- The paper introduces a novel pairwise preference reward mechanism that directly combats reward hacking in text-to-image reinforcement learning.
- It harnesses flow matching models to reformulate policy advantages based on win rate comparisons, resulting in stable and human-aligned optimizations.
- Empirical results on a unified fine-grained T2I benchmark demonstrate significant improvements in semantic consistency and image quality.
Pairwise Preference Reward-based GRPO for Stable Text-to-Image Reinforcement Learning
Introduction and Motivation
The paper introduces Pref-GRPO, a novel reinforcement learning paradigm for text-to-image (T2I) generation that addresses the instability and reward hacking issues inherent in existing GRPO-based methods. Traditional approaches rely on pointwise reward models (RMs) to score generated images, followed by group normalization to compute policy advantages. However, these pointwise scores often exhibit minimal inter-image differences, which, when normalized, are disproportionately amplified, leading to illusory advantage and reward hacking—where reward scores increase but image quality degrades.
Pref-GRPO reformulates the optimization objective from absolute reward score maximization to pairwise preference fitting. This shift is motivated by the observation that human evaluators naturally make relative judgments between images, and that pairwise preference signals are more robust and discriminative for policy optimization.
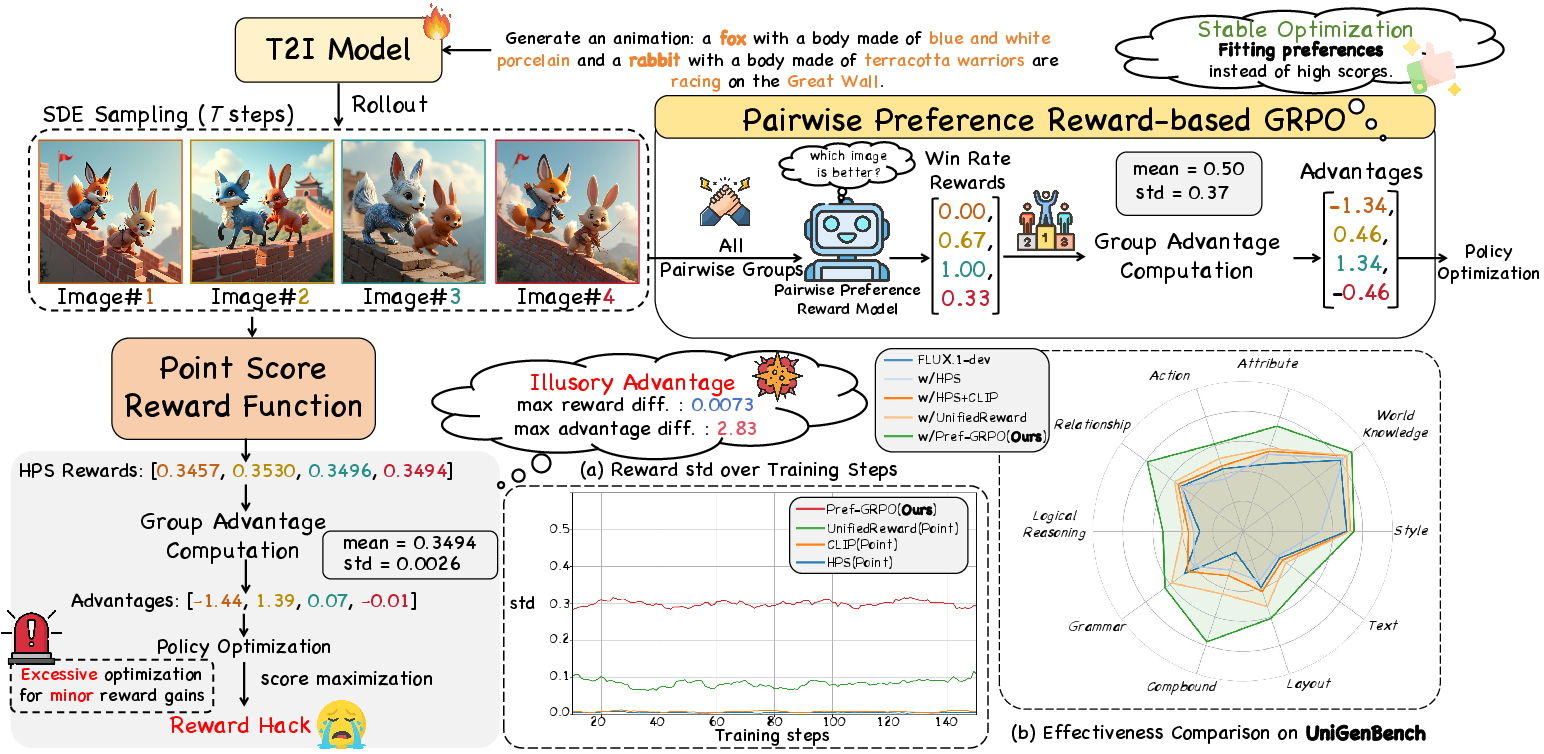
Figure 1: Pref-GRPO shifts the training objective from pointwise reward maximization to pairwise preference fitting, mitigating reward hacking and stabilizing T2I optimization.
Methodology
Flow Matching GRPO and Illusory Advantage
The paper builds on flow matching models, where the denoising process is cast as a Markov Decision Process. In standard GRPO, a group of G images is scored by a pointwise RM, and the advantage for each image is computed as:
A^ti=std({R(x0j,c)}j=1G)R(x0i,c)−mean({R(x0j,c)}j=1G)
When the RM assigns similar scores to all images, the standard deviation σr becomes very small, causing even minor score differences to be amplified. This leads to over-optimization for trivial cues and destabilizes training, as visualized in reward hacking trajectories.
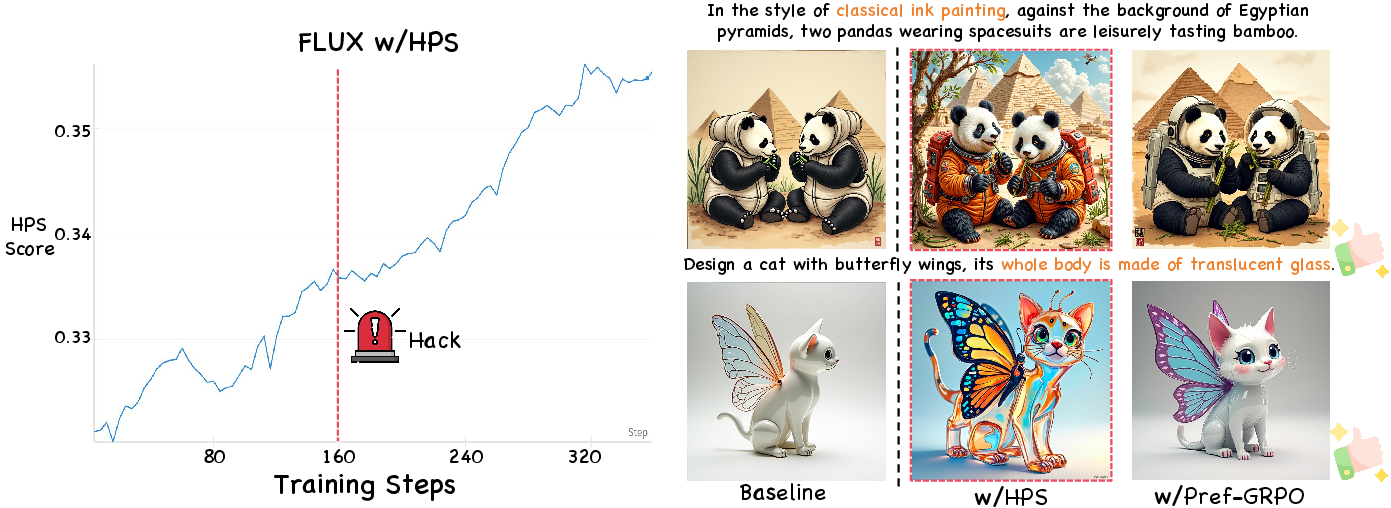
Figure 2: Reward hacking visualization: image quality degrades while reward scores continue to rise, indicating illusory advantage amplification.
Pairwise Preference Reward-based GRPO
Pref-GRPO leverages a Pairwise Preference Reward Model (PPRM) to compare all image pairs within a group, computing a win rate for each image:
wi=G−11j=i∑1(x0i≻x0j)
The win rates are then normalized to compute the policy advantage, replacing absolute scores. This approach yields:
- Amplified reward variance: High-quality images approach win rates near 1, low-quality near 0, producing a more separable and stable reward distribution.
- Robustness to reward noise: Relative rankings are less sensitive to small RM biases, reducing reward hacking.
- Alignment with human preference: Pairwise comparisons better capture nuanced quality differences.
Empirical results demonstrate that Pref-GRPO achieves more stable optimization and effectively mitigates reward hacking compared to pointwise RM-based methods.

Figure 3: Qualitative comparison: Pref-GRPO produces images with superior semantic alignment and perceptual quality versus pointwise RM-based GRPO methods.
Unified Fine-grained T2I Benchmark
The paper also introduces a unified benchmark for T2I generation, designed to provide comprehensive and fine-grained evaluation. The benchmark comprises 600 prompts spanning 5 main themes and 20 subthemes, covering 10 primary and 27 sub evaluation criteria. Each prompt targets multiple testpoints, enabling detailed assessment of semantic consistency and model capabilities.
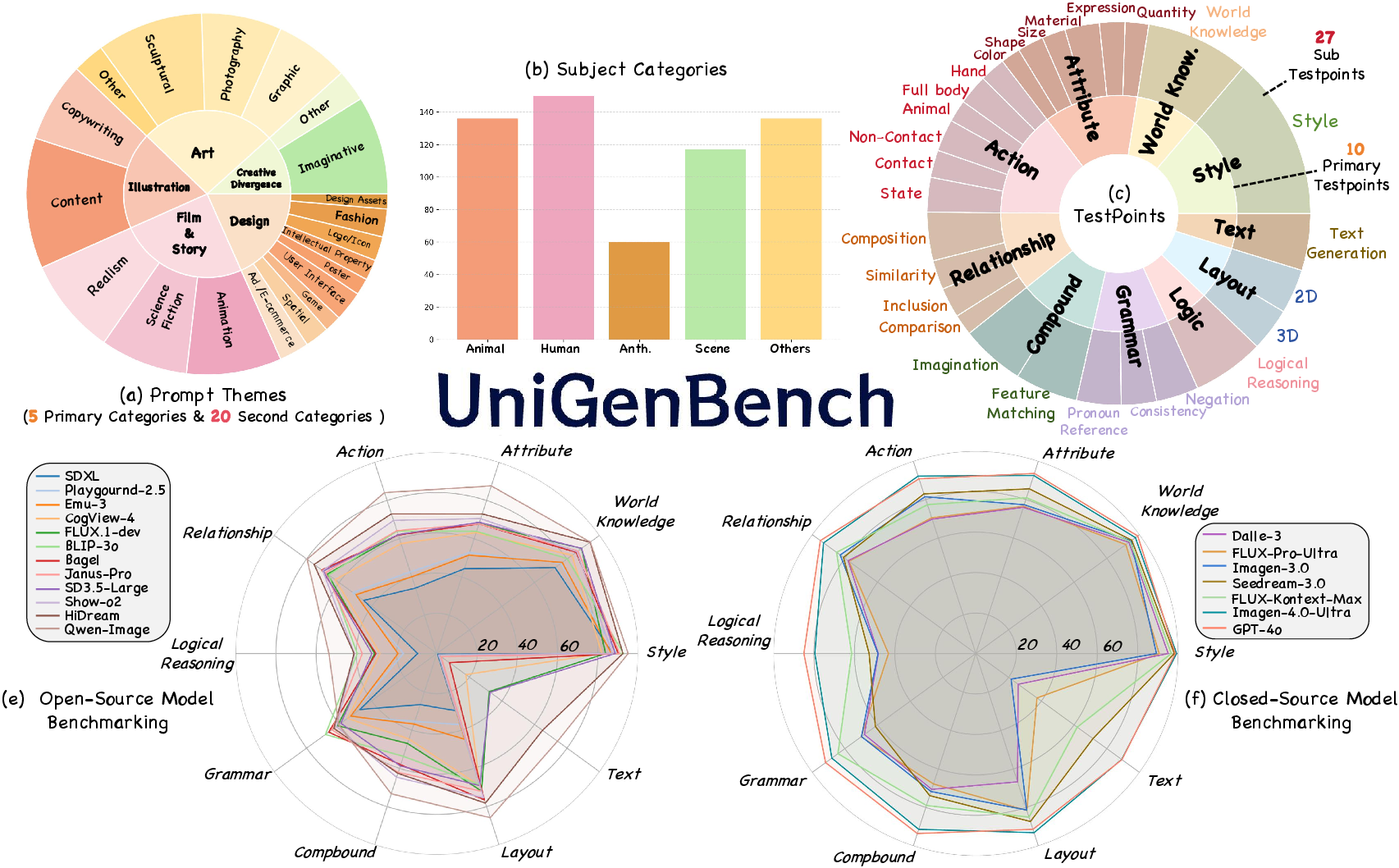
Figure 4: Benchmark statistics and evaluation results: prompt themes, subject distribution, and evaluation dimensions, with results for open- and closed-source T2I models.
Unlike prior benchmarks that only score primary dimensions, this benchmark supports fine-grained evaluation at both primary and sub-dimension levels.

Figure 5: Benchmark comparison: the proposed benchmark enables fine-grained evaluation across both primary and sub dimensions.
Automated Benchmark Construction and Evaluation
The benchmark construction and evaluation pipeline leverages a Multi-modal LLM (MLLM), specifically Gemini2.5-pro, for prompt generation and scalable T2I evaluation. Prompts and testpoint descriptions are generated systematically, and model outputs are evaluated by the MLLM for both quantitative scores and qualitative rationales.
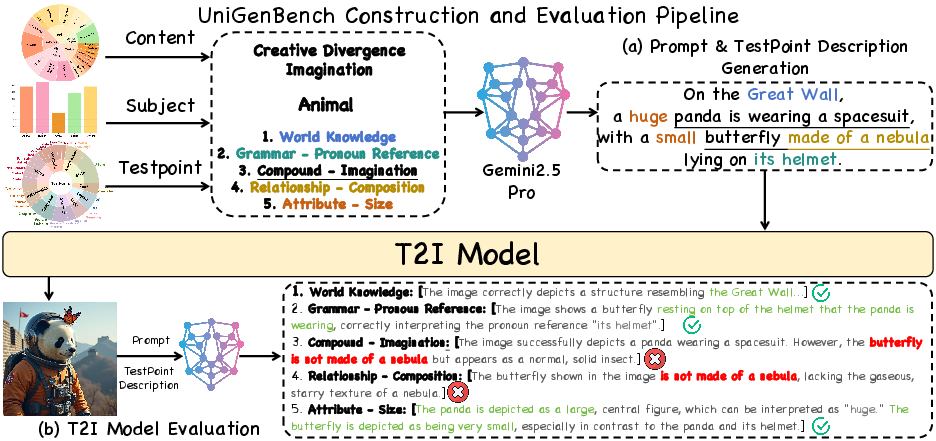
Figure 6: Construction and evaluation pipeline: MLLM enables large-scale prompt generation and fine-grained T2I evaluation.
Experimental Results
Quantitative and Qualitative Analysis
Pref-GRPO demonstrates substantial improvements in both semantic consistency and image quality. On the unified benchmark, Pref-GRPO achieves a 5.84% increase in overall score compared to UR-based score-maximization, with notable gains in text rendering (+12.69%) and logical reasoning (+12.04%). Out-of-domain evaluations (GenEval, T2I-CompBench) further confirm the method's superiority.
Qualitative analysis reveals that pointwise RM-based methods (e.g., HPS, UR) exhibit reward hacking artifacts such as oversaturation or darkening, while Pref-GRPO maintains stable and high-quality generation.

Figure 7: UnifiedReward score-based winrate as reward: converting scores to win rates mitigates reward hacking, but pairwise preference fitting yields even better stability.
Ablation and Trade-off Studies
Experiments show that increasing sampling steps during rollout improves performance up to 25 steps, beyond which gains saturate. Joint optimization with CLIP enhances semantic consistency but slightly degrades perceptual quality, reflecting a trade-off between semantic alignment and visual fidelity.

Figure 8: Joint optimization with CLIP: improved semantic consistency at the expense of perceptual quality, illustrating the trade-off.
Benchmarking State-of-the-Art T2I Models
Closed-source models (GPT-4o, Imagen-4.0-Ultra) lead across most dimensions, especially logical reasoning and text rendering. Open-source models (Qwen-Image, HiDream) are closing the gap, with strengths in action, layout, and attribute dimensions. However, both categories exhibit limitations in challenging dimensions, and open-source models show greater instability across tasks.
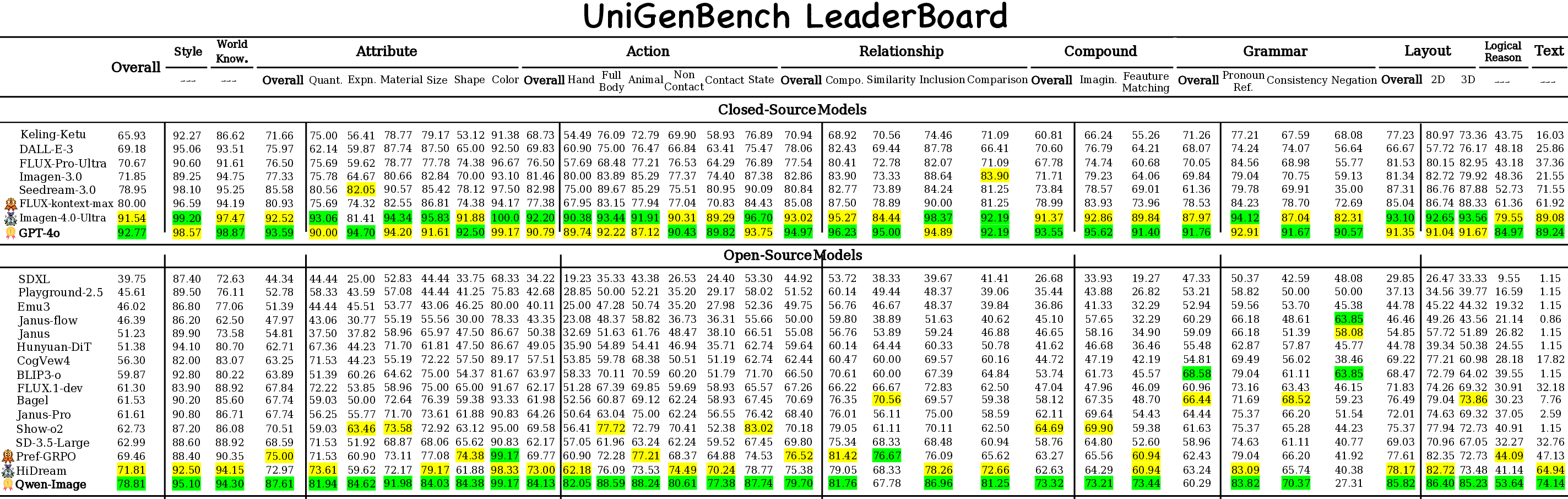
Figure 9: Fine-grained benchmarking results: best scores in green, second-best in yellow, highlighting strengths and weaknesses across models.
Implementation Considerations
Pref-GRPO training requires substantial computational resources (e.g., 64 H20 GPUs, 25 sampling steps, 8 rollouts per prompt). The pairwise preference RM server is deployed via vLLM for efficient inference. The method is compatible with flow matching models and can be integrated with other reward models for joint optimization. The benchmark pipeline eliminates the need for human annotation, leveraging MLLM for scalable and reliable evaluation.
Implications and Future Directions
Pref-GRPO provides a principled solution to reward hacking in T2I RL, enabling more stable and human-aligned optimization. The unified benchmark sets a new standard for fine-grained evaluation, facilitating rigorous assessment of model capabilities. Future work may explore more sophisticated preference modeling, adaptive reward mechanisms, and further integration of semantic and perceptual objectives. The methodology is extensible to other generative domains where reward hacking and evaluation granularity are critical concerns.
Conclusion
Pref-GRPO introduces a pairwise preference reward-based GRPO framework that stabilizes T2I reinforcement learning and mitigates reward hacking. The unified benchmark enables comprehensive and fine-grained evaluation of T2I models. Extensive experiments validate the effectiveness of the proposed method and benchmark, providing actionable insights for future research and development in text-to-image generation.

