- The paper introduces MCP-Universe, a benchmark that evaluates LLM agents on 231 realistic tasks across six diverse domains using authentic MCP servers.
- It employs modular, execution-based evaluators—format, static, and dynamic—to ensure objective, reproducible assessments of tool interactions.
- Experimental results reveal significant performance gaps, highlighting challenges in long context management and the adaptation to unfamiliar tools.
MCP-Universe: Rigorous Benchmarking of LLM Agents in Real-World MCP Environments
Introduction and Motivation
The Model Context Protocol (MCP) has rapidly become a de facto standard for connecting LLMs to external data sources and tools, offering a unified interface for agentic AI systems. Despite widespread adoption, existing benchmarks for MCP-enabled agents are insufficient, typically relying on synthetic tasks, static datasets, or GUI-based simulations that fail to capture the operational complexity of real-world deployments. MCP-Universe directly addresses these deficiencies by introducing a comprehensive benchmark grounded in authentic MCP servers, spanning six core domains and 11 servers, and evaluating agents on 231 tasks that reflect genuine application scenarios.
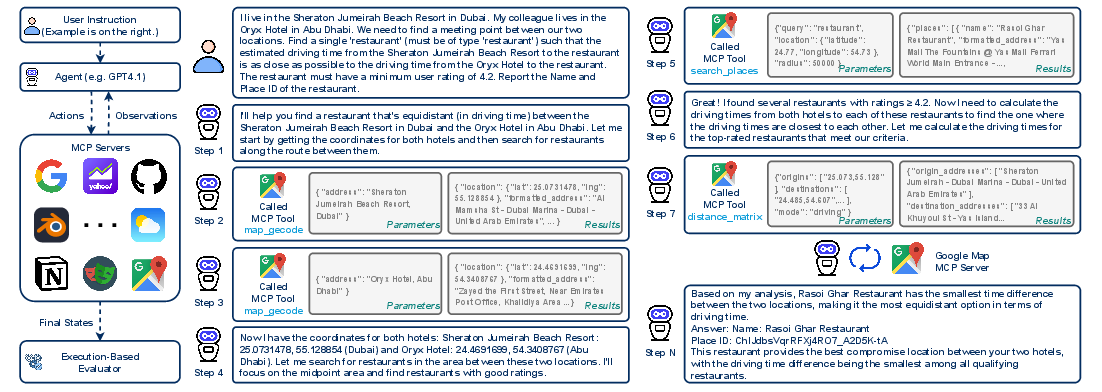
Figure 1: MCP-Universe presents realistic challenges, including real-world tool usage, long-horizon multi-turn tool calls, long context windows, scattered evidence, and large tool spaces, all grounded in actual MCP servers and environments.
Benchmark Design and Evaluation Framework
MCP-Universe formalizes the agent evaluation setting as a tuple (G,C,Tavailable), where G is the goal, C is the initial context, and Tavailable is the set of accessible tools from selected MCP servers. Agents must reason over partial information, adapt to diverse tool interfaces, and handle ambiguous or failed tool responses. The evaluation framework is modular and extensible, supporting dynamic configuration of LLM-agent pairs, MCP server selection, and execution-based evaluators.
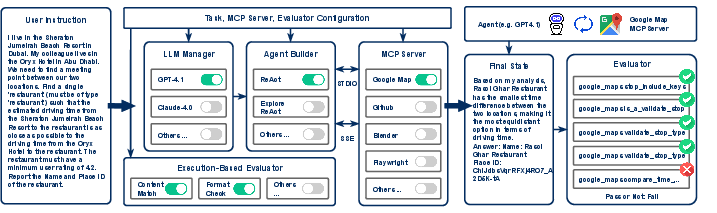
Figure 2: The MCP-Universe evaluation framework dynamically configures agents, servers, and evaluators, mediating agent-server interactions via the MCP protocol and conducting objective, automated assessments of task completion.
Execution-based evaluation is central to MCP-Universe, eschewing LLM-as-a-judge paradigms due to their susceptibility to style bias and inability to handle temporally sensitive tasks. Instead, the framework employs three evaluator types:
- Format Evaluators: Enforce strict output format compliance.
- Static Evaluators: Validate correctness for time-invariant tasks.
- Dynamic Evaluators: Retrieve real-time ground truth for temporally sensitive tasks.
This approach ensures reproducibility and fairness, particularly for tasks involving live data or complex tool interactions.
Domain Coverage and Task Diversity
MCP-Universe covers six domains: Location Navigation, Repository Management, Financial Analysis, 3D Design, Browser Automation, and Web Searching. Each domain is represented by authentic MCP servers (e.g., Google Maps, GitHub, Yahoo Finance, Blender, Playwright, Google Search), with tasks designed to stress agentic capabilities in realistic scenarios.
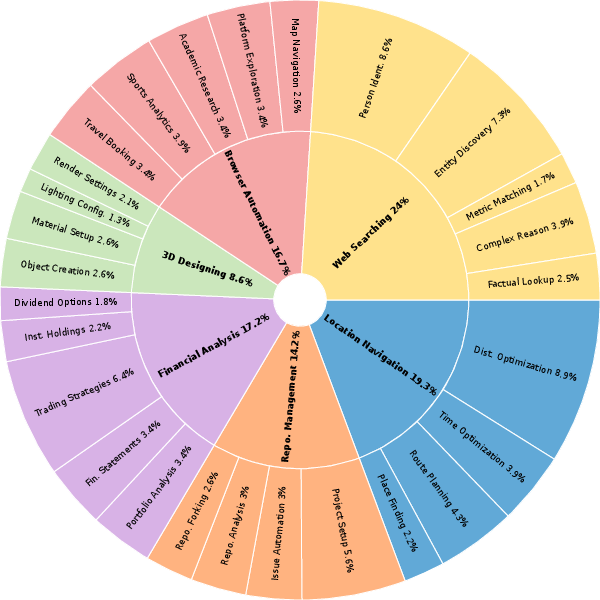
Figure 3: Distribution of MCP-Universe tasks across application domains, illustrating broad coverage and diversity.
Tasks are manually curated to avoid triviality and ensure that completion requires substantive tool use and reasoning. For example, navigation tasks require multi-step route planning with constraints, repository management tasks involve branching and automation, and financial analysis tasks demand real-time data retrieval and quantitative reasoning.
Experimental Results and Analysis
Extensive experiments reveal that even frontier models such as GPT-5, Grok-4, and Claude-4.0-Sonnet exhibit substantial limitations in MCP-driven environments. GPT-5 achieves the highest overall success rate (43.72%), with Grok-4 (33.33%) and Claude-4.0-Sonnet (29.44%) trailing. Notably, performance is highly domain-dependent: GPT-5 excels in Financial Analysis (67.50%) and 3D Design (52.63%), while all models perform poorly in Location Navigation and Repository Management (success rates <35%).
Open-source models lag behind proprietary counterparts, with GLM-4.5 leading at 24.68%. The gap between proprietary and open-source models remains pronounced, indicating that current open-source LLMs are not yet competitive in complex, real-world MCP scenarios.
Evaluator Breakdown
Models generally achieve high success rates on format evaluators (>80%), but performance drops sharply on static and dynamic evaluators (40–65%), indicating that failures are primarily due to content generation rather than format compliance. For instance, Claude-4.0-Sonnet achieves 98.29% on format evaluators but only 61.92% on static and 54.74% on dynamic evaluators.
Long Context and Unknown Tools Challenges
MCP-Universe exposes two critical challenges for LLM agents:
- Long Context: Many tasks require agents to process extensive context windows, often exceeding model limits and leading to degraded performance. The number of tokens grows rapidly with interaction steps, especially in domains like Browser Automation and Financial Analysis.
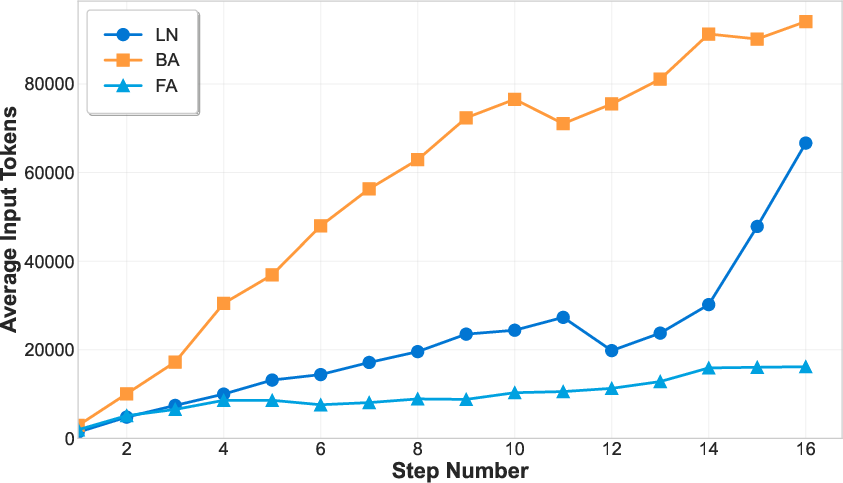
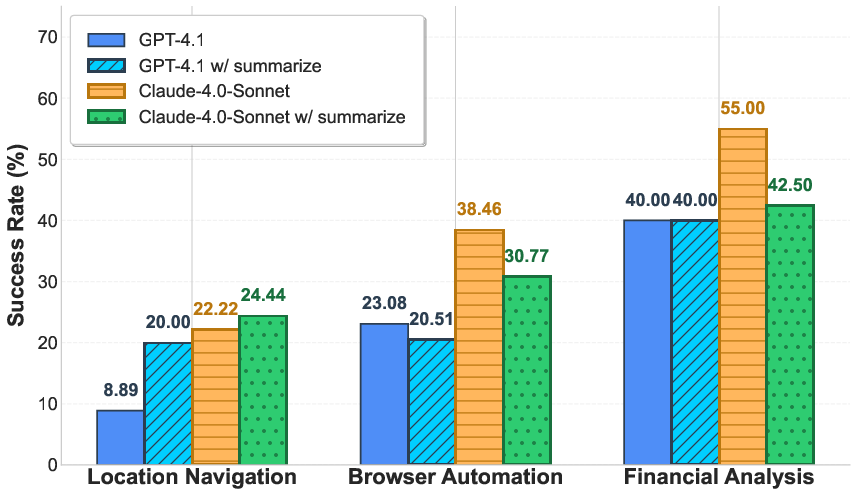
Figure 4: (Left) Context length increases with interaction steps, illustrating the long context challenge. (Right) Introducing a summarization agent yields mixed results across domains.
Attempts to mitigate this via summarization agents yield inconsistent improvements, suggesting that naive compression strategies are insufficient for preserving essential information in long-horizon tasks.
- Unknown Tools: Agents frequently fail due to unfamiliarity with tool interfaces and constraints. For example, incorrect parameterization in the Yahoo Finance MCP server leads to execution errors.

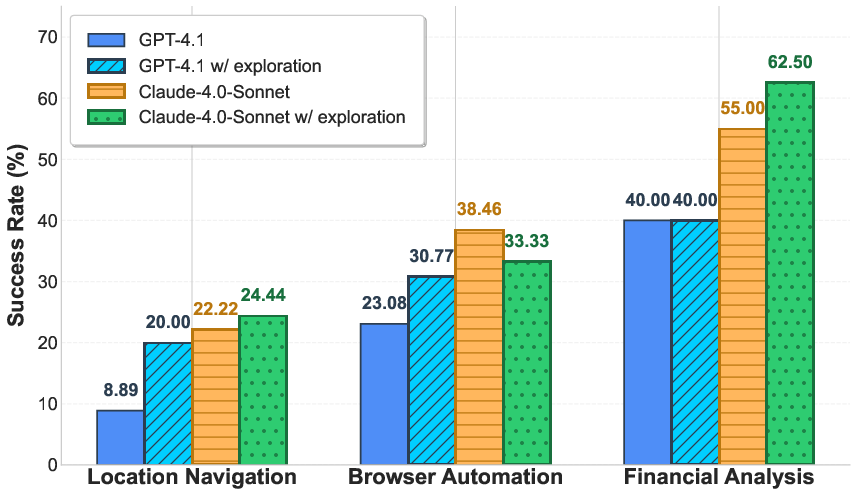
Figure 5: (Left) Example of unknown tool challenge. (Right) Exploration phase improves performance in some domains but is not universally effective.
Introducing an exploration phase, where agents interact with tools before task execution, improves performance in select domains but does not generalize across all scenarios. This highlights the need for more robust tool learning and adaptation strategies.
Connecting agents to additional, unrelated MCP servers increases tool space complexity and introduces noise, resulting in further performance degradation. This demonstrates MCP-Universe's utility for evaluating agent robustness under large, heterogeneous tool sets.
Agent Framework Comparison
Enterprise-level agent frameworks (e.g., Cursor Agent) do not consistently outperform standard approaches like ReAct. For example, Cursor Agent underperforms in Web Searching compared to ReAct, despite excelling in Browser Automation. The OpenAI Agent SDK paired with o3 achieves the highest overall performance among tested agent-backbone combinations, underscoring the importance of optimal agent-model pairing.
Implementation Considerations
MCP-Universe is open-sourced with UI support, facilitating integration of new agents and MCP servers. The framework is designed for extensibility, reproducibility, and objective assessment, making it suitable for both academic research and industrial deployment. Resource requirements are non-trivial due to the need for real-time data retrieval and execution-based evaluation, but the modular architecture allows for scalable experimentation.
Implications and Future Directions
MCP-Universe reveals fundamental limitations in current LLM agentic capabilities, particularly in handling long contexts, unfamiliar tools, and large tool spaces. The benchmark sets a high bar for agent robustness, adaptability, and real-world applicability. Future research should focus on:
- Advanced context management strategies (e.g., hierarchical memory, selective attention).
- Automated tool learning and interface adaptation.
- Domain-specific optimization and transfer learning.
- Scalable evaluation frameworks for heterogeneous, dynamic environments.
The benchmark's extensibility and rigorous evaluation paradigm position it as a critical resource for driving progress in agentic AI, tool-augmented LLMs, and real-world automation.
Conclusion
MCP-Universe establishes a rigorous, comprehensive benchmark for evaluating LLM agents in authentic MCP environments. By exposing critical gaps in current model and agent architectures, it provides a robust testbed for advancing agentic AI research and deployment. The findings underscore the necessity of targeted improvements in context handling, tool adaptation, and agent framework design to achieve reliable, scalable performance in real-world applications.

