Efficient Forkless Blockchain Databases (2508.20686v1)
Abstract: Operating nodes in an L1 blockchain remains costly despite recent advances in blockchain technology. One of the most resource-intensive components of a node is the blockchain database, also known as StateDB, that manages balances, nonce, code, and the persistent storage of accounts/smart contracts. Although the blockchain industry has transitioned from forking to forkless chains due to improved consensus protocols, forkless blockchains still rely on legacy forking databases that are suboptimal for their purposes. In this paper, we propose a forkless blockchain database, showing a 100x improvement in storage and a 10x improvement in throughput compared to the geth-based Fantom Blockchain client.
Collections
Sign up for free to add this paper to one or more collections.
Summary
- The paper introduces a novel StateDB architecture that separates live and archival data, achieving a 10x throughput boost with a 98% storage reduction.
- It employs role-based specialization with LiveDB for current state and ArchiveDB for historical data, eliminating redundant data copying and pruning overhead.
- Experimental evaluations using 50 million blocks show dramatic improvements compared to legacy Merkle Patricia Trie-based systems, validated through Golang implementations.
Efficient Forkless Blockchain Databases: Architecture, Implementation, and Evaluation
Introduction and Motivation
The paper "Efficient Forkless Blockchain Databases" (2508.20686) addresses the persistent inefficiencies in blockchain state management, particularly for forkless blockchains utilizing modern consensus protocols. While consensus mechanisms have evolved to eliminate forking and achieve high throughput, the underlying state database (StateDB) remains largely unchanged, relying on legacy data structures such as the Merkle Patricia Trie (MPT). These structures are optimized for forking semantics, resulting in significant computational and storage overheads in forkless environments. The authors propose a specialized database architecture that separates live and archival state management, yielding substantial improvements in both throughput and storage efficiency.
Critique of Legacy StateDBs and MPTs
The MPT is designed to support multiple versions of the blockchain state, accommodating forks by maintaining several roots and enabling efficient authentication via root hashes. However, in forkless blockchains, this multi-versioning is unnecessary and introduces redundant data copying, excessive pruning requirements, and storage bloat. The paper illustrates this with a formal example and a diagram of MPT evolution, showing how a single state update leads to path duplication and unnecessary retention of obsolete data.
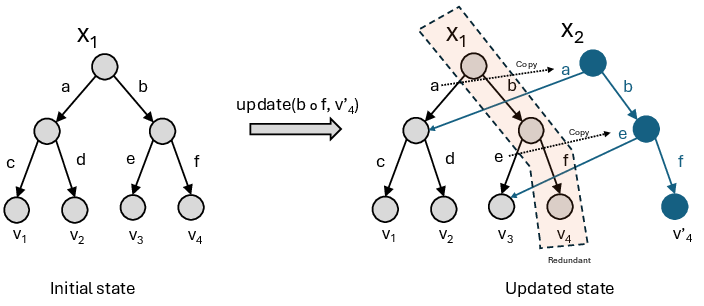
Figure 1: Evolution of Merkle Patricia Trie: A new version of state x1 is constructed, resulting in a new state x2 by updating the value v4 to v4′ for the key b⋅f.
Profiling studies indicate that up to 75% of block processing time in forkless blockchains is spent on storage access, and nodes must store terabytes of data, severely limiting scalability and accessibility.
Role-Based StateDB Specialization
The authors introduce a role-based specialization of the StateDB, decomposing it into two distinct components:
- LiveDB: Used by validator and observer nodes, this database maintains only the latest state, enabling direct overwriting and intrinsic pruning.
- ArchiveDB: Used by archival nodes, this database stores the entire history of state transitions, optimized for efficient delta updates and log-structured storage.
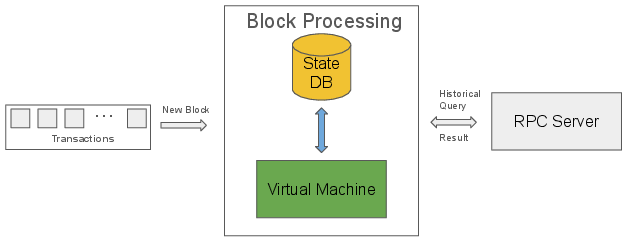
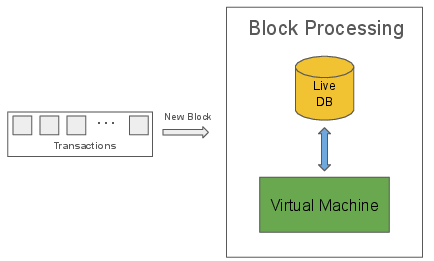
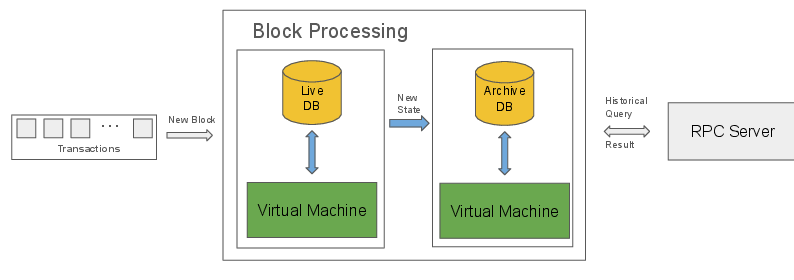
Figure 2: Unspecialized Database Design.
This separation allows each node type to operate with a database tailored to its requirements, eliminating the overhead of maintaining unnecessary historical states for validators and observers.
LiveDB: Intrinsic Pruning and Dense Storage
LiveDB is engineered for high-throughput, low-latency access to the current blockchain state. Its design features include:
- Normalization via Indexers: Account addresses and storage keys are mapped to record numbers using I/O-efficient hashmaps (linear hashing), enabling constant-time access to attributes and storage values.
- Dense Binary Storage: Attributes are stored in fixed-length records in binary files, allowing direct seek operations and minimizing disk footprint.
- Lazy Hash Calculation: Hashes are computed on demand using a lazily executed prefix sum algorithm, with dirty flags marking changed attributes. This avoids unnecessary rehashing and leverages parallelism for efficient hash tree updates.
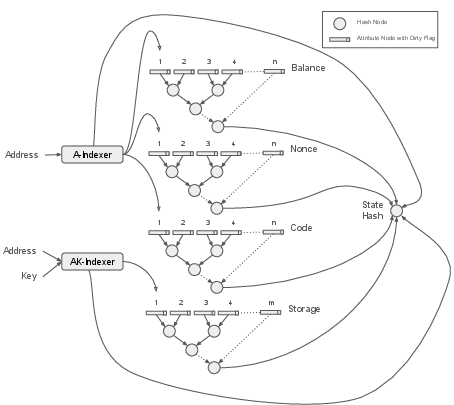
Figure 3: Hash calculation mechanism: Hashes are aggregated for attributes/storage values across all accounts, and indexers produce hashes for their stored keys.
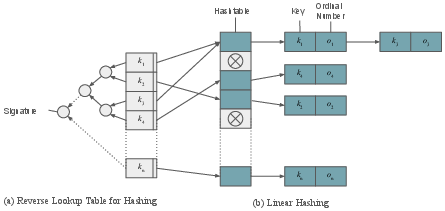
Figure 4: Indexer: An indexer consists of a hash table that maps account addresses/storage keys to record numbers and a reverse lookup table that stores the addresses/keys file-mapped array permitting dense hash calculations on the reverse lookup table.
- Paging Optimization: Attributes and storage values are aggregated into pages of fixed size, reducing the number of hash tree leaves and improving the computational-space trade-off.
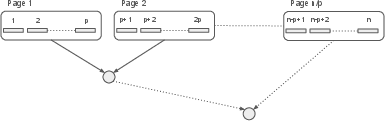
Figure 5: Paging mechanism: pn pages where p elements of an attribute are packed into a page.
The design assumes deterministic ordering of key insertions across nodes to ensure hash consistency, a reasonable constraint in forkless environments.
ArchiveDB: Efficient Historical State Management
ArchiveDB is optimized for archival nodes that require access to historical states. Its key features include:
- Log-Structured Storage: State changes are recorded as tuples [account, key, block, value], sorted by account and block number. This enables efficient retrieval of historical values via range queries.
- Delta Updates: Only changes between blocks are stored, minimizing redundant data copying and hash recalculation.
- Immutable Entries: Log entries are appended and never overwritten, allowing concurrent reads and writes without locking.
- Incremental Hashing: Hashes are computed per account and block, combining previous hashes with current updates in a lexicographically ordered sequence.
Implementation Details
The system is implemented in Golang, with three variants for LiveDB: in-memory, file-based, and LevelDB-backed. The file-based implementation utilizes custom primitives:
- PagePool: Manages in-memory and on-disk pages.
- Array: Persistent, indexable structure for values.
- Linear Hash: Persistent hash table for key-to-value mapping.
- HashTree: Computes Merkle proofs over pages.
- LruCache: Caches frequently accessed keys.
ArchiveDB is implemented using commodity software (SQLite for SQL variant, LevelDB for key-value variant), with schema initialization and prepared statements for performance.
Experimental Evaluation
Throughput
The authors replayed 50 million blocks from the Fantom mainnet on identical hardware, comparing the original MPT-based database to the new file-based LiveDB and ArchiveDB variants. The results show:
- LiveDB achieves ~5,000 tx/s, compared to ~500 tx/s for MPT, a 10x throughput improvement.
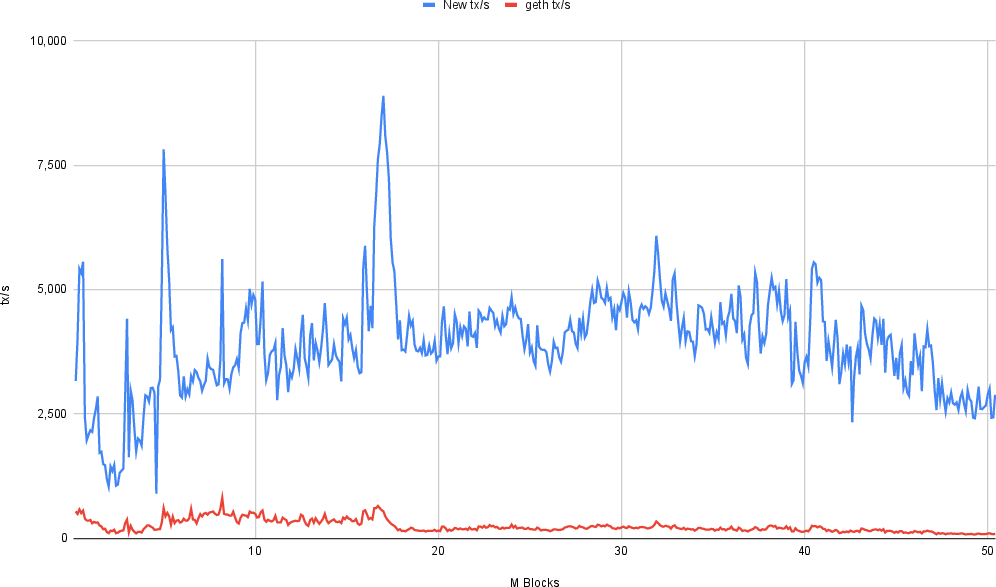
Figure 6: Transaction throughput comparison between original database (geth) and our New system. The new system is more than 10 times faster, featuring ~5.000 tx/s vs. below 500 tx/s for the MPT.
Enabling ArchiveDB (both SQL and Key/Value variants) does not incur significant performance degradation.
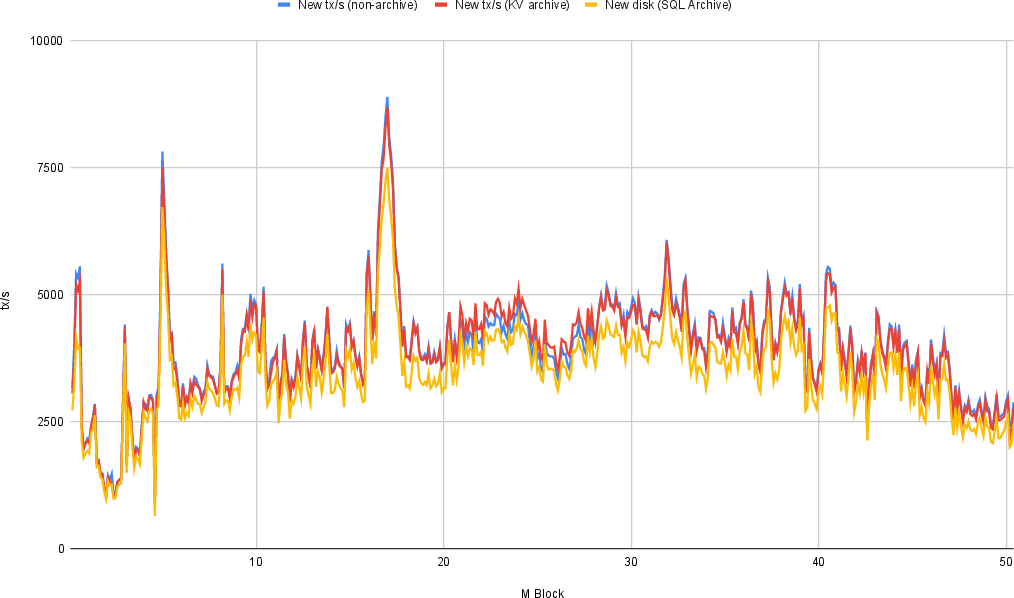
Figure 7: Throughput comparison of LiveDB and two variants of ArchiveDB; the Archive does not incur any significant slowdown.
Storage Efficiency
After processing 50 million records:
- LiveDB requires 30 GB, compared to 1,600 GB for pruned MPT.
- ArchiveDB requires 140–550 GB, compared to 17 TB for MPT archive.
This represents a 98% reduction in storage requirements.
Page Size Optimization
Microbenchmarks indicate that a page size of 4 KB is optimal for both in-memory and I/O-constrained environments.
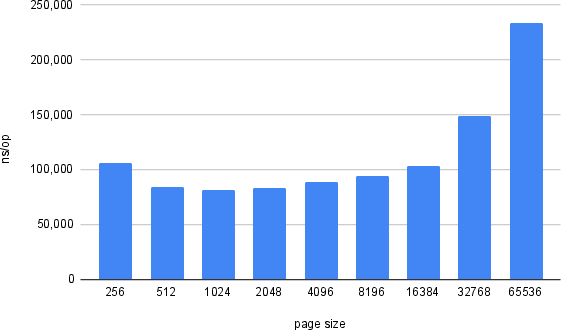
Figure 8: Time in nanoseconds to compute hash for varying page sizes on LiveDB in memory using microbenchmark; smaller page sizes are better.
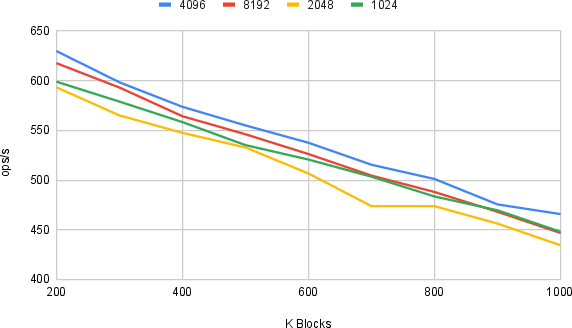
Figure 9: Number of hashes computed per second for varying page sizes utilizing I/O. Legend shows page sizes. The page size 4096 is optimal.
Theoretical and Practical Implications
The proposed architecture demonstrates that legacy state management solutions are fundamentally misaligned with the requirements of forkless blockchains. By specializing the StateDB according to node roles and leveraging dense, mutable data structures, the system achieves dramatic improvements in both throughput and storage efficiency. The separation of live and archival state management enables scalable operation for validators and observers, while archival nodes benefit from efficient historical queries and minimal redundancy.
The approach also highlights the importance of deterministic state construction and the potential for further optimizations in hash calculation and storage layout. The results challenge the prevailing assumption that authenticated storage must rely on trie-based structures, suggesting that alternative designs can offer superior performance in forkless environments.
Future Directions
Potential avenues for future research include:
- Extending the architecture to support sharded or multi-chain environments.
- Investigating concurrency control and parallelism in state updates.
- Exploring hardware acceleration for hash calculations and storage access.
- Integrating advanced compression schemes for further storage reduction.
- Formalizing consistency guarantees and certificate mechanisms for state exchange.
Conclusion
The paper presents a comprehensive solution to the inefficiencies of legacy state databases in forkless blockchains. By introducing role-based specialization and novel data structures, the authors achieve 100x storage reduction and 10x throughput improvement over the MPT-based baseline. The results have significant implications for the scalability, accessibility, and operational cost of blockchain systems, providing a foundation for future developments in high-performance, forkless blockchain infrastructure.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Follow-up Questions
- How does role-based specialization in StateDB enhance blockchain performance?
- What are the key differences between LiveDB and ArchiveDB in terms of their data management strategies?
- In what ways does the new StateDB design overcome the inefficiencies of the traditional Merkle Patricia Trie?
- What implications do the throughput and storage improvements have for the scalability of forkless blockchains?
- Find recent papers about efficient blockchain state management.
Related Papers
- Narwhal and Tusk: A DAG-based Mempool and Efficient BFT Consensus (2021)
- State sharding model on the blockchain (2020)
- FastFabric: Scaling Hyperledger Fabric to 20,000 Transactions per Second (2019)
- BLOCKBENCH: A Framework for Analyzing Private Blockchains (2017)
- BlockReduce: Scaling Blockchain to Human Commerce (2018)
- Untangling Blockchain: A Data Processing View of Blockchain Systems (2017)
- A Scalable State Sharing Protocol for Low-Resource Validator Nodes in Blockchain Networks (2024)
- QMDB: Quick Merkle Database (2025)
- Boosting Blockchain Throughput: Parallel EVM Execution with Asynchronous Storage for Reddio (2025)
- Comparative Analysis of Blockchain Systems (2025)
Authors (4)
alphaXiv
- Efficient Forkless Blockchain Databases (5 likes, 0 questions)