- The paper introduces a comprehensive framework that integrates multiple search pipelines for robust gravitational-wave transient detection.
- It details the use of matched-filter and unmodeled burst searches coupled with low-latency systems to ensure rapid, accurate event validation.
- It employs Bayesian parameter estimation with uncertainty treatment to reliably characterize source properties for catalog construction.
GWTC-4.0: Methods for Identifying and Characterizing Gravitational-wave Transients
Introduction
The GWTC-4.0 methodology paper presents a comprehensive overview of the data analysis framework, algorithms, and validation strategies employed for the identification and characterization of gravitational-wave (GW) transients in the context of the LIGO, Virgo, and KAGRA collaborations. The work details the end-to-end pipeline, from raw strain data acquisition to the production of event catalogs, emphasizing both low-latency (online) and high-precision (offline) analyses. The paper addresses the integration of multiple search pipelines, parameter estimation techniques, and the systematic treatment of noise and data quality, establishing a robust foundation for the construction of the GW transient catalog.
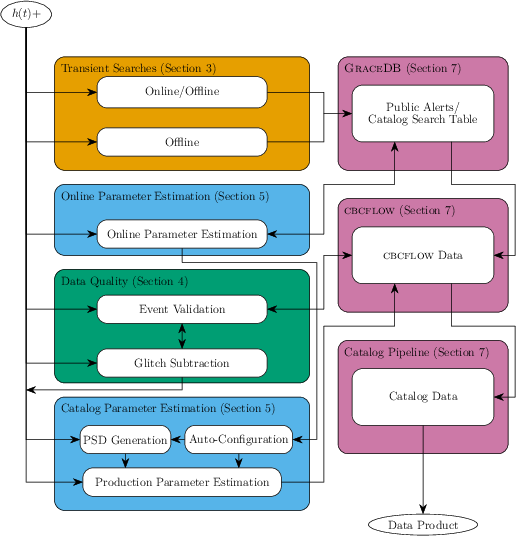
Figure 1: High-level rendering of the data flow from strain and auxiliary data to the production of GW transient results, illustrating the downstream and upstream dependencies and the distinction between online and offline analyses.
Data Acquisition and Conditioning
The initial stage involves the acquisition of calibrated strain data h(t) from the network of interferometers, supplemented by a suite of auxiliary channels for environmental and instrumental monitoring. The calibration process incorporates time-dependent response corrections and uncertainty quantification, ensuring that systematic errors are propagated through subsequent analyses. Data quality vetoes, informed by auxiliary channel correlations and machine learning classifiers, are applied to mitigate the impact of transient noise artifacts (glitches) and non-stationary backgrounds.
Search Pipelines for Transient GW Events
The detection of GW transients is performed using a heterogeneous ensemble of search pipelines, each optimized for specific source classes and signal morphologies:
- Matched-filter searches (e.g., PyCBC, GstLAL) target compact binary coalescences (CBCs) by correlating the data with template banks spanning the parameter space of binary black holes (BBH), binary neutron stars (BNS), and neutron star–black hole (NSBH) systems.
- Unmodeled burst searches (e.g., cWB, oLIB) are sensitive to generic transient signals, including those from core-collapse supernovae or other poorly modeled sources, by exploiting excess power and coherent network statistics.
- Low-latency pipelines are deployed for rapid identification and public alert generation, with automated candidate upload to GraceDB and subsequent human vetting.
The pipelines employ rigorous background estimation via time-slides and off-source analyses to compute false alarm rates (FAR) and assign statistical significance to candidate events.
Event Validation and Significance Assessment
Candidate events are subjected to a hierarchical validation process, including:
- Data quality checks: Cross-referencing with known instrumental artifacts and environmental disturbances.
- Signal consistency tests: Evaluation of waveform coherence across detectors and comparison with expected signal morphologies.
- Statistical significance: Assignment of inverse false alarm rates (IFAR) and false alarm probabilities (FAP), with thresholds set for catalog inclusion.
The methodology ensures that the catalog is robust against contamination from noise transients and that statistical uncertainties are rigorously quantified.
Parameter Estimation and Source Characterization
For each significant candidate, Bayesian parameter estimation (PE) is performed using stochastic samplers (e.g., LALInference, Bilby, RIFT) and waveform models incorporating general relativity, precession, and higher-order modes. The PE framework yields posterior distributions for intrinsic (masses, spins) and extrinsic (sky location, distance, inclination) parameters, as well as derived quantities such as source-frame masses and merger rates.
The analysis incorporates marginalization over calibration uncertainties and systematic waveform modeling errors. For high-significance events, additional tests of general relativity and population inference are conducted.
Catalog Production and Data Release
The final stage involves the compilation of validated events into the GWTC-4.0 catalog, with standardized metadata, posterior samples, and data products released via the Gravitational Wave Open Science Center (GWOSC). The catalog includes both online and offline events, with clear provenance and reproducibility guarantees.
The workflow is designed for scalability and parallelization, leveraging high-performance computing resources and workflow management systems to accommodate the increasing data volume and complexity of future observing runs.
Discussion and Implications
The GWTC-4.0 methodology establishes a rigorous, reproducible framework for GW transient discovery and characterization. The integration of multiple pipelines, robust background estimation, and comprehensive parameter inference ensures high catalog purity and completeness. The approach is extensible to future detector upgrades and network expansions, with modularity to incorporate new search algorithms and machine learning-based vetoes.
The systematic treatment of uncertainties and the transparent data release policy facilitate downstream astrophysical inference, including population studies, tests of fundamental physics, and multi-messenger follow-up. The methodology also provides a template for other large-scale time-domain astrophysics collaborations.
Conclusion
GWTC-4.0 represents a mature, scalable approach to the identification and characterization of gravitational-wave transients. The methodological rigor, combined with comprehensive data validation and parameter estimation, underpins the scientific reliability of the GW transient catalog and enables a broad range of astrophysical investigations. Future developments will likely focus on further automation, real-time parameter estimation, and the integration of next-generation detectors and analysis techniques.