Multi-Agent Penetration Testing AI for the Web
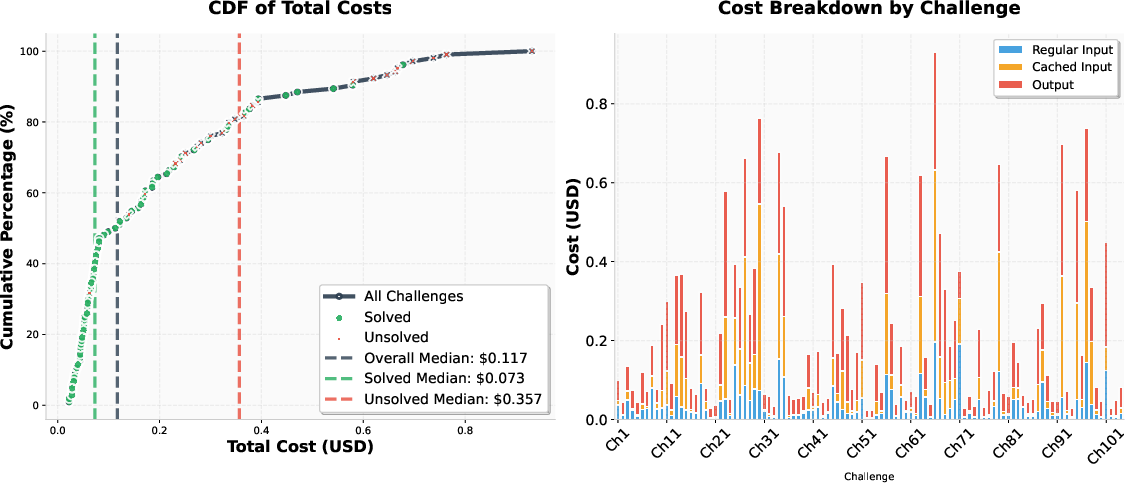
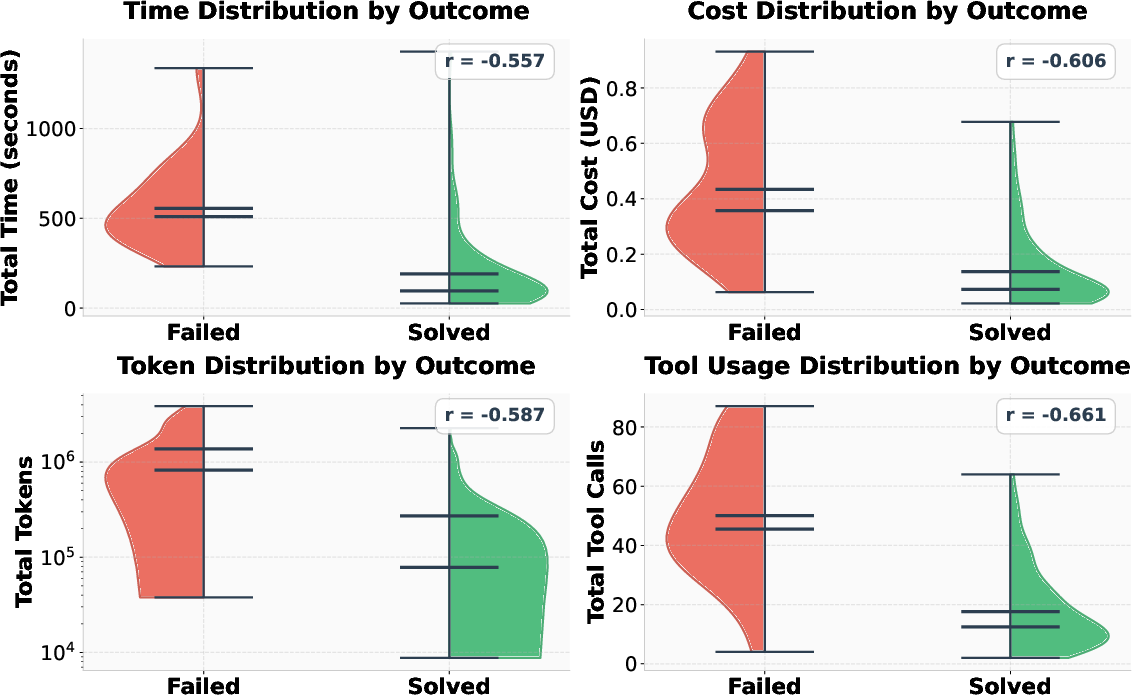
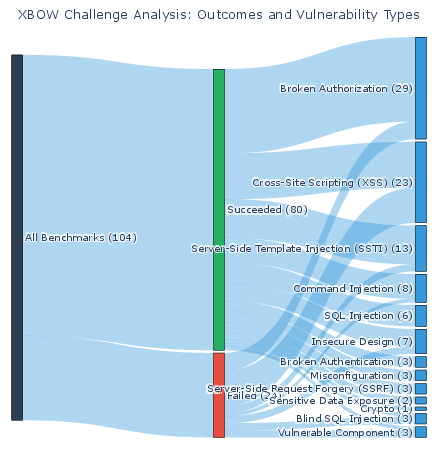
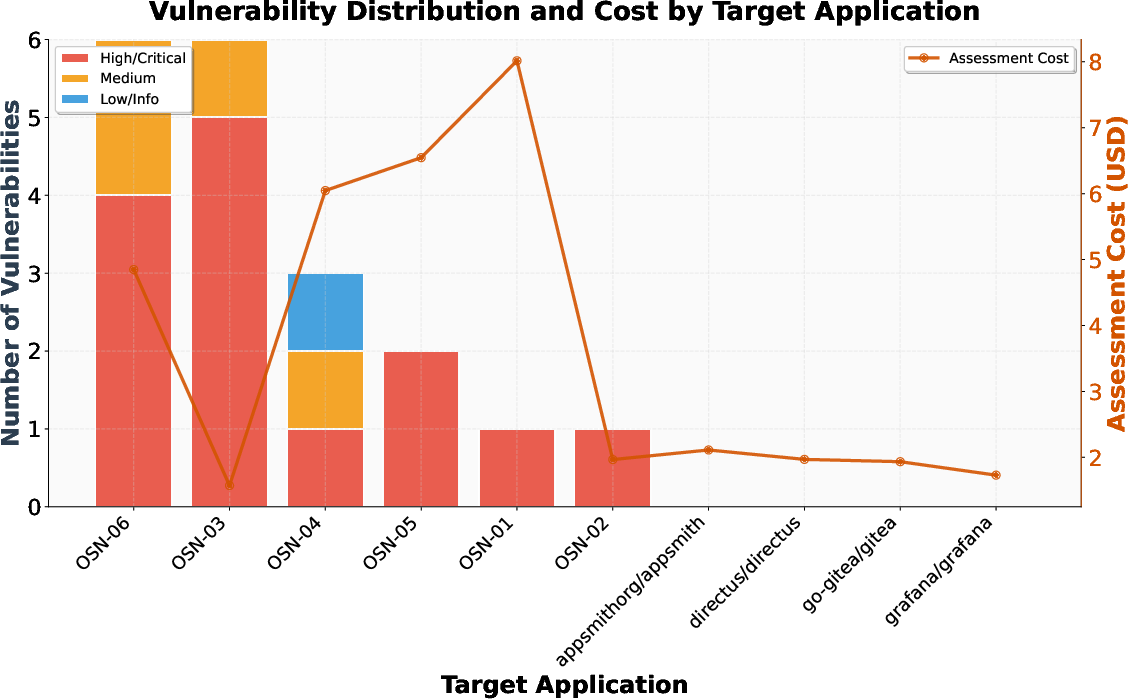
Abstract: AI-powered development platforms are making software creation accessible to a broader audience, but this democratization has triggered a scalability crisis in security auditing. With studies showing that up to 40% of AI-generated code contains vulnerabilities, the pace of development now vastly outstrips the capacity for thorough security assessment. We present MAPTA, a multi-agent system for autonomous web application security assessment that combines LLM orchestration with tool-grounded execution and end-to-end exploit validation. On the 104-challenge XBOW benchmark, MAPTA achieves 76.9% overall success with perfect performance on SSRF and misconfiguration vulnerabilities, 83% success on broken authorization, and strong results on injection attacks including server-side template injection (85%) and SQL injection (83%). Cross-site scripting (57%) and blind SQL injection (0%) remain challenging. Our comprehensive cost analysis across all challenges totals $21.38 with a median cost of $0.073 for successful attempts versus $0.357 for failures. Success correlates strongly with resource efficiency, enabling practical early-stopping thresholds at approximately 40 tool calls or $0.30 per challenge. MAPTA's real-world findings are impactful given both the popularity of the respective scanned GitHub repositories (8K-70K stars) and MAPTA's low average operating cost of $3.67 per open-source assessment: MAPTA discovered critical vulnerabilities including RCEs, command injections, secret exposure, and arbitrary file write vulnerabilities. Findings are responsibly disclosed, 10 findings are under CVE review.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Knowledge Gaps
Below is a single, focused list of the paper’s unresolved knowledge gaps, limitations, and open questions that future work could concretely address:
- Lack of head-to-head, reproducible baselines: no controlled comparison against PentestGPT, PenHeal, or commercial XBOW under identical targets, budgets, and stopping criteria.
- Model dependence unexamined: evaluation uses only GPT-5; missing ablations across model families/sizes, reasoning modes, temperatures, tool-use prompting styles, and context window sizes.
- Run-to-run variance not reported: no multiple trials per challenge to quantify stochastic performance, confidence intervals, or stability across seeds.
- Blind SQL injection capability gap (0% success): absence of time-based inference, out-of-band exfiltration (DNS/HTTP callbacks), second-order strategies, and resilient delay measurement under jitter.
- XSS handling limited (57% success): no headless browser/DOM instrumentation (e.g., Playwright/Selenium), CSP-aware payload generation, sink discovery, or client-side taint tracking.
- Weak authentication analysis (33% success): insufficient modeling of session state, cookie/JWT manipulation, MFA flows, password reset/invite flows, lockouts, and account lifecycle exploitation.
- Business-logic vulnerability validation remains heuristic: no systematic framework for state-space exploration, role-based scenario generation, canary instrumentation, or ground-truth datasets for logic flaws.
- Out-of-scope OWASP categories: A08 (Software and Data Integrity Failures) and A09 (Logging/Monitoring Failures) not evaluated; API abuse topics like rate limiting, resource consumption, and DoS also omitted.
- Protocol coverage narrow: focus on HTTP; no support for WebSockets, GraphQL, gRPC, or SOAP with schema-aware exploration and mutation.
- Limited evaluation on modern SPAs: CTF apps are simple; no robust crawling and execution of complex front-end code (routing, state management, API orchestration).
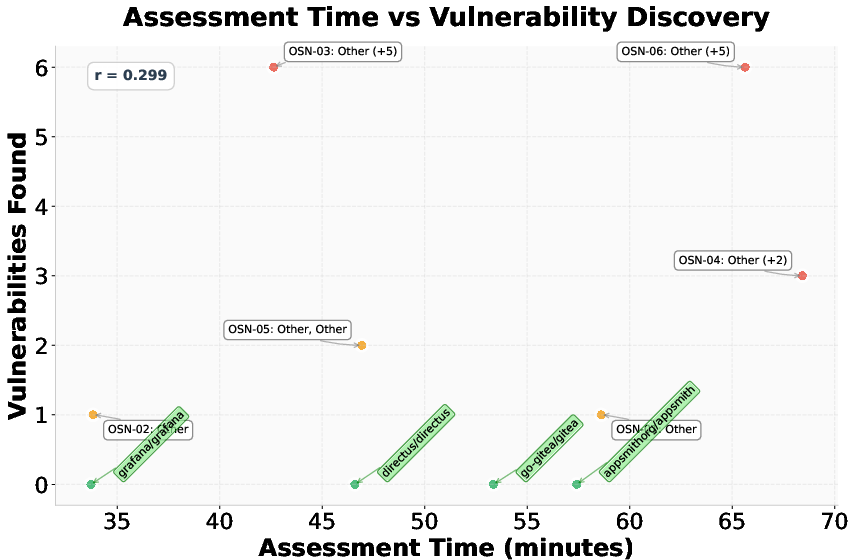
- Real-world validation scope small and not benchmarked: 10 repositories, whitebox only, anonymized targets; lacks comparison to expert pen-test results, bug bounty outcomes, and quantification of recall/precision.
- False-positive/negative rates not measured: PoC validation reduces false positives but no labeled benchmarks to quantify both FP and FN at scale.
- Early-stopping thresholds proposed but untested: need prospective evaluation of adaptive stopping policies to avoid missing slow-to-exploit vulnerabilities.
- Agent architecture ablations missing: no study of the number of sandbox agents, concurrency, scheduling, role configurations, or evidence-gated branching strategies on performance and cost.
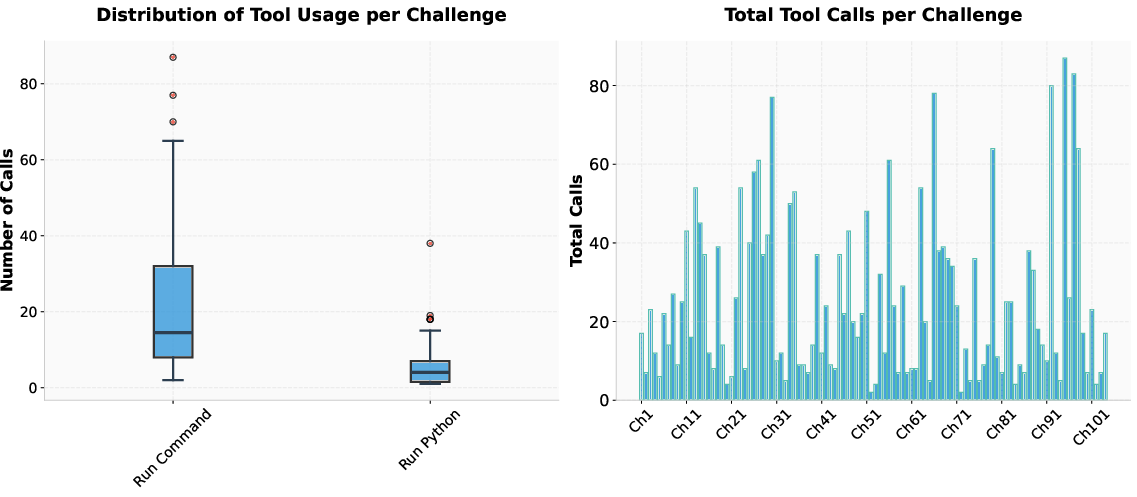
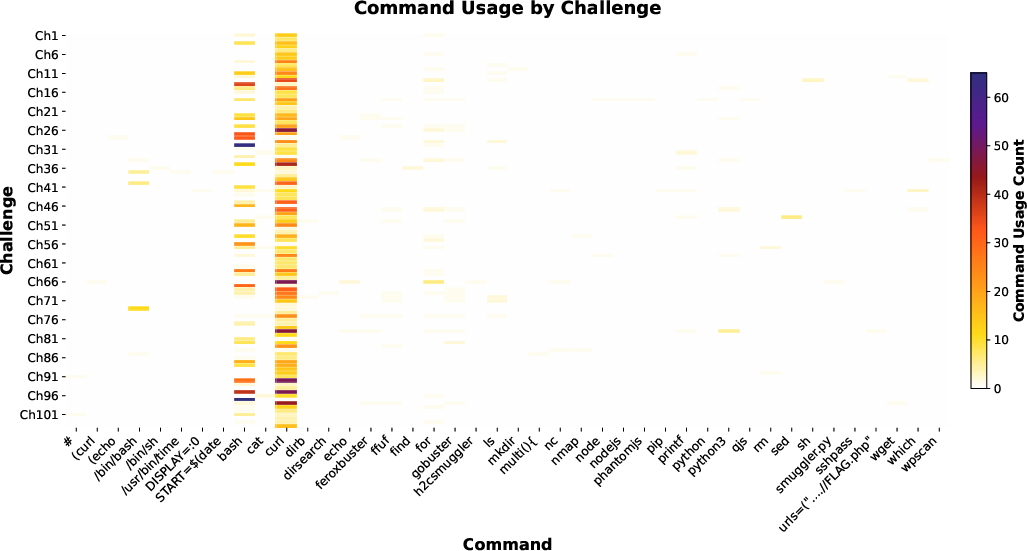
- Tooling breadth limited and inconsistent: paper mentions nmap/ffuf but table shows only run_command/run_python; lacks integration with specialized tools (e.g., sqlmap, nuclei, wafw00f) and automatic parameter tuning.
- No headless browser/JS instrumentation pipeline: needed for XSS, CSRF, DOM-based vulns, postMessage issues, and client-side security policies (CSP/SRI).
- No endpoint/code coverage metrics: no measurement of breadth/depth of exploration (endpoints hit, code paths), leaving blind spot detection unresolved.
- Reproducibility constrained by proprietary models: GPT-5 dependence; need publishable prompts, seeds, versioned container images, toolchain scripts, and finalized Docker fixes to ensure full reproducibility.
- Isolation and safety analysis limited: only Docker; no assessment of exploit side-effects, container escape risks, resource quotas, or secure handling/disposal of discovered secrets.
- Ethical deployment on live targets not explored: governance, consent, rate limiting, safe operating envelopes, and organizational workflows for continuous testing in production remain open.
- Stealth and evasion strategies unaddressed: no methods for WAF/IDS evasion, low-noise scanning, adaptive throttling, or polymorphic payloads.
- Cloud-specific SSRF coverage narrow: examples target 169.254.169.254 only; need standardized testbeds across cloud providers (AWS/GCP/Azure) and IAM role/instance-profile exploitation validation.
- Training data contamination not tested: no checks for memorization/regurgitation of known challenges, nor defenses against prompt injection or tool-output poisoning.
- Observability/logging trade-offs unclear: “minimal logs” may hinder auditability; need privacy-preserving telemetry that still supports debugging, replay, and evidence provenance.
- Benchmark diversity limited: results bound to XBOW; need cross-benchmark validation (Juice Shop, WebGoat, DVWA, modern enterprise apps) to test generalization.
- Robustness against hardened defenses not assessed: performance against prepared statements, strict CSP, WAF, rate limiting, and defense-in-depth configurations remains unknown.
- Role and tenant modeling missing: automated account creation, privilege matrices, multi-tenant isolation checks, and cross-tenant data leakage testing not implemented.
- Out-of-band channels absent: lack of Collaborator-like infrastructure for blind and asynchronous vulns (DNS/SMTP callbacks, webhook relays).
- Portfolio-scale orchestration unproven: per-job container design not evaluated for large portfolios, parallel scans, scheduling, and resource contention.
- Validation oracle design needs standardization: real-world validation relies on side-effects; need class-specific oracles and reproducible evidence criteria across vuln types.
- Formal planning/search not explored: no attack graphs, POMDP/RL planners, or curriculum learning for multi-step exploit chains and strategic exploration.
- Prompt/tool safety not enforced: run_command/run_python expose risks if the model issues unsafe instructions; need guardrails, allowlists, sandboxed interpreters, and policy enforcement.
Practical Applications
Immediate Applications
The following applications can be deployed now using MAPTA’s current capabilities, performance characteristics, and open-source artifacts.
- Continuous web application security scanning in CI/CD
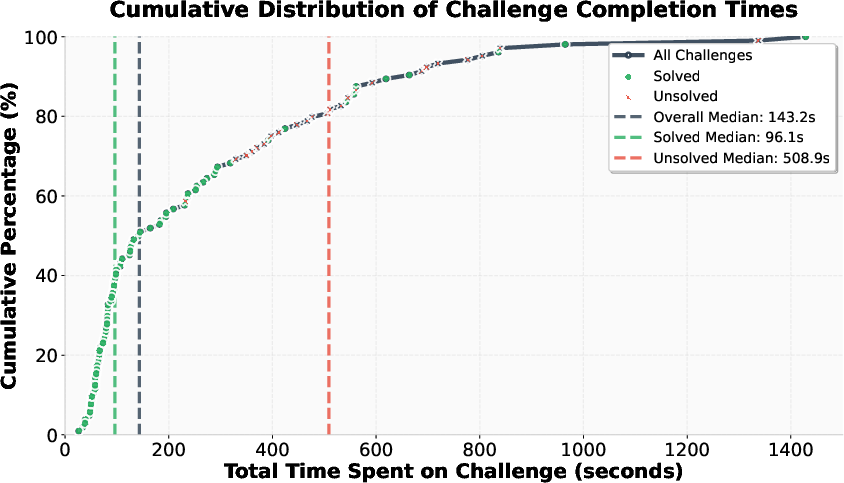
- Description: Integrate MAPTA as a pre-merge or nightly job to run autonomous penetration tests on each build and environment. Enforce low-cost early stopping (≈40 tool calls, ≈$0.30, ≈300 seconds) and require end-to-end exploit validation before blocking merges.
- Sectors: Software, cloud platforms, e-commerce, fintech, SaaS.
- Tools/products/workflows: MAPTA CI plugin; “Security Budget Controller” using resource caps; “Exploit Validation Oracle” generating PoCs with evidence; Slack alert workflow via
send_slack_alert/send_slack_summary. - Assumptions/dependencies: Permissioned testing on dev/staging; Dockerized per-job environments; LLM access; organizational policy to accept automated blocking based on validated exploits.
- Low-cost internal red teaming and attack surface monitoring
- Description: Periodic autonomous blackbox scans of internet-facing apps and microservices, focusing on categories with strong performance (SSRF, misconfiguration, SQLi, SSTI, command injection).
- Sectors: Finance, healthcare, critical SaaS, government.
- Tools/products/workflows: MAPTA orchestrator with scheduled jobs; evidence packs (PoC, logs, reproduction steps) to feed vulnerability management platforms.
- Assumptions/dependencies: Legal authorization for scans; isolated target environments to avoid production impact; acceptance of current blind SQLi/XSS limitations.
- Open-source repository reviews and maintainer assistance
- Description: Use whitebox mode to clone, deploy, and assess open-source projects; generate PoC-backed issues and advisories; streamline CVE submissions where appropriate.
- Sectors: Open-source ecosystems, developer tooling.
- Tools/products/workflows: “Maintainer Audit Bot” that opens issues with validated PoCs; repository action to auto-fire MAPTA on PRs affecting security-sensitive code.
- Assumptions/dependencies: Responsible disclosure workflows; maintainers’ consent; reproducible local deployment in Docker; support for diverse stacks (Node.js, Python, Next.js).
- Bug bounty triage and validation
- Description: Security teams use MAPTA’s Validation agent to verify bounty submissions with concrete exploit execution before reward decisions.
- Sectors: Platform companies, marketplaces, large web properties.
- Tools/products/workflows: Intake pipeline that converts reported vectors into candidate PoCs and runs them in MAPTA’s sandbox; evidence gating to reduce false positives.
- Assumptions/dependencies: Structured submission formats; safe sandboxing; legal controls for exploit execution; alignment with program rules.
- SOC/DevSecOps augmentation for new deployments
- Description: Automatically run a short autonomous pentest after each deployment, emphasizing high-yield categories (SSRF, misconfig, authorization flaws).
- Sectors: Enterprise IT, cloud-native platforms.
- Tools/products/workflows: Deployment hooks that trigger MAPTA; “Risk dashboard” summarizing findings with severity and exploit evidence.
- Assumptions/dependencies: Access to deployment metadata/URLs; agreed escalation path for critical findings; budget controls per deployment.
- Secrets and configuration exposure detection
- Description: Detect client-side secret leaks and misconfigurations (e.g., API keys in JavaScript configs, overly permissive CORS, exposed admin interfaces).
- Sectors: SaaS, AI-enabled apps, front-end heavy platforms.
- Tools/products/workflows: Static-dynamic hybrid scan of served assets; rule packs emphasizing secret discovery and SSRF to cloud metadata endpoints.
- Assumptions/dependencies: Availability of served assets and endpoints; handling of obfuscated builds; acceptance of automated discovery in staging/prod mirrors.
- Rapid M&A/due diligence security checks
- Description: Quick autonomous assessments of target companies’ web assets with PoC-backed results to inform acquisition risk.
- Sectors: Finance, private equity, corporate development.
- Tools/products/workflows: Standardized due diligence workbook populated from MAPTA runs; evidence-backed risk scoring.
- Assumptions/dependencies: Legal permissions; scoped assets; time and cost budgets based on resource caps.
- Security education and lab exercises
- Description: Use XBOW + MAPTA to build hands-on courses on web security, multi-agent orchestration, and exploit validation.
- Sectors: Academia, bootcamps, corporate training.
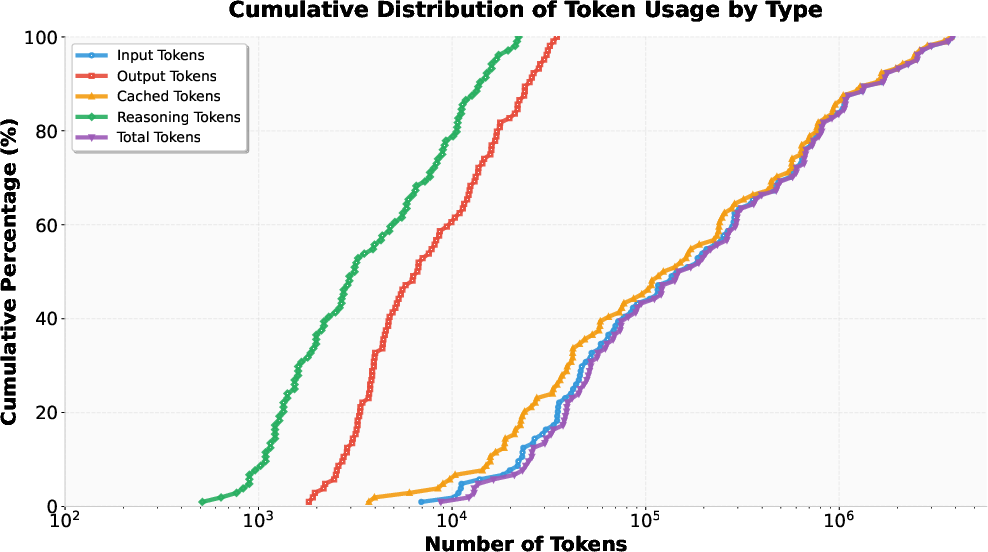
- Tools/products/workflows: Course modules that replicate CTF runs; “observability worksheets” leveraging UsageTracker to teach tradeoffs in tokens/cost/time/tool calls.
- Assumptions/dependencies: Classroom sandboxes; GPU/LLM access; curated exercises emphasizing categories where MAPTA performs well.
- “Autonomous Pentest as a Service” for SMEs and startups
- Description: Offer MAPTA-backed assessments at predictable costs, with optional retesting after remediation.
- Sectors: SMBs, startups, agencies.
- Tools/products/workflows: Managed service portal; scheduling; report generation with PoCs and remediation guidance; early-stop thresholds to protect budgets.
- Assumptions/dependencies: Intake forms defining scope/authorization; scalable Docker infrastructure; customer alignment on exploit execution in isolated environments.
Long-Term Applications
These applications require further research, scaling, or development to reach production-grade reliability.
- Timing-based and browser-centric exploitation improvements
- Description: Extend agents with headless browser instrumentation and robust timing channels to tackle blind SQLi (currently 0% success) and advanced XSS variants (57% success).
- Sectors: Software, e-commerce, ad-tech, social platforms.
- Tools/products/workflows: “Browser Agent” with DOM inspection, CSP analysis, event simulation; “Timing Oracle” for latency-based inference.
- Assumptions/dependencies: Reliable browser automation at scale; defenses against anti-bot; new training data for timing attacks; safe test harnesses.
- Autonomous code remediation and secure-by-default CI gates
- Description: Couple validated findings with automated patch generation and secure configuration hardening; propose PRs that include tests and PoC regression blockers.
- Sectors: Software, cloud, platforms with strict compliance.
- Tools/products/workflows: “AutoFixer” that drafts patches; policy engine requiring exploit-proof regression tests; integration with PenHeal-like remediation strategies.
- Assumptions/dependencies: High-quality code understanding; organizational acceptance of AI-suggested changes; human-in-the-loop review.
- Sector-specific adapters for regulated domains
- Description: Tailor agents for healthcare (FHIR/HL7), finance (PCI, payment flows), and public sector workflows, including business logic vulnerabilities and multi-step attack chains.
- Sectors: Healthcare, finance, government.
- Tools/products/workflows: Domain-specific exploit libraries; compliance-aware testing policies; canary placement for business workflow validation.
- Assumptions/dependencies: Deep domain models; legal and ethical guardrails; access to realistic test environments; data privacy constraints.
- Enterprise vulnerability management integration and governance
- Description: Embed MAPTA into enterprise platforms for asset inventory, risk scoring, SLA tracking, and budget-based scanning policies tied to risk tiers.
- Sectors: Large enterprises, MSPs, MSSPs.
- Tools/products/workflows: “Security Budget Controller” aligned with risk appetite; auto-prioritization based on exploit evidence; dashboards for audit readiness.
- Assumptions/dependencies: API integrations with existing VM tools; organizational change management; reliable models for cost-to-risk tradeoff.
- Standards and policy for autonomous penetration testing
- Description: Develop guidelines for permissioning, safe PoC execution, evidence handling, responsible disclosure, and audit trail requirements; advocate inclusion in frameworks (ISO/IEC, NIST, PCI).
- Sectors: Policy, compliance, audit.
- Tools/products/workflows: Standard operating procedures; certification schemes for autonomous pentesting; regulatory playbooks for AI-driven security audits.
- Assumptions/dependencies: Multi-stakeholder consensus; legal clarity on automated testing; regulator acceptance of PoC-based evidence.
- Marketplace products: on-prem appliances and sovereign deployments
- Description: Offer MAPTA as an on-prem appliance for privacy-sensitive sectors, or sovereign deployments with local LLMs to avoid data egress.
- Sectors: Defense, healthcare, finance, public sector.
- Tools/products/workflows: Hardened “Pentest Appliance” with local model serving; air-gapped Docker orchestration; compliance logging.
- Assumptions/dependencies: High-quality local LLMs; performance parity with cloud models; operational maturity.
- Multi-step business logic validation with canary instrumentation
- Description: Improve validation of complex workflows by inserting canaries and telemetry hooks into application paths; reduce false negatives for theoretical-but-stateful exploits.
- Sectors: Complex B2B SaaS, marketplaces, ERP/CRM systems.
- Tools/products/workflows: “Workflow Canary Injector”; exploit path tracing; policy-driven validation oracles for intended vs. unintended behavior.
- Assumptions/dependencies: Modifiable test environments; collaboration with app teams; standardized hooks.
- Security economics and risk quantification
- Description: Use MAPTA’s cost-performance telemetry (negative correlations between success and resource use) to inform risk models and budget policies.
- Sectors: CFO office, GRC, cybersecurity leadership.
- Tools/products/workflows: Budget-aware scanning strategies; cost-to-coverage analytics; risk thresholds that trigger deeper manual reviews.
- Assumptions/dependencies: Data aggregation across portfolios; mapping exploit classes to business impact; governance adoption.
- Continuous protection for no-code/low-code platforms
- Description: Embed agents directly into citizen developer platforms for real-time feedback and exploit blocking while users build apps.
- Sectors: No-code/low-code ecosystems, SMBs, internal tooling.
- Tools/products/workflows: Live “Security Coach” with exploit validation; default-safe component libraries; auto-hardening templates.
- Assumptions/dependencies: Platform integration; UX that balances guidance with freedom; scalable sandboxing; legal consent mechanisms.
- Expanded benchmarks and open-science artifacts
- Description: Grow reproducible datasets beyond XBOW, include modern SPAs, API-only backends, and microservice meshes; publish standardized protocols and Docker fixes.
- Sectors: Academia, industry R&D.
- Tools/products/workflows: New benchmark suites; reproducibility toolchains; community challenges for agent orchestration.
- Assumptions/dependencies: Sustained funding; community participation; coverage of excluded OWASP categories (A08/A09) and network-level issues.
Collections
Sign up for free to add this paper to one or more collections.