- The paper presents USO, a unified framework that disentangles and recombines content and style features for enhanced image generation.
- It employs a novel triplet curation pipeline and DiT-based latent diffusion backbone to improve style fidelity and subject consistency, evidenced by superior CLIP-I, DINO, and CSD scores.
- Ablation studies confirm the critical role of style reward learning, hierarchical projection, and disentangled encoders in advancing multi-conditional generative modeling.
Unified Style and Subject-Driven Generation via Disentangled and Reward Learning: An Expert Analysis
Introduction and Motivation
The USO framework addresses a central challenge in conditional image generation: the disentanglement and recombination of content and style features from reference images. Prior work has treated style-driven and subject-driven generation as distinct tasks, each with isolated disentanglement strategies. USO posits that these tasks are inherently complementary—learning to include features for one task informs the exclusion of those features for the other. This insight motivates a unified approach, leveraging cross-task co-disentanglement to mutually enhance both style and subject fidelity.
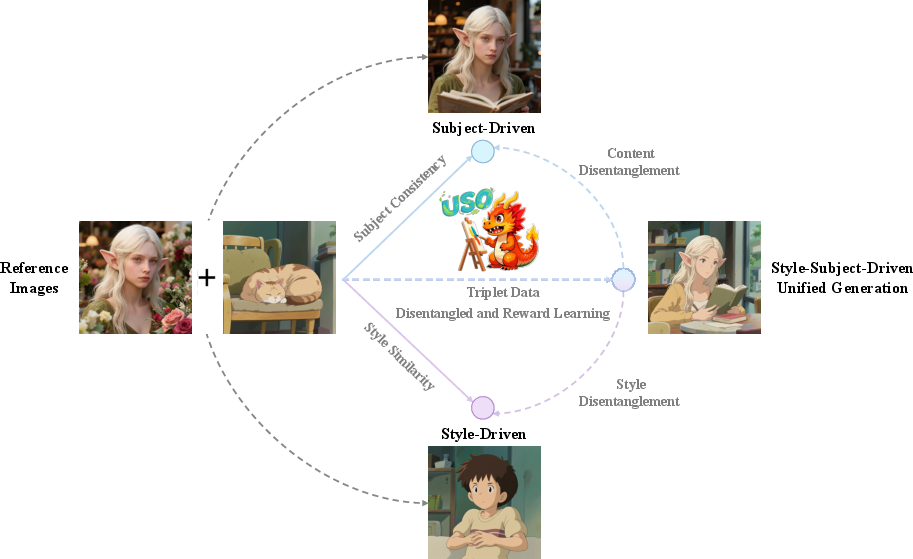
Figure 1: Joint disentanglement of content and style enables unification of style-driven and subject-driven generation within a single framework.
Cross-Task Triplet Curation Framework
USO introduces a systematic triplet curation pipeline, constructing datasets of the form ⟨style reference, de-stylized subject reference, stylized subject result⟩. This is achieved by training stylization and de-stylization experts atop a state-of-the-art subject-driven model, followed by filtering with VLM-based metrics to enforce style similarity and subject consistency. The resulting dataset contains both layout-preserved and layout-shifted triplets, enabling flexible recombination of subjects and styles.
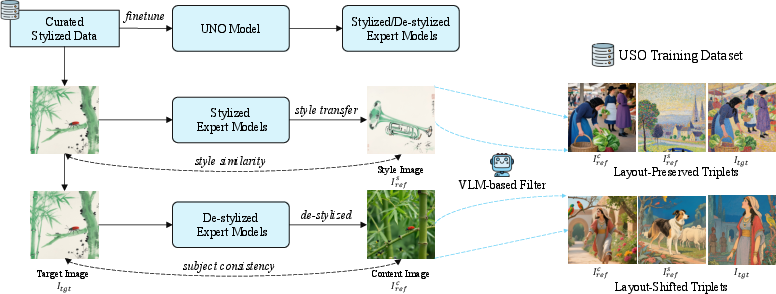
Figure 2: The cross-task triplet curation framework generates both layout-preserved and layout-shifted triplets for unified training.
Unified Customization Architecture
USO’s architecture is built on a DiT-based latent diffusion backbone, augmented with disentangled encoders for style and content. The training proceeds in two stages:
- Style Alignment Training: Style features are extracted using SigLIP embeddings, projected via a hierarchical projector, and aligned with the text token distribution. Only the projector is updated, ensuring rapid adaptation to style cues.
- Content-Style Disentanglement Training: Content images are encoded via a frozen VAE, and the DiT model is trained to disentangle content and style features explicitly. This design mitigates content leakage and enables precise control over feature inclusion/exclusion.
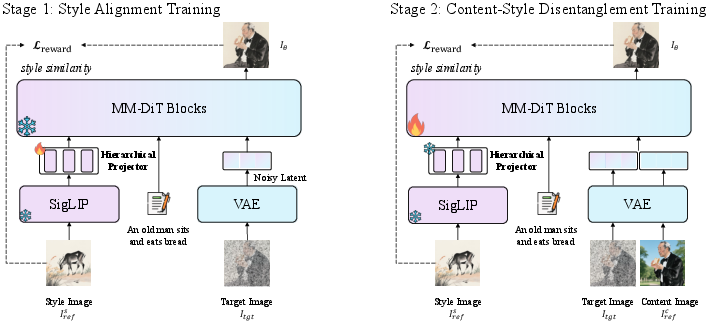
Figure 3: USO training framework: Stage 1 aligns style features; Stage 2 disentangles content and style; style-reward learning supervises both stages.
Style Reward Learning (SRL)
USO incorporates a style reward learning paradigm, extending flow-matching objectives with explicit style similarity rewards. The reward is computed using VLM-based or CSD metrics, and backpropagated to sharpen the model’s ability to extract and retain desired features. SRL is shown to improve both style fidelity and subject consistency, even in tasks not explicitly targeted during training.
Experimental Results
USO is evaluated on the newly introduced USO-Bench and DreamBench, covering subject-driven, style-driven, and joint style-subject-driven tasks. Quantitative metrics include CLIP-I, DINO, CSD, and CLIP-T, measuring subject consistency, style similarity, and text-image alignment.
- Subject-Driven Generation: USO achieves the highest DINO (0.793) and CLIP-I (0.623) scores, outperforming all baselines in subject fidelity and text controllability.
- Style-Driven Generation: USO attains the highest CSD (0.557) and competitive CLIP-T (0.282), demonstrating superior style transfer capabilities.
- Style-Subject-Driven Generation: USO leads with CSD (0.495) and CLIP-T (0.283), supporting arbitrary combinations of subjects and styles.

Figure 4: USO model demonstrates versatile abilities across subject-driven, style-driven, and joint style-subject-driven generation.

Figure 5: Qualitative comparison on subject-driven generation; USO maintains subject identity and applies style edits robustly.

Figure 6: Qualitative comparison on style-driven generation; USO preserves global and fine-grained stylistic features.

Figure 7: Qualitative comparison on identity-driven generation; USO achieves high identity consistency and realism.

Figure 8: Qualitative comparison on style-subject-driven generation; USO supports layout-preserved and layout-shifted scenarios.
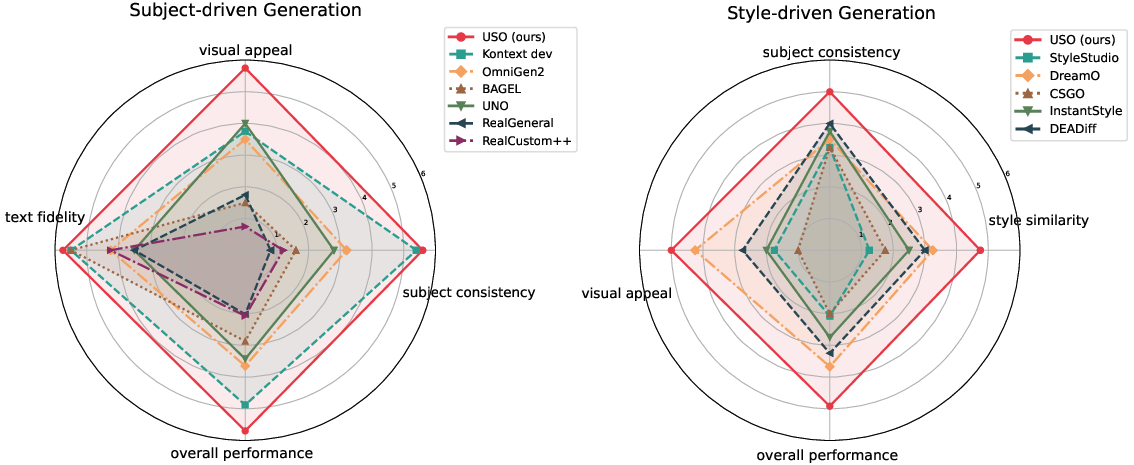
Figure 9: Radar charts from user evaluation show USO’s top performance in subject and style-driven tasks across multiple dimensions.
Ablation Studies
Ablation experiments confirm the necessity of each architectural component:
- SRL: Removing SRL sharply reduces CSD and CLIP-I, indicating its critical role in style and content disentanglement.
- Style Alignment Training: Omitting SAT degrades style fidelity and text alignment.
- Disentangled Encoders: Using a single encoder for both style and content harms all metrics, underscoring the importance of explicit disentanglement.
- Hierarchical Projector: This yields the highest style similarity scores, outperforming alternative projection strategies.

Figure 10: Ablation study of SRL; style reward learning enhances both style similarity and subject consistency.

Figure 11: Ablation study of USO; hierarchical projector and disentangled encoders are essential for optimal performance.
Implementation Details and Resource Requirements
USO is implemented atop FLUX.1 dev and SigLIP pretrained models. Training is staged: style alignment (23k steps, batch 16, 768px), followed by content-style disentanglement (21k steps, batch 64, 1024px). LoRA rank 128 is used for parameter-efficient adaptation. The model supports high-resolution generation and flexible conditioning, but requires substantial GPU resources for training and inference at scale.
Practical and Theoretical Implications
USO’s unified approach enables free-form recombination of subjects and styles, supporting both layout-preserving and layout-shifting scenarios. This has direct applications in creative industries, personalized content generation, and advanced customization pipelines. The cross-task co-disentanglement paradigm may inform future research in multi-conditional generative modeling, suggesting that joint training on complementary tasks can yield emergent capabilities and improved generalization.
Future Directions
Potential avenues for further research include:
- Extending USO to video generation and multi-modal synthesis.
- Investigating more granular disentanglement of additional attributes (e.g., lighting, pose).
- Scaling the triplet curation framework to larger, more diverse datasets.
- Integrating reinforcement learning from human feedback for finer control over subjective quality metrics.
Conclusion
USO establishes a unified framework for style-driven, subject-driven, and joint style-subject-driven image generation, leveraging cross-task co-disentanglement and style reward learning. Empirical results demonstrate state-of-the-art performance across all evaluated tasks, with robust subject consistency, style fidelity, and text controllability. The framework’s modular design and training strategies provide a blueprint for future advances in multi-conditional generative modeling.