- The paper introduces integrated human-specific semantic heads that enable explicit modeling of articulated human bodies within multi-view stereo reconstruction.
- It extends a Siamese ViT encoder with dual cross-attention decoders, achieving competitive performance on benchmarks like EgoHumans and EgoExo4D.
- The approach significantly improves runtime and scalability, with notable results such as a 0.51m W-MPJPE on EgoExo4D, outperforming optimization-based pipelines.
HAMSt3R: Human-Aware Multi-view Stereo 3D Reconstruction
Introduction
HAMSt3R addresses the challenge of reconstructing both human subjects and their surrounding environments from sparse, uncalibrated multi-view images. While prior learning-based methods such as DUSt3R and MASt3R have demonstrated strong performance in general scene reconstruction, they are limited in human-centric scenarios due to a lack of explicit modeling of articulated, deformable human bodies. HAMSt3R extends the MASt3R architecture by integrating human-specific semantic heads and leveraging a distilled image encoder, enabling efficient, feed-forward, and joint 3D reconstruction of humans and scenes. The method is evaluated on challenging benchmarks (EgoHumans, EgoExo4D) and demonstrates competitive or superior performance compared to optimization-based pipelines, with significant improvements in runtime and scalability.
Methodology
HAMSt3R builds upon the MASt3R pipeline, introducing several architectural and training innovations to enable human-aware 3D reconstruction.
Model Architecture
The core architecture consists of a Siamese ViT encoder, dual cross-attention decoders, and multiple prediction heads. The encoder is a distilled ViT-B/14 backbone (from DUNE), fusing representations from generalist and human-centric teacher models. This enables robust feature extraction for both scene and human content.
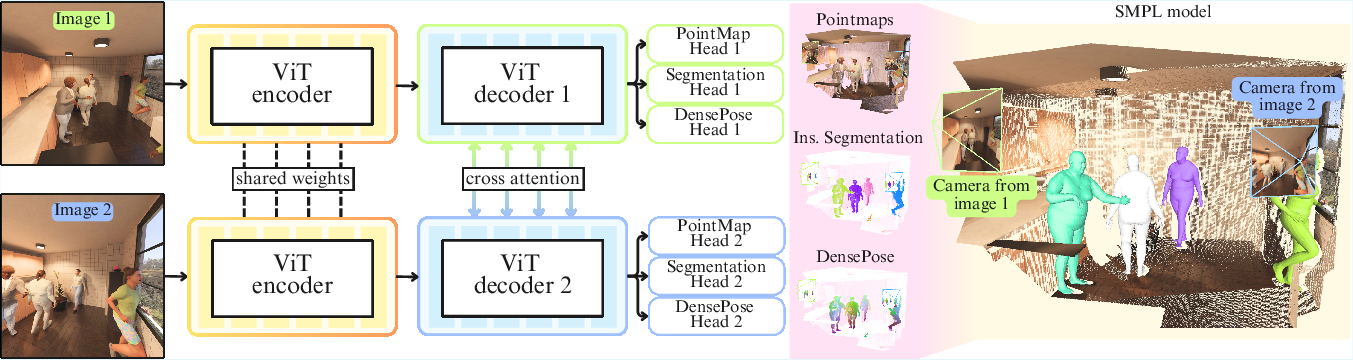
Figure 1: Overview of HAMSt3R. Stereo images are processed by a Siamese ViT encoder, followed by dual decoders with cross-attention. Separate heads generate 3D pointmaps and dense human semantic information (instance segmentation, DensePose, binary masks), which can be lifted to 3D and used for SMPL body model fitting.
The prediction heads include:
- 3D Pointmap Head: Regresses dense 3D coordinates for each pixel, as in MASt3R.
- Instance Segmentation Head: Transformer-based, inspired by Mask2Former, segments human instances from the background.
- DensePose Head: Predicts continuous DensePose maps, mapping image pixels to the SMPL body surface, along with a binary mask for valid regions.
The outputs are aggregated to produce a dense 3D point cloud with per-point human semantic labels, enabling downstream tasks such as SMPL mesh fitting.
Multi-view Aggregation
For N input images, HAMSt3R processes all possible pairs, generating pointmaps and semantic predictions per pair. Global alignment (as in MASt3R) is used to register all pointmaps in a common 3D frame. Instance IDs are resolved via 2D mask overlap, and DensePose predictions are aggregated using confidence-weighted averaging.

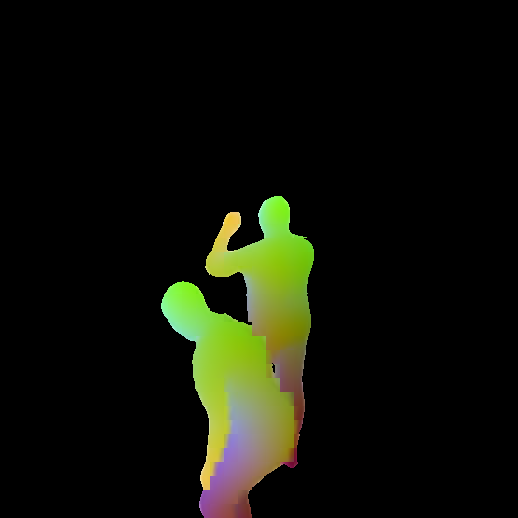







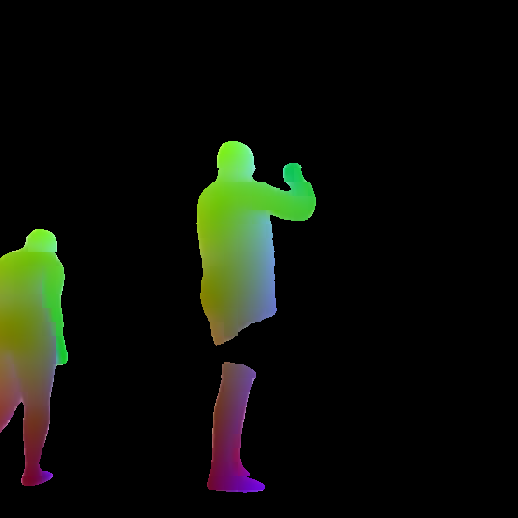

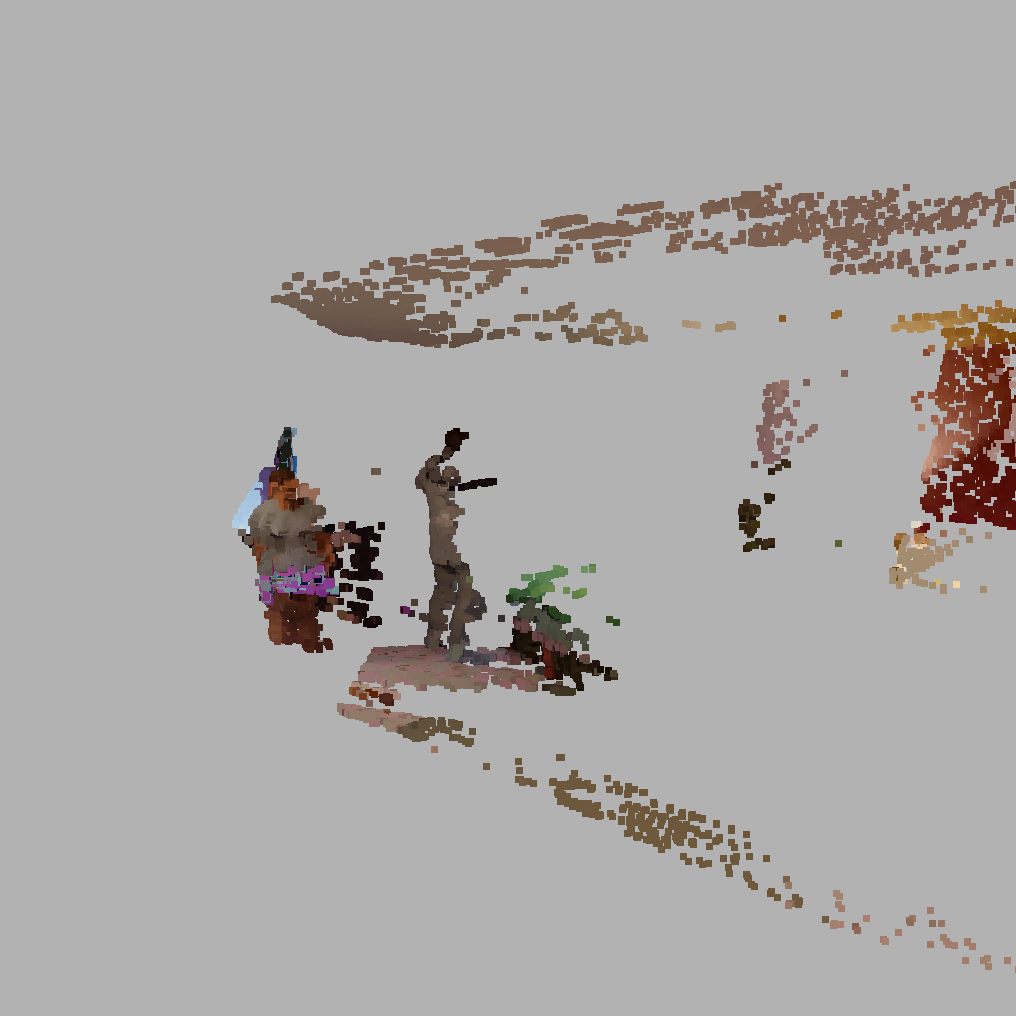

Figure 2: Aggregation of predictions from multiple image pairs on HumGen3D data. Human semantic outputs are aligned and fused into a unified 3D reconstruction.
Training Strategy
The encoder is frozen; only decoders and heads are fine-tuned. The loss is a weighted sum of MASt3R's pointmap/matching loss, segmentation loss, DensePose regression loss, and binary mask loss. Training data is a 50/50 mix of the original MASt3R dataset and synthetic/real human-centric datasets (HumGen3D, BEDLAM, HuMMan, EgoBody), ensuring both scene and human reconstruction capabilities.

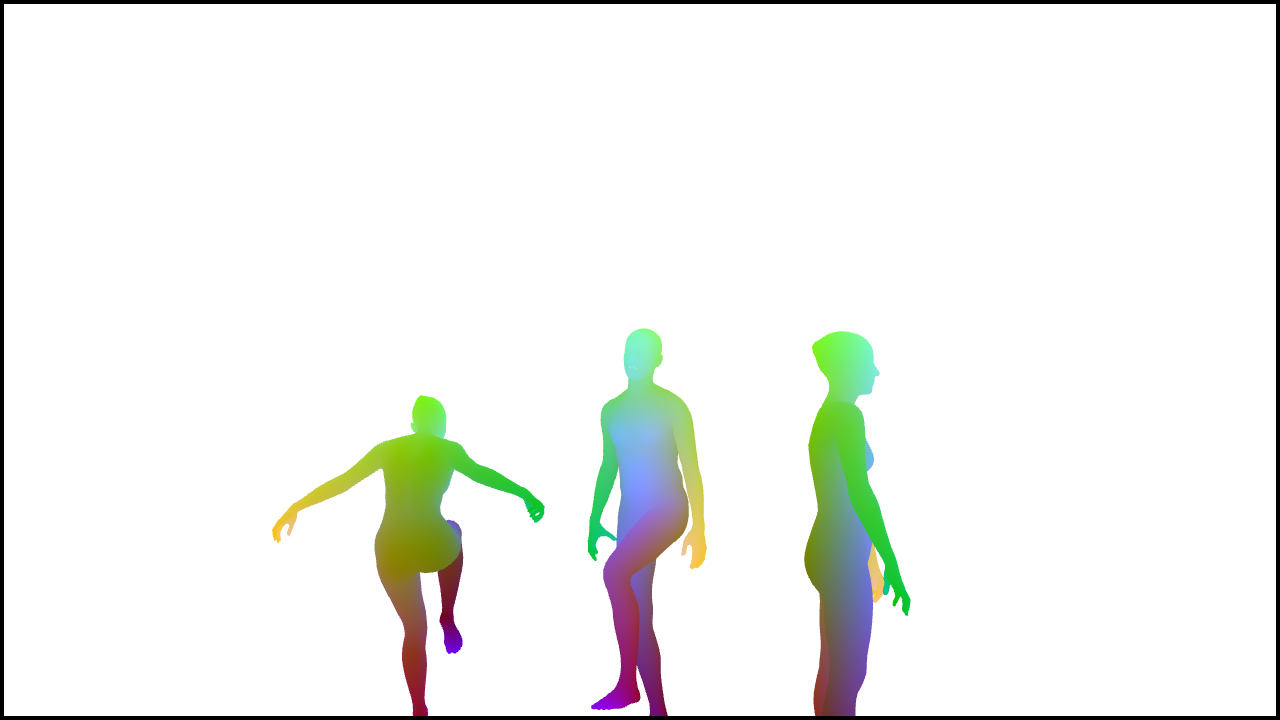

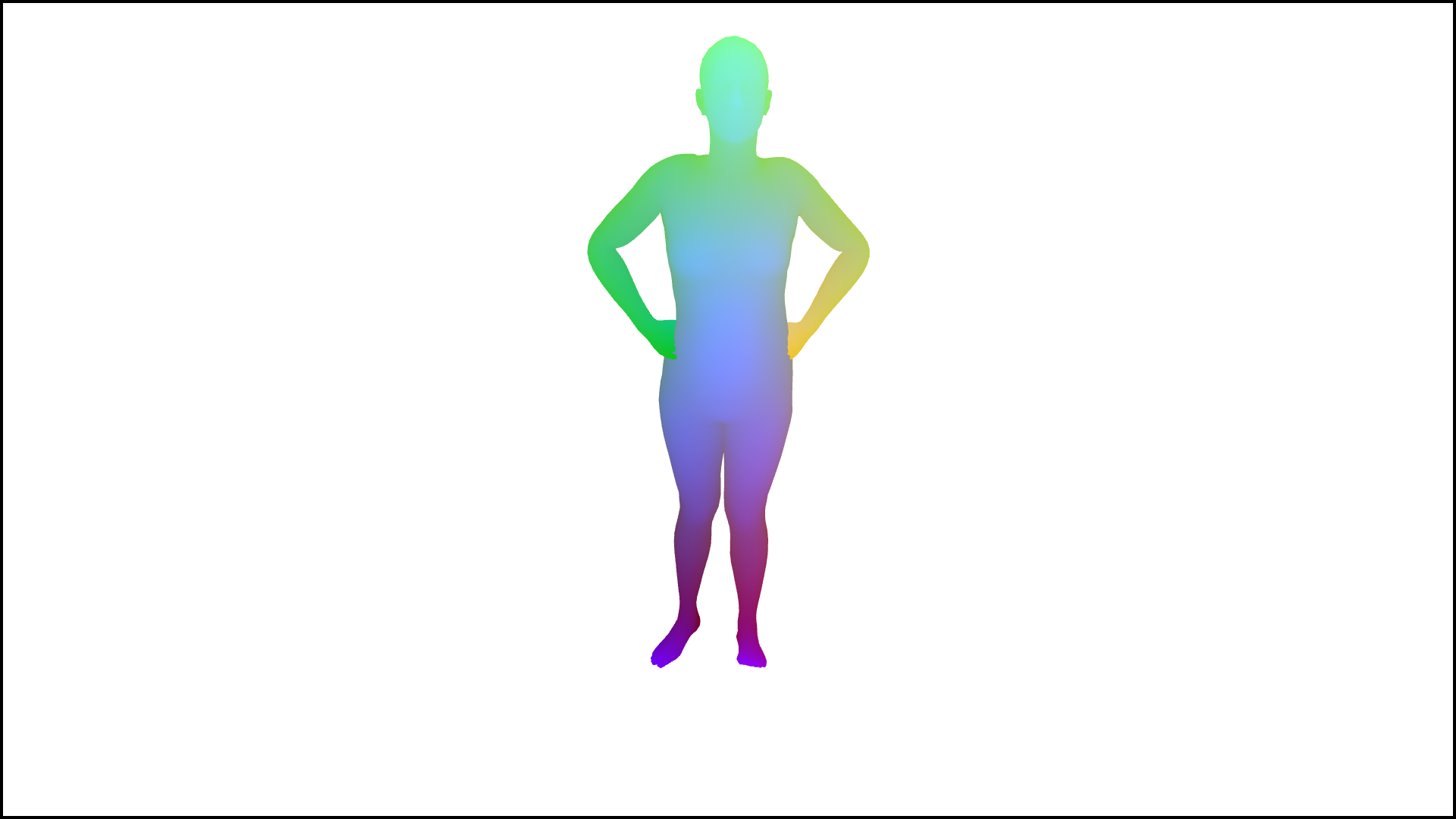


Figure 3: Examples from the human-centric datasets used for training, showing input images and corresponding DensePose annotations.
Experimental Results
Human-centric 3D Reconstruction
HAMSt3R is evaluated on EgoHumans and EgoExo4D, using metrics such as W-MPJPE, GA-MPJPE, and PA-MPJPE for human pose estimation. SMPL fitting is performed as a post-processing step, using the predicted 3D points and DensePose outputs.
- On EgoExo4D, HAMSt3R achieves the lowest W-MPJPE (0.51m), outperforming HSfM (0.56m) and UnCaliPose (2.90m).
- On EgoHumans, HAMSt3R outperforms UnCaliPose and is competitive with HSfM, though slightly worse in PA-MPJPE due to the lack of RGB cues in SMPL fitting.
Qualitative results demonstrate robust reconstruction of human shapes, poses, and spatial arrangements in diverse scenes.

Figure 4: Qualitative results on EgoExo4D and EgoHumans. Point clouds, instance segmentation, and DensePose outputs are visualized alongside input images.
General 3D Scene Reconstruction
HAMSt3R is also evaluated on standard multi-view stereo benchmarks (KITTI, ScanNet, ETH3D, DTU, Tanks and Temples) and multi-view pose regression (CO3Dv2, RealEstate10K). While there is a moderate drop in depth estimation accuracy compared to MASt3R and DUSt3R (due to the human-centric encoder and training), HAMSt3R remains competitive with other deep learning baselines (e.g., DeepV2D).
Runtime and Efficiency
HAMSt3R is fully feed-forward and significantly faster than optimization-based pipelines such as HSfM. For a 4-view, 3-person scene, HAMSt3R completes reconstruction and semantic prediction in ~14s (plus ~6s for SMPL fitting), compared to ~118s for HSfM.
Monocular and Failure Case Analysis
HAMSt3R can be applied to monocular images by duplicating the input, producing plausible 3D reconstructions and mesh fits. Failure cases are observed in low-resolution or extreme pose scenarios, where point clouds become sparse or noisy, leading to unstable SMPL fitting.

Figure 5: Monocular prediction results on in-the-wild images, showing pointmaps, segmentation, DensePose, and SMPL fits.

Figure 6: Failure cases due to small human scale or extreme poses, resulting in noisy point clouds and erroneous SMPL fits.
Implications and Future Directions
HAMSt3R demonstrates that feed-forward, transformer-based architectures can jointly reconstruct articulated humans and general scenes from sparse, uncalibrated images, with efficiency and scalability suitable for real-world applications. The integration of human semantic heads and a distilled encoder enables strong performance in both human-centric and general 3D tasks, though with some trade-off in depth accuracy for large-scale scenes.
The approach suggests several avenues for future research:
- Extending to dynamic scenes and video, leveraging temporal consistency.
- Improving robustness in low-resolution and occluded scenarios, possibly via higher-resolution processing or additional priors.
- Integrating richer appearance cues for downstream mesh fitting.
- Exploring end-to-end differentiable SMPL fitting within the reconstruction pipeline.
Conclusion
HAMSt3R advances the state of the art in joint human and scene 3D reconstruction from sparse, uncalibrated images. By unifying scene geometry, human segmentation, and DensePose estimation in a single, efficient architecture, it bridges the gap between general 3D vision and articulated human modeling. The method achieves strong quantitative and qualitative results on challenging benchmarks, with significant improvements in runtime and scalability over optimization-based approaches. Future work will focus on dynamic scenes and further improving robustness in challenging conditions.