- The paper establishes GPT-5 as state-of-the-art on spatial benchmarks by excelling in metric measurement and spatial relations.
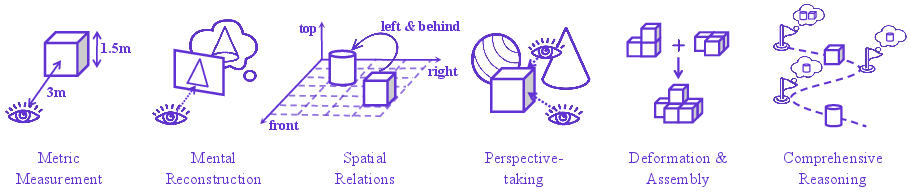
- It employs a standardized taxonomy of six core spatial intelligence capabilities to compare performance across eight diverse benchmarks.
- GPT-5 achieves near human-level metrics in some tasks but struggles with complex spatial reasoning such as mental reconstruction and perspective-taking.
Empirical Assessment of GPT-5's Spatial Intelligence
Introduction
Spatial intelligence (SI) encompasses the ability to understand, reason, and manipulate spatial relationships and structures, a core component of embodied cognition and a prerequisite for artificial general intelligence (AGI). Despite rapid progress in multi-modal LLMs (MLLMs), spatial reasoning remains a persistent challenge. This paper presents a comprehensive empirical evaluation of GPT-5 and other state-of-the-art MLLMs on spatial intelligence, unifying recent benchmarks under a taxonomy of six fundamental SI capabilities and standardizing evaluation protocols for fair cross-model comparison.
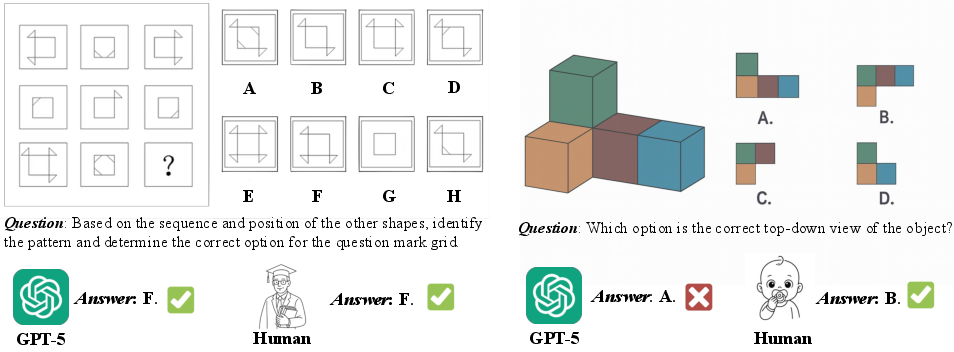
Figure 1: GPT-5 excels at complex reasoning tasks but continues to struggle with basic spatial intelligence problems that are trivial for humans.
Taxonomy and Benchmarks for Spatial Intelligence
The authors consolidate spatial intelligence evaluation into six core capabilities:
Eight recently released benchmarks are used for evaluation: VSI-Bench, SITE, MMSI, OmniSpatial, MindCube, STARE, CoreCognition, and SpatialViz. Each benchmark targets different SI subskills and varies in data modality, annotation method, and evaluation metric. The authors standardize system prompts (zero-shot CoT), answer extraction, and scoring (Chance-Adjusted Accuracy for MCQ, Mean Relative Accuracy for numerical answers) to ensure comparability.
Experimental Results
GPT-5 establishes a new state of the art in spatial intelligence across all benchmarks, outperforming both proprietary and open-source models by significant margins. On MM and SR tasks, GPT-5 approaches or matches human-level performance, indicating robust geometric priors and effective spatial relation reasoning. However, substantial gaps remain in MR, PT, DA, and CR, with performance far below human baselines.
Key findings:
- GPT-5 achieves top scores on most SI benchmarks, especially in MM and SR.
- Human-level performance is reached only in select subcategories; overall, humans outperform all models by wide margins in MR, PT, DA, and CR.
- SI tasks are consistently more challenging than non-SI tasks, with larger model-human gaps.
- Proprietary models do not decisively outperform open-source models on the hardest SI tasks, suggesting open-source models are competitive in this domain.
Ablation Studies
The authors analyze the impact of GPT-5's "thinking mode" (effort parameter) and circular evaluation strategies:
- Reasoning depth improves accuracy up to a point, but excessive reasoning leads to timeouts and diminishing returns.
- Medium effort mode offers the best trade-off between accuracy and computational cost.
- Circular evaluation protocols (soft/hard) reveal that non-circular accuracy may be inflated by random guessing, and hard-circular scoring is a stricter measure of true competence.
Qualitative Case Studies
Detailed case studies highlight GPT-5's strengths and limitations:
- MM tasks: Reliable estimation of object sizes and distances, leveraging learned priors.
- MR tasks: Capable of novel view generation and partial 3D reconstruction, but highly sensitive to prompt phrasing and still fails on tasks trivial for humans.
- SR tasks: Handles simple spatial relations but struggles with perspective effects and visual illusions.
- PT tasks: Fails to robustly reason across viewpoint changes, especially with minimal view overlap.
- DA tasks: Poor performance on mental folding, assembly, and structural transformation.
- CR tasks: Inadequate multi-stage reasoning, especially in occlusion and navigation scenarios.
Implementation and Evaluation Protocols
The evaluation pipeline is meticulously standardized:
- System prompts: Zero-shot chain-of-thought, with answer templates for extraction.
- Answer matching: Three-step process (rule-based, extended rule-based, LLM-assisted).
- Metrics: Chance-Adjusted Accuracy for MCQ, Mean Relative Accuracy for numerical answers.
- Circular evaluation: Option rotation to mitigate position bias.
- Resource requirements: Over one billion tokens processed, with significant computational cost for high-effort reasoning modes.
Implications and Future Directions
The empirical results demonstrate that, while GPT-5 represents a substantial advance in spatial intelligence, it has not achieved parity with human cognition in this domain. The persistent deficits in MR, PT, DA, and CR suggest that current MLLMs lack fundamental spatial reasoning mechanisms, such as robust 3D mental modeling, viewpoint transformation, and structural manipulation. The parity between proprietary and open-source models on the hardest SI tasks indicates that further progress may be driven by architectural innovations and training strategies rather than scale alone.
Practical implications:
- Embodied AI and robotics: Current MLLMs are not yet suitable for tasks requiring advanced spatial reasoning, such as manipulation, navigation, or assembly.
- Benchmarking and evaluation: The standardized taxonomy and protocols provide a foundation for future SI research and model comparison.
- Open-source opportunities: The lack of proprietary advantage on difficult SI tasks opens the field for community-driven advances.
Theoretical implications:
- Spatial intelligence is a distinct and underexplored frontier in AGI research.
- Progress in SI will require new approaches beyond scaling and data augmentation, potentially involving explicit geometric reasoning modules, 3D-aware representations, or hybrid neuro-symbolic architectures.
Conclusion
This study provides a rigorous empirical assessment of GPT-5's spatial intelligence, revealing both its strengths and persistent limitations. While GPT-5 sets a new benchmark in SI, it remains far from human-level performance in key areas. The unified taxonomy, standardized evaluation, and detailed analysis presented here establish a foundation for future research, highlighting the need for novel methods to bridge the gap in spatial reasoning and advance toward embodied AGI.