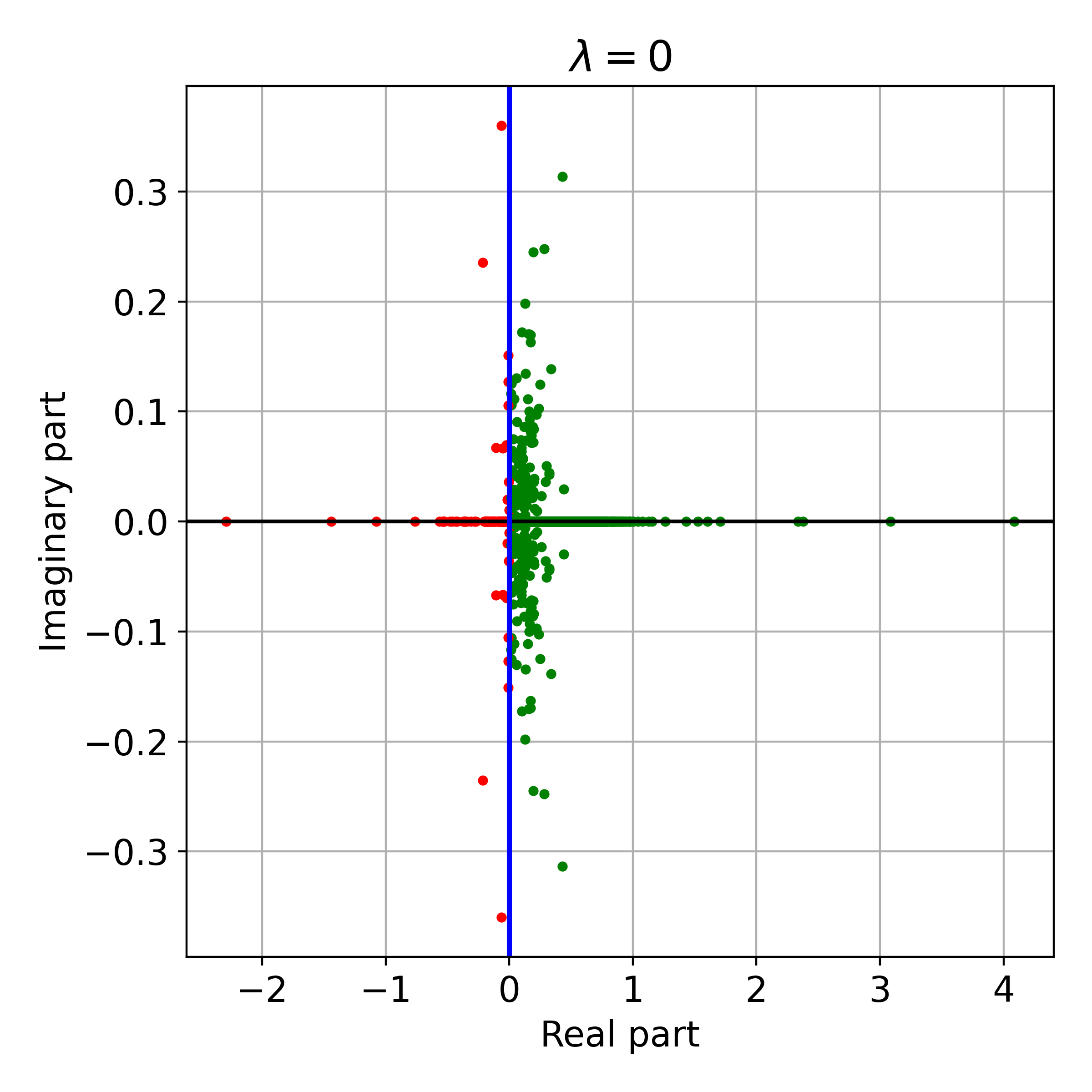
Figure 2: Eigenvalues of M for randomly generated problems of two sizes, showing the spectral properties relevant to SNGD convergence.
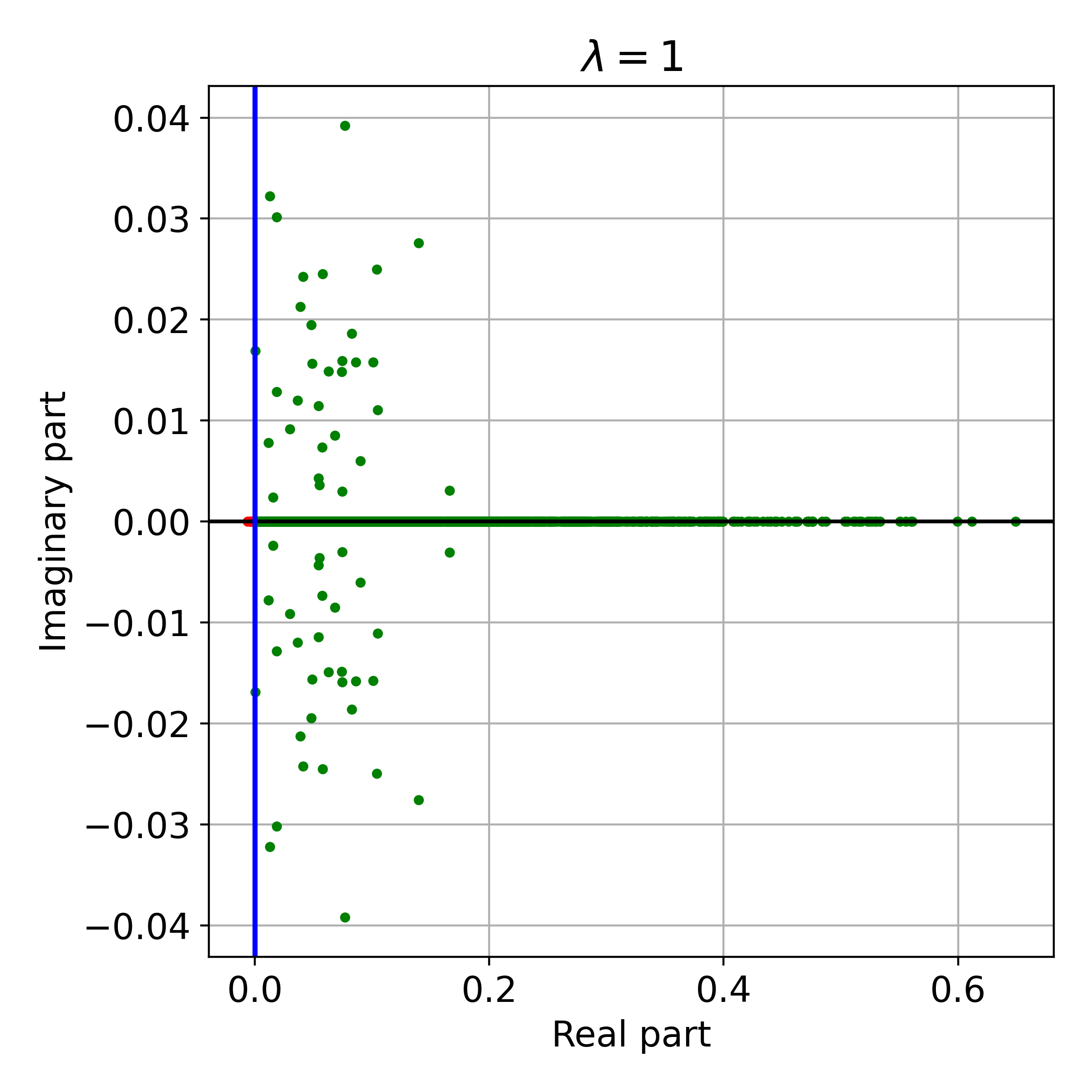
Figure 3: Effect of regularization parameter λ on the eigenvalues of M, demonstrating the necessity of sufficient regularization for convergence.
SPRING for LLQ: Empirical and Conjectural Analysis
While a full theoretical analysis of SPRING for LLQ is left as an open problem, the paper provides empirical evidence that SPRING can dramatically outperform SNGD in this setting. The authors conjecture that the acceleration observed in LLS extends, with some degradation, to LLQ under appropriate conditions.
Figure 4: SGD, SNGD, and SPRING for a randomly generated LLQ instance with varying batch sizes, highlighting the consistent acceleration of SPRING.
Practical Implications and Implementation Considerations
Algorithmic Implementation
The SNGD and SPRING algorithms are readily implementable in modern autodiff frameworks. The key steps are:
Minibatch Sampling: At each iteration, sample a minibatch S of size k.
Jacobian and Residual Computation: Compute JS and rS via backpropagation and application of the loss operator.
Regularized Pseudoinverse: Compute JS+=JS⊤(JSJS⊤+λI)−1, exploiting the Woodbury identity for efficiency when k≪n.
Parameter Update: Apply the SNGD or SPRING update as specified.
The computational bottleneck is the formation and inversion of the k×k matrix JSJS⊤+λI, which is tractable for moderate k even when n is large.
Hyperparameter Selection
Regularization (λ): Sufficiently large λ is necessary for convergence in LLQ, as demonstrated by the spectral analysis of the update operator.
Step Size (η) and Momentum (μ): Should be tuned based on the spectral properties of the problem; the theoretical rates provide guidance for optimal choices.
Resource and Scaling Considerations
Memory: Storage of JS and intermediate matrices scales with kn.
Computation: Each iteration is O(nk2), which is efficient for small k and large n.
Limitations
The analysis assumes strong consistency and, for LLQ, additional spectral alignment conditions that may not always hold in practice.
The extension to inconsistent or non-quadratic problems remains open.
Theoretical and Practical Implications
The results provide a rigorous foundation for the observed empirical efficiency of SNGD and SPRING in scientific machine learning. The equivalence to randomized Kaczmarz methods clarifies why using the same minibatch for both the gradient and preconditioner is beneficial, and why acceleration via momentum is effective. The analysis also highlights the importance of regularization and the spectral properties of the data in determining convergence rates.
From a practical standpoint, these insights justify the use of SNGD and SPRING in large-scale PINN and NNW applications, and suggest that further algorithmic improvements may be possible by leveraging advances in randomized linear algebra.
Future Directions
SPRING for LLQ: A complete theoretical analysis remains to be developed, particularly to quantify the observed acceleration.
Beyond Quadratic Models: Extending the framework to inconsistent, non-quadratic, or non-convex settings is a natural next step.
Other Curvature-Aware Methods: The approach may generalize to subsampled Newton or Gauss-Newton methods.
Algorithmic Innovation: The connection to optimal row-access methods in randomized linear algebra may inspire new optimizers for high-dimensional scientific ML problems.
Conclusion
This work establishes the first fast convergence rates for SNGD and SPRING in quadratic model problems, providing a theoretical explanation for their empirical success in scientific machine learning. By connecting these algorithms to randomized Kaczmarz methods, the authors offer both practical guidance for implementation and a foundation for future advances in curvature-aware optimization under subsampling. The results have significant implications for the design and analysis of scalable optimization algorithms in high-dimensional, ill-conditioned settings.
“Emergent Mind helps me see which AI papers have caught fire online.”
Philip
Creator, AI Explained on YouTube
Sign up for free to explore the frontiers of research
Discover trending papers, chat with arXiv, and track the latest research shaping the future of science and technology.Discover trending papers, chat with arXiv, and more.