- The paper presents unified modeling with novel data augmentation, achieving an 8.31-point increase in Team-mAP@1 for action spotting.
- It demonstrates robust methodologies in monocular depth estimation and multi-view foul recognition via high-resolution training and transformer architectures.
- It achieves significant gains in game state reconstruction by integrating YOLO-X, ReID, and vision-language models for precise identity tracking and spatial mapping.
The SoccerNet 2025 Challenges represent the fifth iteration of a comprehensive benchmarking effort targeting computer vision tasks in football video analysis. This edition introduces four distinct tasks—Team Ball Action Spotting, Monocular Depth Estimation, Multi-View Foul Recognition, and Game State Reconstruction—each designed to address unique spatio-temporal and semantic reasoning challenges in broadcast football footage. The competition attracted over 280 participants, with submissions consistently surpassing strong baselines and introducing novel methodologies that advance the state of the art in sports video understanding.
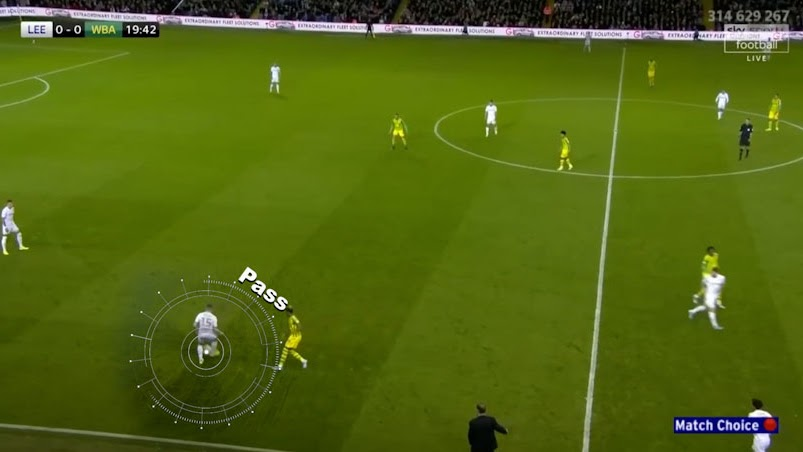

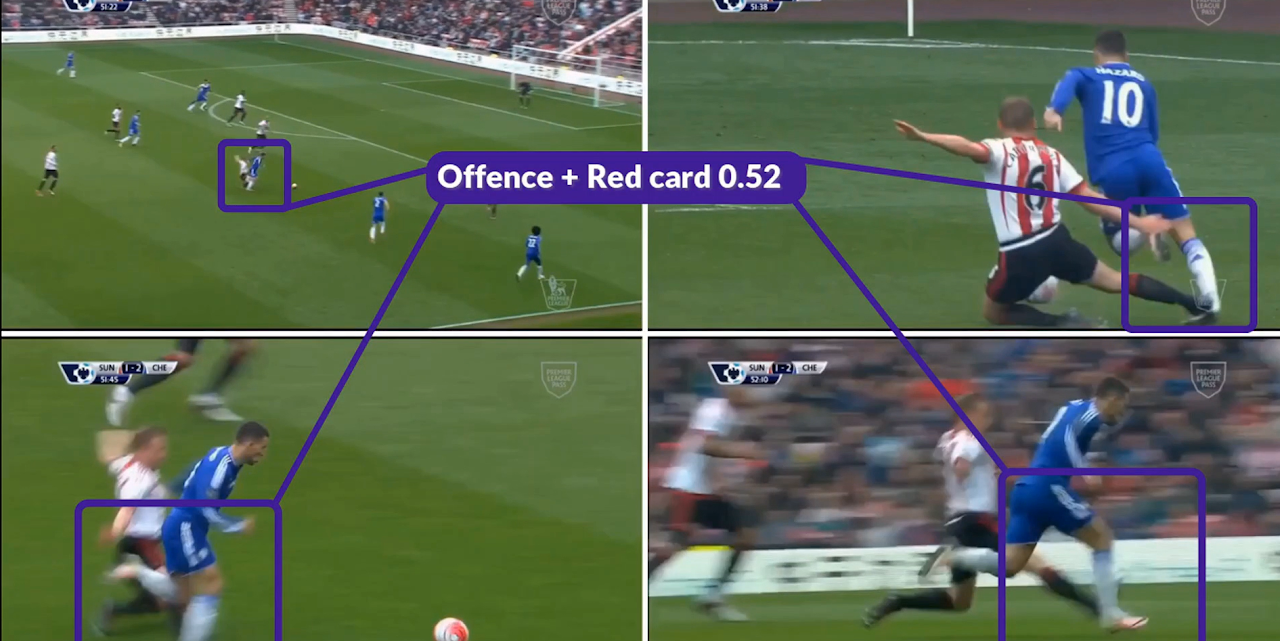
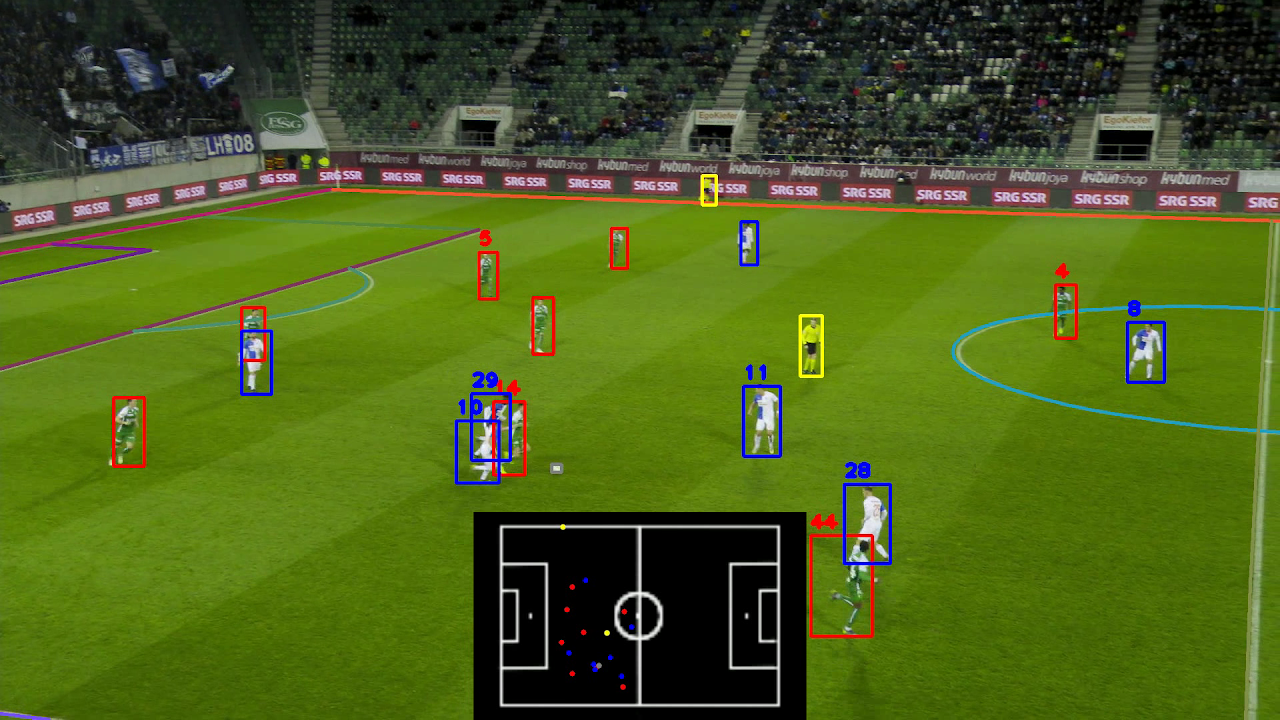
Figure 1: The four SoccerNet 2025 challenge tasks: (1) Team Ball Action Spotting, (2) Monocular Depth Estimation, (3) Multi-View Foul Recognition, and (4) Game State Reconstruction.
Task Overview and Methodological Innovations
Team Ball Action Spotting
This task extends prior action spotting benchmarks by requiring not only the temporal localization and classification of 12 ball-related actions but also the attribution of each action to the correct team (left/right relative to the camera). The evaluation metric, Team-mAP@1, is a team-aware extension of mean Average Precision, computed with a 1-second temporal tolerance.
The top-performing solution replaced the dual-head architecture of T-DEED with a unified head predicting joint action-team classes, eliminating redundant non-action states and improving temporal precision. Data augmentation strategies included horizontal mirroring with label swapping, synthetic camera pan, and brightness jitter. Training was staged: large-scale pretraining on 500+ matches, followed by dense fine-tuning on the challenge set. Bayesian hyperparameter optimization was used for learning rate, focal loss, anchor scales, and NMS thresholds. The winning method achieved a Team-mAP@1 of 60.03, an 8.31-point improvement over the baseline.
Key observations include the critical impact of team modeling strategies: unified action-team prediction outperformed separate heads, and post-processing leveraging action dependencies (e.g., aligning team labels for sequential actions) further improved results. Methods that ignored team identity, even if strong on action-only mAP, ranked lower on the team-aware metric, underscoring the necessity of explicit team modeling.
Monocular Depth Estimation
This task focuses on predicting per-pixel relative depth maps from single RGB frames, using synthetic data rendered from sports video games. The primary metric is RMSE, with additional reporting of AbsRel and SILog.
The leading approach fine-tuned the Depth Anything V2 ViT-L model using a combination of Scale-and-Shift Invariant (SSI) and Gradient Matching (SSIGM) losses, with domain-specific augmentations (color, geometric) and full-resolution inputs (1918×1078). The model achieved an RMSE of 2.418×10−3, outperforming the baseline by 1.339×10−3. Other notable methods included motion-aware depth estimation (MADE), which used inter-frame motion masks to focus learning on dynamic regions, and player-aware refinement pipelines that applied secondary UNet models to correct depth in player regions, leveraging segmentation masks from YOLOv8 or SAM2.
The results demonstrate that high-resolution training, motion awareness, and region-specific supervision are essential for accurate depth estimation in dynamic, occlusion-heavy sports scenes. The use of synthetic data, while limiting absolute metric depth, enables robust ordinal depth learning transferable to real-world scenarios.
Multi-View Foul Recognition
This task requires classifying both the type and severity of fouls from synchronized multi-view video clips, using the SoccerNet-MVFouls dataset. The evaluation metric is the average of balanced accuracies for foul type and severity.
The winning solution employed a single TAdaFormer-L/14 transformer, pre-trained on Kinetics datasets, with view-specific learnable embeddings to distinguish live and replay views. Multi-view aggregation was performed via max pooling before the classification head. Training was staged: initial fine-tuning on 720p videos with random view selection, followed by feature extraction with random augmentations and retraining of classification heads on all available views. This two-stage approach closed the train-inference gap and improved the combined balanced accuracy to 52.22%, a 7.46% increase over the previous year's winner.
Other teams explored zero-shot video LLM prompting, adaptive hybrid pooling for multi-view fusion, and retrieval-augmented LLM reasoning. The results highlight the effectiveness of large-scale temporal transformers, view-specific context modeling, and multi-stage training for robust multi-view video understanding.
Game State Reconstruction
This task involves reconstructing the full game state—player locations, roles, jersey numbers, and team affiliations—on a 2D top-view map from monocular broadcast video. The GS-HOTA metric, an extension of HOTA, jointly evaluates localization and identity matching.
The top-ranked pipeline integrated YOLO-X for detection, Deep-EIoU and OSNet-based ReID for tracking, and a multi-frame keypoint model for pitch mapping. Athlete identity was estimated via multimodal autoregressive generation using LLaMA-3.2-Vision, with instruction-based prompts for role, jersey, and color. Tracklets were refined using split-and-merge strategies based on identity consistency and ReID similarity. Team affiliation was inferred by clustering jersey colors and spatial positions. Post-processing included majority voting and trajectory filtering for identity consistency. This approach achieved a GS-HOTA of 63.90, more than doubling the baseline.
Other strong submissions leveraged advanced detectors (YOLOv8, RF-DETR), CLIP-based ReID, optical flow for temporal smoothing, and VLMs for jersey number recognition. The field has converged on tracking-by-detection with modular post-processing, but innovations in identity modeling and calibration remain key differentiators.
Numerical Results and Comparative Analysis
Across all tasks, the best submissions significantly outperformed the provided baselines:
| Task |
Baseline Score |
Best Score |
Metric |
Notable Gain |
| Team Ball Action Spotting |
51.72 |
60.03 |
Team-mAP@1 |
+8.31 |
| Monocular Depth Estimation |
3.757e-3 |
2.418e-3 |
RMSE |
-1.339e-3 |
| Multi-View Foul Recognition |
36.99 |
52.22 |
Combined BA |
+15.23 |
| Game State Reconstruction |
29.01 |
63.90 |
GS-HOTA |
+34.89 |
These improvements are attributable to architectural advances (unified heads, large transformers), domain-specific augmentations, multi-stage training, and the integration of VLMs and ReID for identity tasks.
Implications and Future Directions
The SoccerNet 2025 Challenges have catalyzed progress in several key areas:
- Unified Spatio-Temporal Modeling: The success of unified heads and large temporal transformers suggests that joint modeling of spatial, temporal, and semantic cues is critical for complex sports understanding tasks.
- Synthetic Data Utilization: The effective use of synthetic data for depth estimation demonstrates its viability for training models where real-world ground truth is scarce or ambiguous.
- Vision-Language Integration: The application of VLMs for jersey number recognition and zero-shot foul classification indicates a trend toward multimodal, instruction-based models for open-set recognition and reasoning.
- Scalable, Modular Pipelines: The convergence on modular, tracking-by-detection pipelines with robust post-processing and calibration modules points to scalable solutions deployable in real-world broadcast settings.
Future research will likely focus on:
- Generalization to Unseen Domains: Improving robustness to domain shifts, e.g., from synthetic to real or across leagues and camera setups.
- End-to-End Multimodal Reasoning: Integrating vision, language, and structured priors for holistic scene understanding and explainable decision-making.
- Real-Time and Resource-Efficient Inference: Optimizing architectures for deployment in live broadcast and analytics environments.
Conclusion
The SoccerNet 2025 Challenges have established new benchmarks for vision-based football understanding, with substantial advances in action spotting, depth estimation, foul recognition, and game state reconstruction. The competition has driven methodological innovation, highlighted the importance of unified and multimodal modeling, and set the stage for future research at the intersection of computer vision, AI, and sports analytics. The open datasets, standardized protocols, and strong baselines provided by SoccerNet will continue to serve as a foundation for reproducible and impactful research in this domain.

