- The paper introduces Mockingbird, a framework that uses dynamic role-playing by LLMs to integrate into ML pipelines and execute tasks at runtime.
- The framework employs reflection and tailored memory management to continuously improve accuracy and optimize context usage.
- Evaluations on standard ML tasks demonstrate competitive performance across various LLM sizes, highlighting trade-offs in speed, cost, and correctness.
Mockingbird: A Framework for Adapting LLMs to General Machine Learning Tasks
Introduction
The paper introduces Mockingbird, a framework designed to adapt LLMs to general ML tasks by leveraging their in-context learning, reasoning, and intrinsic knowledge. Unlike conventional approaches that use LLMs as static code generators for ML pipelines, Mockingbird enables LLMs to dynamically "role-play" arbitrary functions at runtime, integrating them as active components in intelligent systems. The framework is evaluated on a range of standard ML tasks, with a focus on both performance and practical deployment considerations.
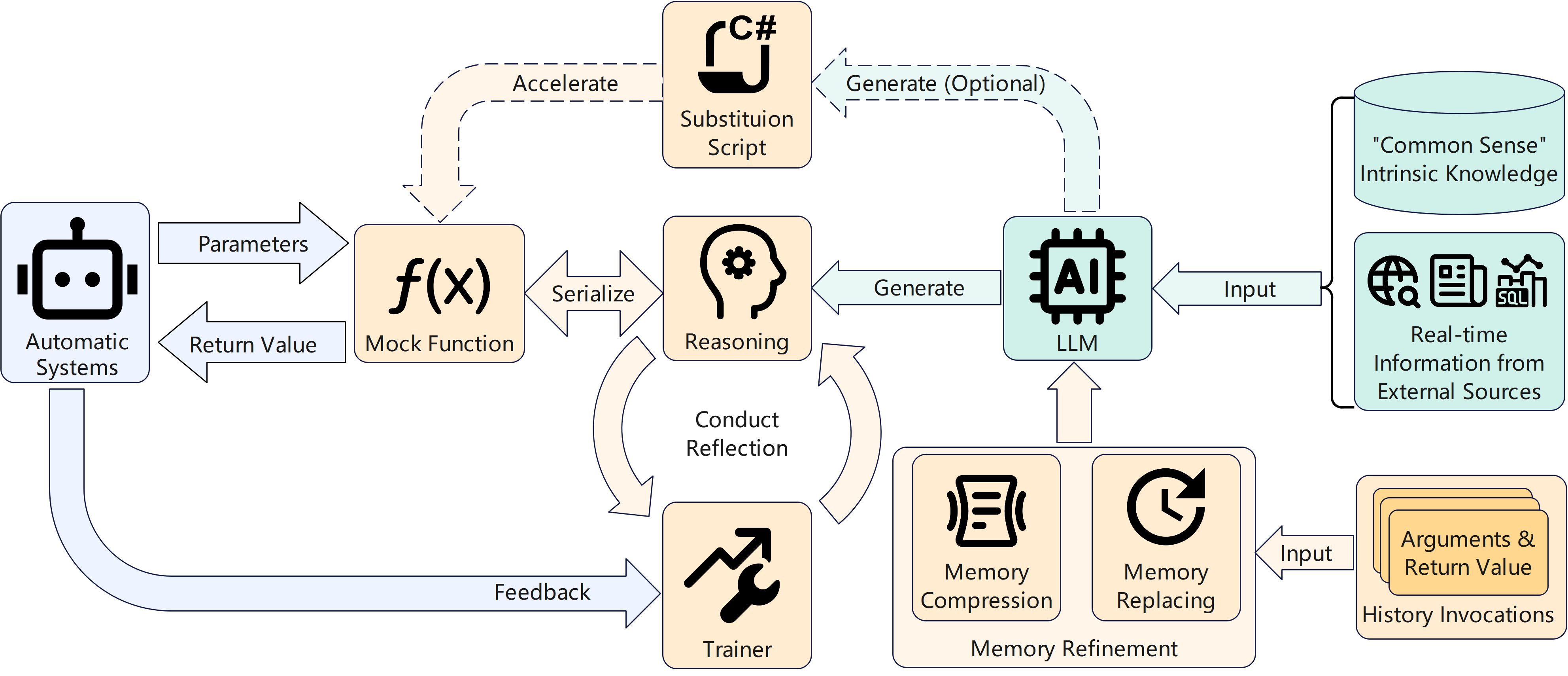
Figure 1: High-level overview of Mockingbird, illustrating the redirection of function calls to the LLM, the reflection process, and optional modules for substitution scripts and memory management.
Framework Architecture
Mock Functions and System Integration
At the core of Mockingbird are mock functions—function declarations without bodies, defined by their signatures and documentation. These are not implemented via code generation at compile time; instead, the LLM is prompted at runtime to "role-play" the function, using metadata such as method signatures and documentation to inform its behavior. This design allows seamless integration into existing codebases, as mock functions can be invoked like ordinary functions.
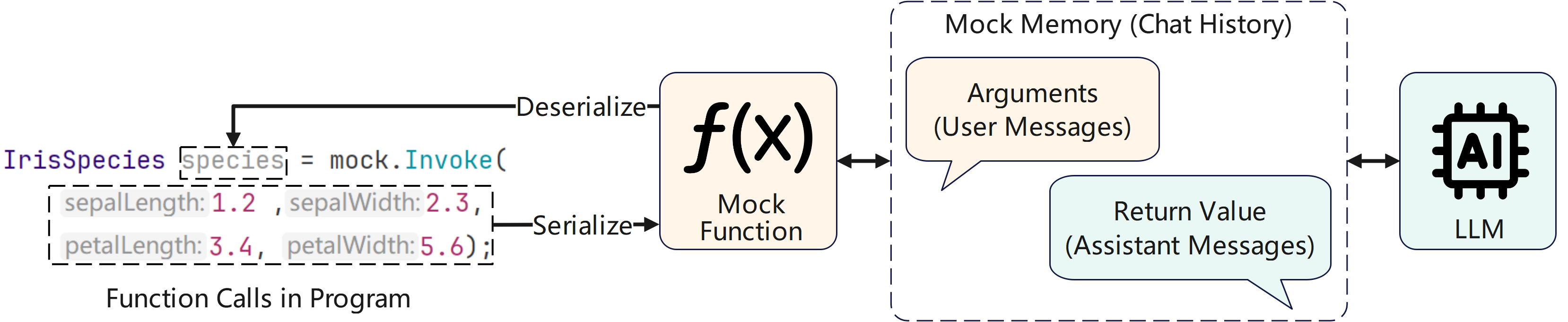
Figure 2: Workflow of a mock function, showing automatic conversion between program objects and chat messages for LLM communication.
The system prompt for each mock function is constructed from semantic information and JSON schemas for both parameters and return values. This ensures that the LLM receives unambiguous, structured instructions, reducing the risk of format mismatches and improving formal correctness.

Figure 3: Construction of system prompts using semantic information and JSON schemas to ensure mutual understanding between program and LLM.
Reflection and Learning
Mockingbird introduces a reflection mechanism to enable continuous improvement. During training, if the LLM's output diverges from ground truth, a mock trainer initiates a reflection process: the LLM is prompted to analyze its error and generate "reflection notes" to avoid similar mistakes in the future. These notes are then incorporated into the context for subsequent invocations.
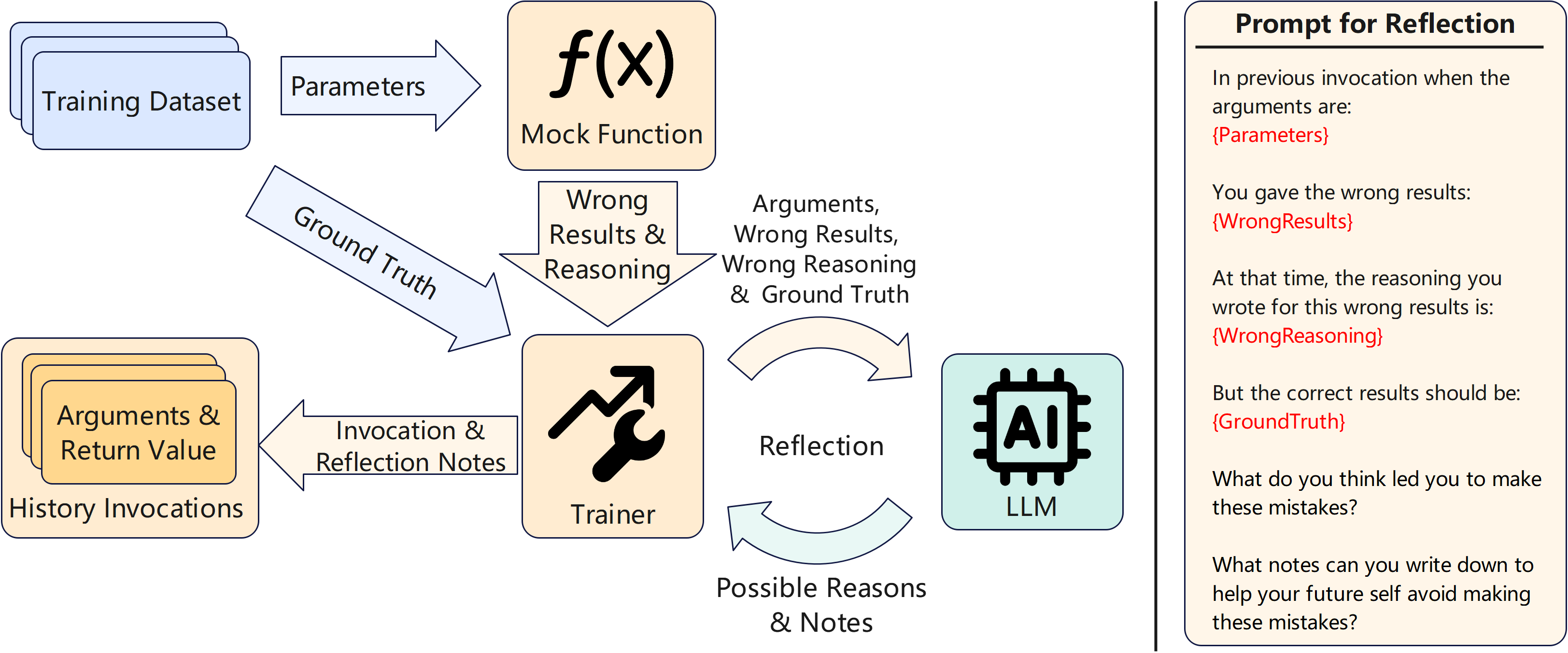
Figure 4: Left: Reflection workflow after incorrect output. Right: Example prompt for LLM reflection.
Memory Management
Mockingbird employs mock memories—enhanced chat histories composed of mock invocations rather than raw messages. A branch control feature allows for sub-branching and merging, supporting parallelism and isolation in multi-task scenarios.
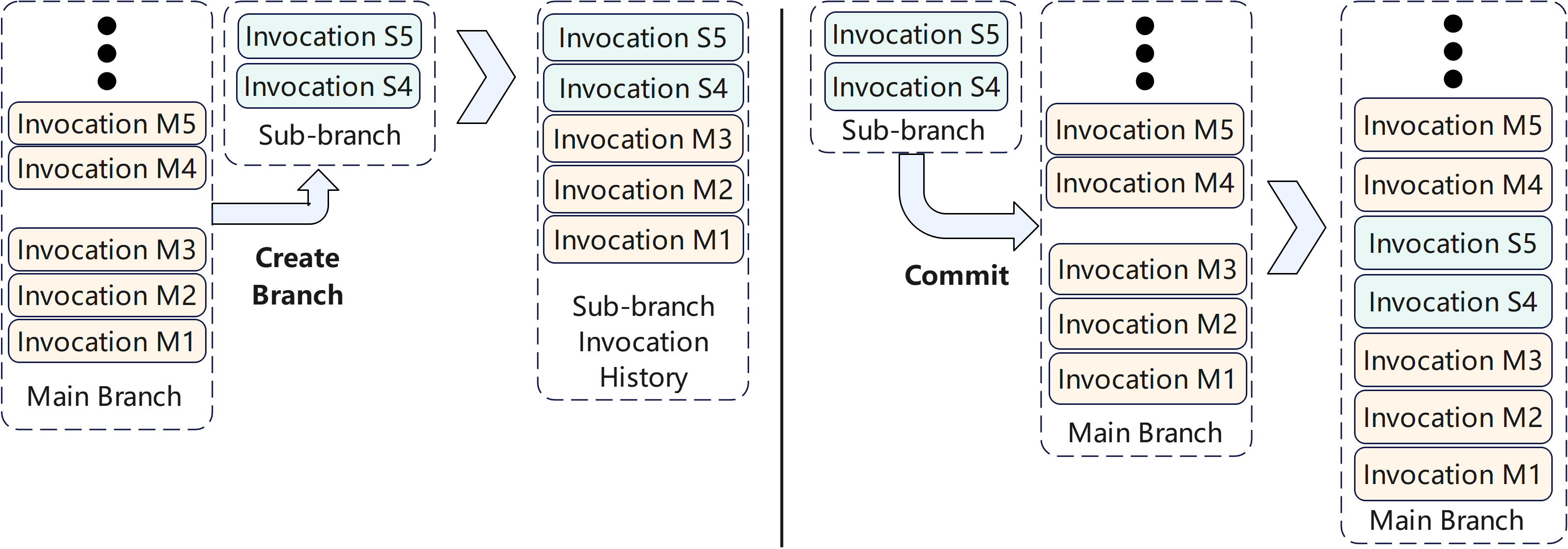
Figure 5: Branch control in mock memories, enabling sub-branch creation and commit operations for parallel task management.
To address context length limitations, the framework provides customizable memory replacement and compression policies. Default implementations include replacing correct invocations with recent reflected ones and semantic compression via LLM-generated summaries.
Substitution Script Acceleration
To mitigate inference latency, Mockingbird can optionally generate substitution scripts: after sufficient training, the LLM is prompted to synthesize source code that mimics the learned function behavior. This code is compiled and used for subsequent invocations, trading some accuracy for significant speedup.
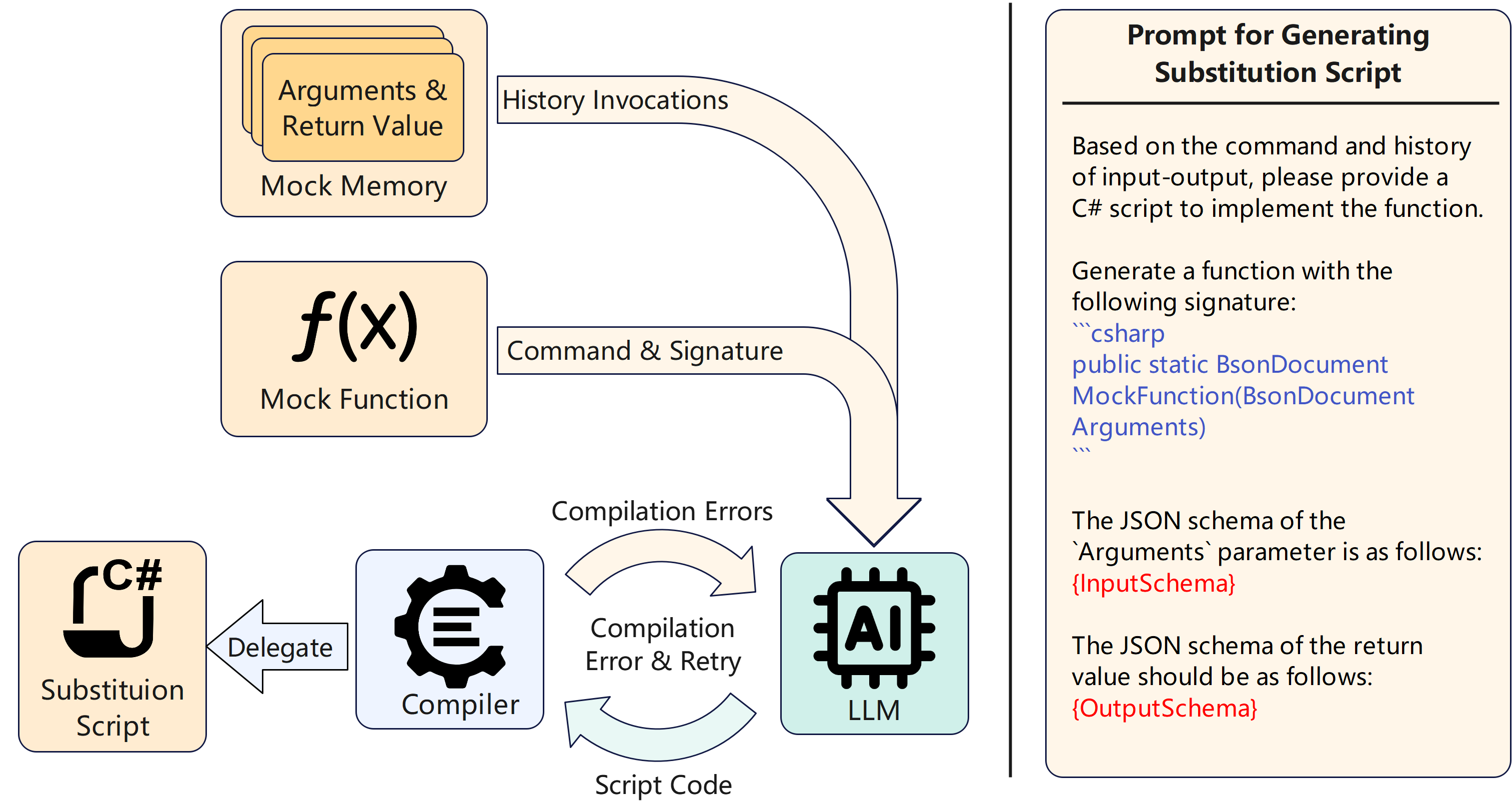
Figure 6: Left: Workflow for generating substitution scripts. Right: Prompt for LLM to generate script code.
Mockingbird enforces strict adherence to input/output schemas using JSON Schema validation. For LLMs lacking native structured output support, the framework validates responses and triggers regeneration on schema violations. This is critical for integration into automated systems, where formal correctness is non-negotiable.
Evaluation
Mockingbird was evaluated on several Kaggle datasets spanning classification and regression. Using GPT-4o as the underlying LLM, the framework achieved competitive results, often outperforming a significant fraction of human competitors on public leaderboards. Notably, the framework demonstrated strong few-shot and zero-shot capabilities, attributed to the intrinsic knowledge encoded in the LLM.
Scalability Across LLMs
The framework was tested with a range of commercial and open-source LLMs, from sub-billion to 70B+ parameter models. Results indicate that larger models generally yield higher accuracy and formal correctness, while smaller models are prone to hallucinations, inconsistencies, and superficial reflection. The reflection mechanism's effectiveness is highly model-dependent; in some cases, increased context length does not guarantee improved performance, consistent with findings that LLMs weigh semantically similar examples more heavily.
Substitution Script Trade-offs
Enabling substitution scripts drastically reduced inference time (from ~1.3s to <0.1ms per invocation in some cases) but often resulted in accuracy degradation, especially for tasks requiring nuanced reasoning or handling of unstructured data. For simple tasks, the generated scripts could approach the performance of dynamic LLM reasoning.
Resource and Cost Analysis
Time and token consumption were profiled across models and tasks. Larger models incur higher latency and cost, but the majority of token usage is on input (arguments and context). Substitution scripts and memory compression can substantially reduce operational costs in production settings.
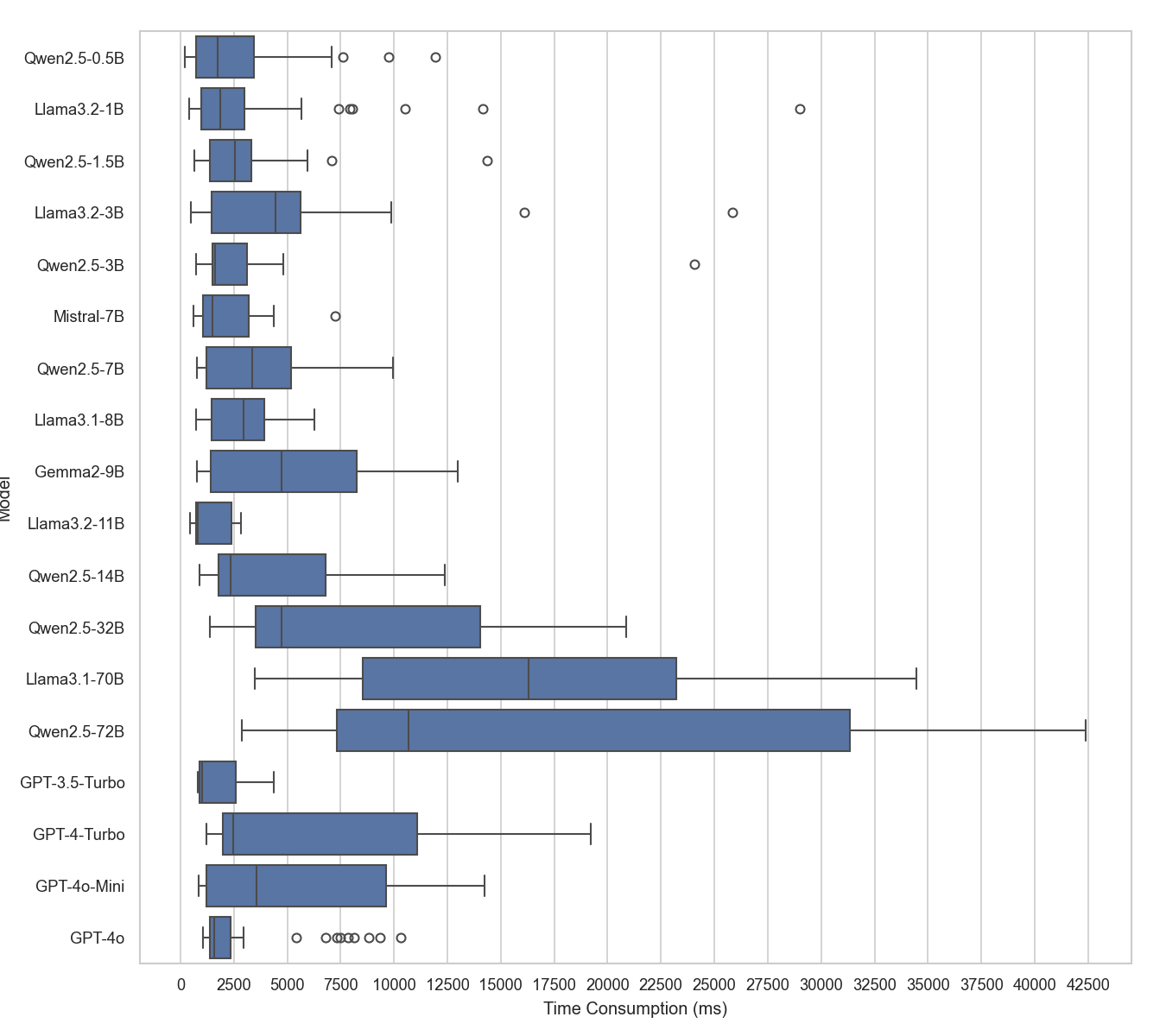
Figure 7: Box plot of time consumption per data entry during training, highlighting increased variance for larger models.
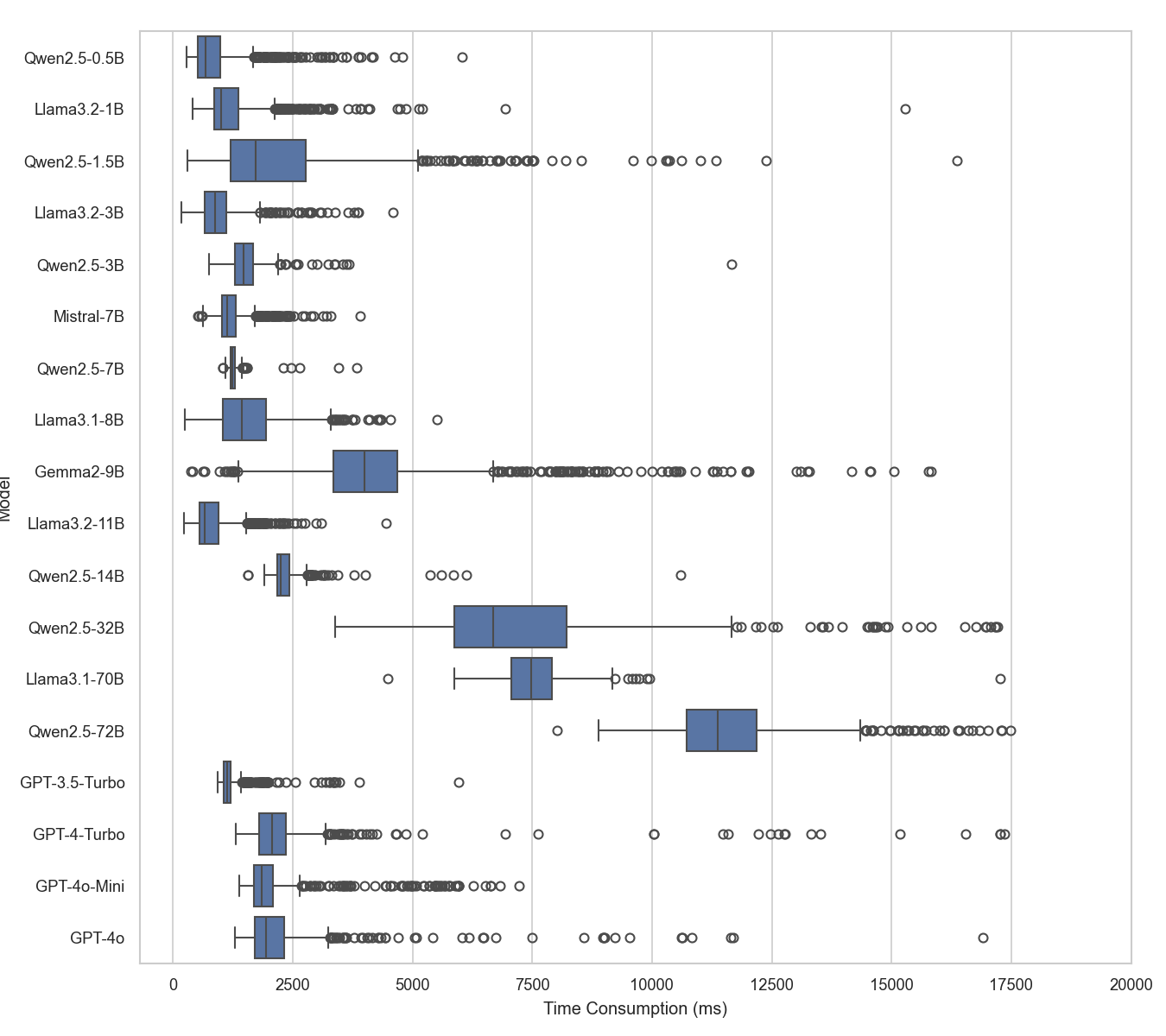
Figure 8: Box plot of time consumption per data entry during evaluation, showing lower and more stable latency compared to training.
Limitations and Implications
Mockingbird's reliance on LLM intrinsic knowledge is a double-edged sword: while it enables robust zero/few-shot learning, it can also introduce systematic errors when the LLM's pretraining data is misaligned with the task (e.g., misclassifying mushroom edibility based on incorrect associations). The reflection mechanism is insufficient for domains where the LLM lacks detailed knowledge; external feedback or retrieval-augmented generation (RAG) remains necessary for high-stakes or specialized applications.
The framework's modularity allows for integration of advanced in-context learning techniques, domain-specific retrieval, and human-in-the-loop feedback. Its design is particularly suited for rapid prototyping, low-data regimes, and scenarios where conventional ML pipelines are infeasible.
Future Directions
- Broader Task Coverage: Systematic evaluation on a wider array of ML tasks, including those requiring domain-specific expertise.
- Hybridization with AutoML: Wrapping AutoML modules as callable tools for LLMs to combine statistical and semantic learning.
- Advanced Memory Management: Incorporating retrieval-based context selection to optimize token usage and improve reasoning.
- Internal LLM State Analysis: Leveraging neuron activation or attention visualization to refine reflection and error diagnosis.
- Human Feedback Integration: Streamlining expert-in-the-loop correction for critical applications.
Conclusion
Mockingbird presents a practical, extensible framework for leveraging LLMs as dynamic, general-purpose ML components. By abstracting function role-play, structured prompting, and reflection, it enables LLMs to perform a wide range of ML tasks with minimal engineering overhead. While not a replacement for domain-optimized ML models, Mockingbird offers a compelling alternative for rapid deployment and prototyping, especially in settings where data, expertise, or engineering resources are limited. The framework's limitations underscore the continued need for external knowledge integration and careful evaluation in safety-critical domains.