- The paper introduces an online incremental learning framework for audio classification that leverages fixed pretrained embeddings with a nonlinear expansion layer to improve class separability.
- It applies prototype-based classification by incrementally updating Gram and class prototype matrices without iterative fine-tuning or accessing previous task data.
- Experimental evaluations on ESC-50 and TAU datasets demonstrate higher average accuracy and reduced forgetting compared to baseline methods.
Online Incremental Learning for Audio Classification Using a Pretrained Audio Model
Introduction
This paper addresses the challenge of online incremental learning for audio classification, focusing on both class-incremental learning (CIL) and domain-incremental learning (DIL) scenarios. The proposed method leverages generalizable audio embeddings from a fixed, pretrained model (PANNs CNN14) and introduces a nonlinear expansion layer to enhance the discriminability of these embeddings. Unlike prior approaches that require iterative fine-tuning or access to previous task data, this method adapts to new tasks in a single forward pass, minimizing catastrophic forgetting and computational overhead.
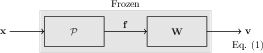

Figure 1: Overview of the proposed method. (a) Extracted features f from a frozen pre-trained model P for given input samples x are projected into a higher-dimensional space using frozen random weights W, followed by a nonlinear activation function. (b) Gram (G) and class prototypes (K) matrices are iteratively updated and used to compute Wo by matrix inversion at each incremental task for prediction of classes seen so far.
Methodology
Incremental Learning Setup
The incremental learning protocol is defined over a sequence of T supervised audio classification tasks D1,…,DT. In CIL, each task introduces disjoint class labels, while in DIL, the same set of classes is present across tasks but with domain shifts (e.g., different cities). The model is restricted from accessing previous task data, enforcing a realistic continual learning constraint.
Feature Expansion and Nonlinear Projection
For each input sample, embeddings ft,m∈RH are extracted from the frozen pretrained model. These embeddings are projected into a higher-dimensional space (Q) using a random matrix W∈RH×Q, followed by a nonlinear activation (ReLU):
vt,m=ψ(ft,m⊤W)
This expansion increases the representational capacity and improves class separability, as confirmed by ablation studies.
The method maintains a Gram matrix G and a class prototypes matrix K, updated incrementally:
G=t=1∑Tm=1∑Mtvt,m⊗vt,m
K=t=1∑Tm=1∑Mtvt,m⊗yt,m
To mitigate prototype correlation, the classification weight matrix is computed via regularized inversion:
Wo=(G+λI)−1K
where λ is selected per task to minimize validation error. Prediction is performed by multiplying the test embedding with Wo.
Experimental Setup
Datasets
- CIL: ESC-50 (50 classes, 5 tasks, each with 10 classes)
- DIL: TAU Urban Acoustic Scenes 2019 (10 classes, 9 domains/cities, each as a task)
Baselines
- Linear Probe (LP): Trained per task, no access to previous data.
- Joint Linear Probe (JLP): Trained on all data seen so far (not strictly incremental).
- Nearest Class Mean (NCM): Prototype-based, using averaged embeddings.
Implementation Details
- Embeddings: 2048-dim from PANNs CNN14
- Projection dimension Q: 8192 (selected via ablation)
- Nonlinearity: ReLU
- Training: Single forward pass (online); baselines also evaluated in offline (multi-epoch) mode
Results
The proposed method achieves superior average accuracy and minimal forgetting in both CIL and DIL setups, outperforming all baselines, including the joint linear probe.
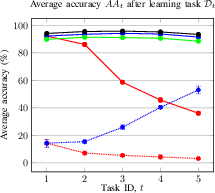
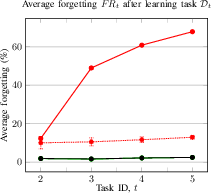
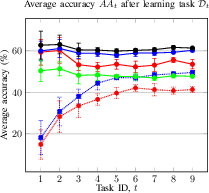
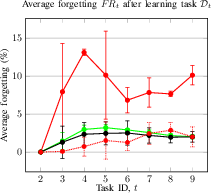
Figure 2: Average accuracy and forgetting of the methods after learning the task Dt. Average accuracy (a) and forgetting (b) of the current Dt and previously seen tasks in a CIL setup; Average accuracy (c) and forgetting (d) of the current Dt and previously seen tasks in a DIL setup.
- CIL (ESC-50): Final average accuracy AAT of 93.4% (proposed) vs. 91.5% (JLP) and 88.5% (NCM); forgetting FRT of 2.5% (proposed).
- DIL (TAU): Final average accuracy AAT of 61.4% (proposed) vs. 60.3% (JLP) and 47.7% (NCM); forgetting FRT of 2.0% (proposed).
The method demonstrates strong stability-plasticity trade-off, maintaining high accuracy on previously learned tasks while adapting to new ones.
Ablation Studies
Ablations confirm the necessity of both projection to higher dimensions and nonlinear activation. Removing either degrades performance significantly.
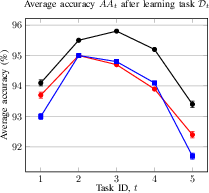
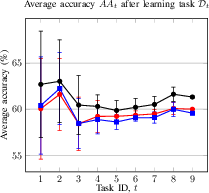
Figure 3: Impact of the proposed method compared to alternatives without projection to Q dimension using Eq. (\ref{eq1}) and without ReLU. (a) Average accuracy of CIL setup; (b) average accuracy of DIL setup.
Effect of Projection Dimension
Increasing Q improves accuracy but increases computational cost. Q=8192 is selected as a practical trade-off.
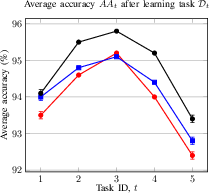
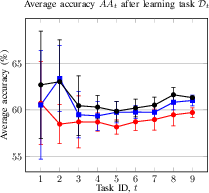
Figure 4: Performance of the proposed method using different Q dimensional values. (a) Average accuracy of CIL setup; (b) average accuracy of DIL setup.
Implementation Considerations
- Computational Requirements: The method requires updating Q×Q and Q×C matrices per task. For Q=8192 and C=50, this is tractable compared to the 80.8M parameters of the CNN14 backbone.
- Deployment: The approach is suitable for resource-constrained or privacy-sensitive scenarios, as it does not require storage of previous data or retraining of the backbone.
- Scalability: The method is fully online, requiring only a single pass through new task data, making it amenable to streaming or real-time applications.
Implications and Future Directions
The results demonstrate that fixed pretrained audio models, when augmented with nonlinear expansion and decorrelated prototype-based classification, can serve as effective continual learners in both class- and domain-incremental settings. This approach obviates the need for iterative fine-tuning or replay buffers, simplifying deployment in practical scenarios.
Future work may explore:
- Application to other pretrained audio models (e.g., AST, PaSST, SSAST)
- Extension to multi-label or event detection tasks
- Optimization of projection dimension and regularization for large-scale deployments
- Integration with parameter-efficient transfer learning techniques
Conclusion
This paper presents a unified, online incremental learning framework for audio classification that leverages fixed pretrained embeddings and nonlinear expansion for robust adaptation to new tasks. The method achieves state-of-the-art performance in both CIL and DIL setups, with minimal forgetting and efficient computation, making it highly suitable for real-world continual learning applications in audio.