- The paper introduces MeshSplat, which employs 2D Gaussian Splatting to bridge novel view synthesis and mesh extraction from sparse views.
- It leverages a feed-forward MVS architecture with multi-view transformers, U-Net refinement, and specialized losses such as the WCD loss and uncertainty-guided normal supervision to improve geometric accuracy.
- MeshSplat achieves state-of-the-art results on Re10K and Scannet by producing smoother, more complete meshes with efficient inference and robust cross-dataset generalization.
MeshSplat: Generalizable Sparse-View Surface Reconstruction via Gaussian Splatting
Introduction and Motivation
MeshSplat addresses the challenge of generalizable surface reconstruction from sparse multi-view images, a scenario where traditional per-scene optimization methods (e.g., NeRF, 3DGS) and even recent generalizable approaches often fail to recover accurate and complete scene geometry. The core innovation is the use of 2D Gaussian Splatting (2DGS) as an intermediate representation, bridging the gap between novel view synthesis (NVS) and mesh extraction. Unlike 3DGS, which suffers from inconsistent surface intersections across viewpoints, 2DGS provides consistent intersection planes, making it more suitable for surface reconstruction, especially under sparse-view constraints.
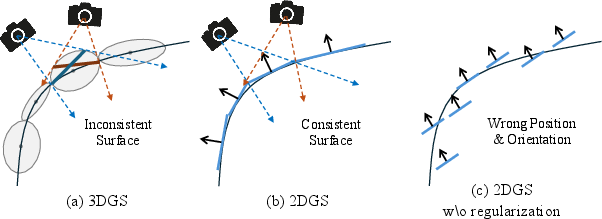
Figure 1: 2DGS provides consistent intersection planes across viewpoints, while 3DGS leads to inconsistent surfaces; unregularized 2DGS can still misalign with true surface contours.
Methodology
Architecture Overview
MeshSplat employs a feed-forward, multi-view stereo (MVS)-based architecture. Given a pair of images and their camera parameters, the pipeline consists of:
- Feature Extraction: A CNN and multi-view transformer extract per-view feature maps.
- Cost Volume Construction: Plane-sweeping generates per-view cost volumes, encoding multi-view correspondences.
- Depth and Normal Prediction: U-Net-based refinement yields depth maps; a dedicated normal prediction network estimates per-pixel normals and their uncertainties.
- 2DGS Parameterization: Pixel-aligned 2DGS are instantiated using predicted depths (for positions) and normals (for orientations), with other attributes decoded via a convolutional head.
- Supervision and Mesh Extraction: 2DGS are used for differentiable rendering (NVS supervision) and mesh extraction.
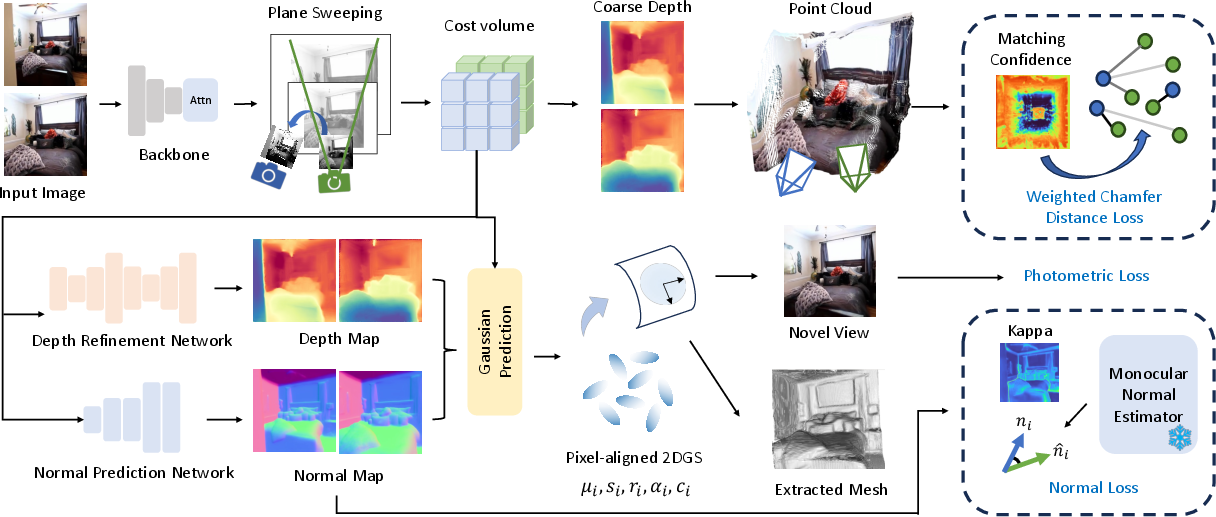
Figure 2: MeshSplat architecture: multi-view feature extraction, cost volume construction, depth/normal prediction, 2DGS parameterization, and mesh extraction.
Loss Functions
- Weighted Chamfer Distance (WCD) Loss: Regularizes 2DGS positions by aligning point clouds from different views, weighted by confidence maps derived from cost volumes. This focuses the loss on regions with reliable correspondences, mitigating the impact of occlusions and non-overlapping areas.
- Uncertainty-Guided Normal NLL Loss: Supervises normal predictions using pseudo ground-truth normals from a monocular estimator (Omnidata), with per-pixel uncertainty (kappa) modulating the loss. This targets reliable regions and improves orientation accuracy.
- Photometric Loss: Combines MSE and LPIPS between rendered and ground-truth images for NVS supervision.
Training and Inference
Training is performed end-to-end with the above losses. During inference, the network predicts 2DGS from sparse input views, which are then used for mesh extraction following the 2DGS pipeline.
Experimental Results
MeshSplat demonstrates superior performance on Re10K and Scannet datasets, outperforming MVSplat, PixelSplat, and NeRF-based baselines in Chamfer Distance, precision, recall, and F1 metrics. Notably, MeshSplat achieves a CD of 0.3566 and F1 of 0.3758 on Re10K, and CD of 0.2606 and F1 of 0.3824 on Scannet, with significant improvements in mesh completeness and surface smoothness.
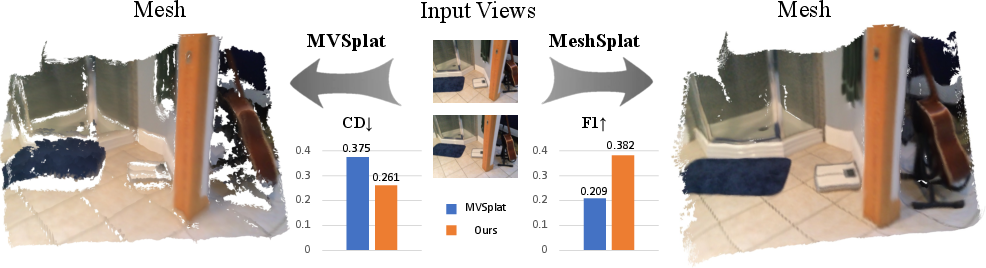
Figure 3: MeshSplat reconstructs smoother and more complete meshes from sparse views compared to MVSplat and other baselines.

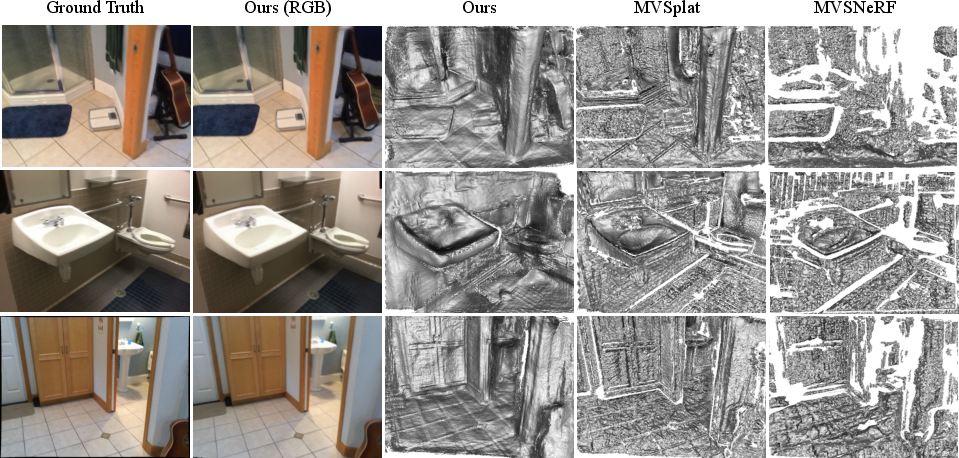
Figure 4: Qualitative comparison on Re10K: MeshSplat yields meshes with fewer holes and more regular surfaces.

Figure 5: Zero-shot transfer: MeshSplat generalizes to Scannet and Replica, maintaining mesh quality across datasets.
Depth and Normal Prediction
MeshSplat achieves lower depth error (AbsRel 0.0910 vs. 0.1692 for MVSplat) and improved normal estimation (mean error 33.84° vs. 57.16°), indicating more accurate geometry recovery.
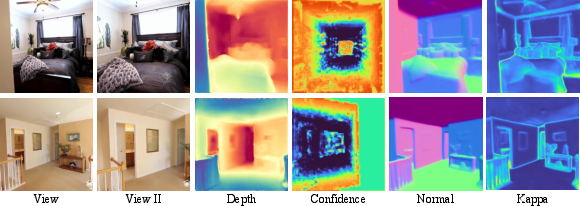
Figure 6: Visualization of predicted depth, normal, confidence, and kappa maps; confidence maps highlight unreliable regions, kappa maps reflect normal uncertainty.
Ablation Studies
Ablations confirm the necessity of each component:
Implementation Considerations
- Resource Requirements: MeshSplat is efficient, requiring only a single NVIDIA A800 GPU for training, and achieves fast inference (0.102s per forward pass, 13.3M parameters).
- Scalability: The feed-forward design enables application to large-scale datasets and real-world scenes without per-scene optimization.
- Limitations: MeshSplat struggles in textureless or occluded regions, sometimes producing discontinuous depth maps. It cannot reconstruct surfaces not visible in the input views, a limitation inherent to all non-generative, view-based methods.
Practical and Theoretical Implications
MeshSplat demonstrates that 2DGS, when properly regularized and supervised, can serve as an effective bridge between NVS and surface reconstruction, enabling generalizable, feed-forward mesh extraction from sparse views. The WCD loss and uncertainty-guided normal supervision are critical for robust geometry prediction under limited multi-view constraints. The approach is extensible to other tasks requiring generalizable geometric priors, such as SLAM, AR/VR content creation, and robotics.
Future Directions
Potential avenues for further research include:
- Integrating generative priors to hallucinate geometry in unobserved regions.
- Extending the framework to handle dynamic scenes or outdoor environments.
- Improving robustness in textureless or ambiguous regions via multi-modal or semantic cues.
- Exploring more efficient architectures for real-time applications.
Conclusion
MeshSplat establishes a new state-of-the-art for generalizable sparse-view surface reconstruction by leveraging 2DGS, WCD loss, and uncertainty-guided normal supervision. The method achieves strong quantitative and qualitative results, robust cross-dataset generalization, and efficient inference, making it a practical solution for real-world 3D reconstruction from limited imagery.
