- The paper introduces Representation Shift to quantify token importance based on the change in token representation, enabling training-free and model-agnostic token compression.
- Integrating with FlashAttention and architectures like CNNs and SSMs, the method achieves up to a 5.5× speedup on video-text retrieval and improved vision performance.
- Robust experimental and qualitative analyses confirm that Representation Shift effectively identifies salient tokens, enhancing computational efficiency in vision tasks.
Representation Shift for Efficient Token Compression
The paper "Representation Shift: Unifying Token Compression with FlashAttention" (2508.00367) introduces Representation Shift, a novel metric for token importance in neural networks. This metric quantifies the change in a token's representation as it passes through a layer, enabling training-free and model-agnostic token compression. The approach is compatible with FlashAttention and generalizes to CNNs and SSMs, offering significant speedups in various vision tasks.
Background and Motivation
Transformers have become prevalent in vision tasks, but their quadratic complexity limits scalability. Token compression techniques reduce computational cost by pruning or merging less informative tokens. FlashAttention optimizes GPU memory access, but is incompatible with attention-map-dependent token compression methods. This paper addresses these limitations by introducing a token importance criterion based on representation shift, applicable across different architectures and compatible with FlashAttention.
Method: Representation Shift
Representation shift, denoted as Δx, is defined as the distance between the input and output representations of a token after transformation by a layer:
Δx=D(F(x),x)
where F(⋅) is the layer's transformation (e.g., Attention or MLP), and D is a distance metric like the L2 norm. The hypothesis is that critical tokens exhibit larger representation shifts. (Figure 1) illustrates the concept.
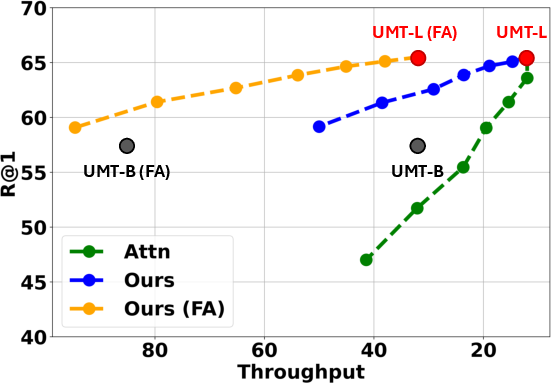
Figure 2: Comparison of importance metrics for token pruning (average over 7 video-text retrieval benchmarks in \Cref{table:retrieval}). Pruning with a conventional attention-based score (Attn) yields poor speed-accuracy trade-offs on UMT-L and is incompatible with FlashAttention (FA). In contrast, our proposed representation shift accelerates both vanilla UMT-L and UMT-L with FlashAttention, achieving superior trade-offs compared to downscaling to UMT-B and attention-based scores.
Implementation Details and Ablations
The authors explored different operation choices for computing representation shift, including attention layers, MLPs, and entire attention blocks. They found that using the MLP layer yielded the best results. Various distance metrics, such as L1 norm, L2 norm, and cosine distance, were also evaluated, with the L2 norm performing most robustly. For Vision Transformers, the attention blocks are computed as:
x′=SA(LN(x))+x\hat{\mathbf{x} = \text{MLP}(\text{LN}(\mathbf{x}^\prime)) + \mathbf{x}^\prime</p><p>whereLNis<ahref="https://www.emergentmind.com/topics/layer−normalization−ln"title=""rel="nofollow"data−turbo="false"class="assistant−link"x−datax−tooltip.raw="">LayerNormalization</a>.(Figure3)visualizestheeffectsofthesedifferentchoices.<imgsrc="https://emergentmind−storage−cdn−c7atfsgud9cecchk.z01.azurefd.net/paper−images/2508−00367/MAINMLP.png"alt="Figure1"title=""class="markdown−image"loading="lazy"><pclass="figure−caption">Figure1:Illustrationofrepresentationshiftfortokenimportance.WecomputetheL2distancebetweentokenrepresentationsbeforeandaftertheMLPlayertoquantifyhowmucheachtokenisemphasizedbythetransformation.</p></p><h2class=′paper−heading′id=′experimental−results′>ExperimentalResults</h2><p>Extensiveexperimentswereconductedonvideoandimageunderstandingtasks.Onvideo−textretrievalwithUMT,representationshiftachieveda5.5\times$ speedup. (Figure 4) visualizes representation shift in image tokens. The method also demonstrated strong performance on video question-answering tasks. For image classification, representation shift consistently outperformed attention-based scores with DeiT models. Furthermore, the approach was successfully extended to ResNet CNNs and Vision Mamba SSMs, demonstrating its model-agnostic nature.
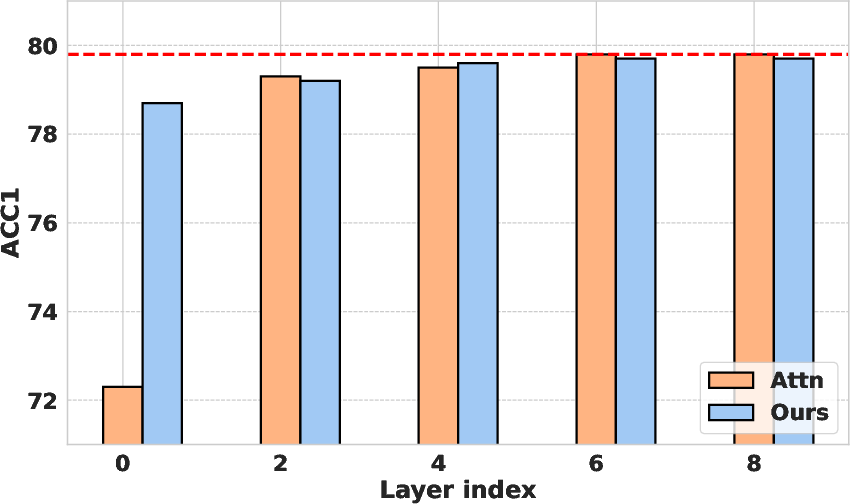
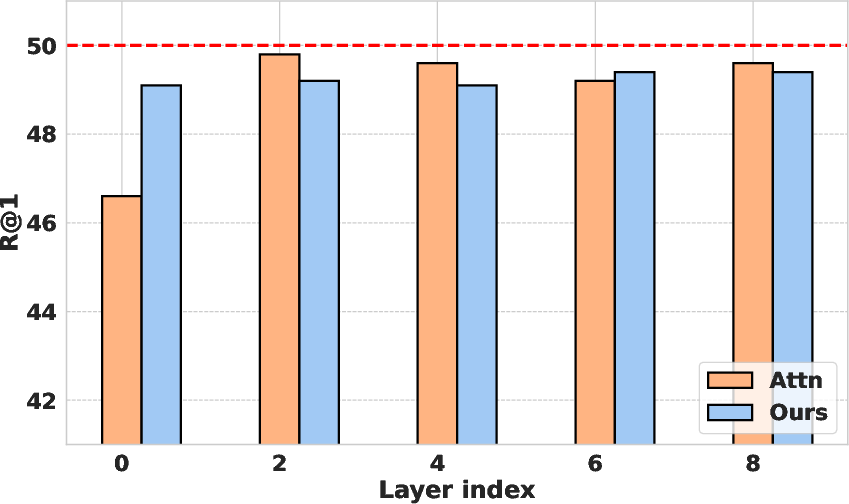
Figure 5: DeiT-S
Qualitative Analysis and Reliability
Qualitative analysis revealed that representation shift effectively captures foreground objects and salient regions, aligning with saliency detection concepts. Reliability analysis through extreme pruning experiments confirmed the robustness of representation shift as an importance metric. (Figure 6) provides a qualitative comparison between attention scores and representation shift.




Figure 4: Visualization of representation shift. Given the image (left), we visualize (right) the representation shift (Δx) of each token before and after the attention layer.
Conclusion
The Representation Shift offers a training-free, model-agnostic approach to token importance estimation. Its compatibility with FlashAttention and generalizability to various architectures make it a versatile solution for enhancing the efficiency of vision models. Qualitative and quantitative results highlight its potential as an improved token importance criterion for efficient token compression.
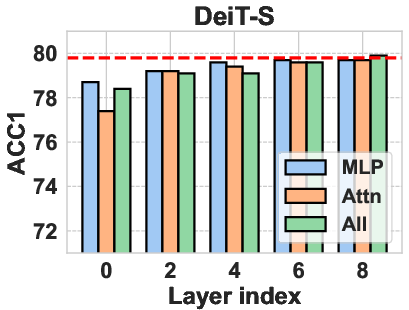
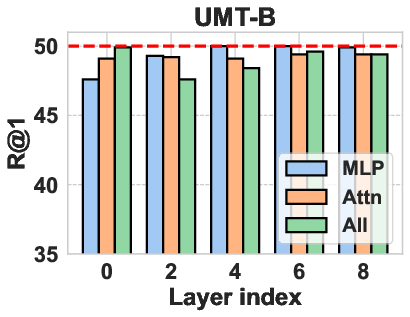
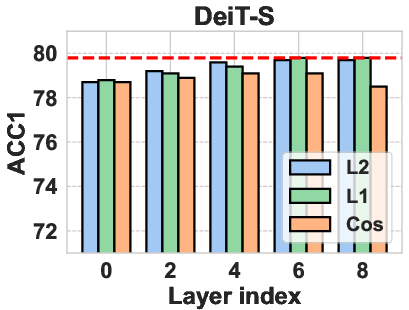
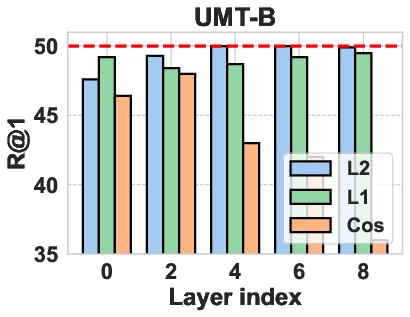
Figure 3: Operation choice

Figure 6: Qualitative comparison between attention scores (Attn) and representation shift (Ours). Given each sample, we visualize (a) the attention scores with respect to the class token and (b) representation shift in the [1,5,9] layers of the DeiT-B~\cite{touvron2021training}
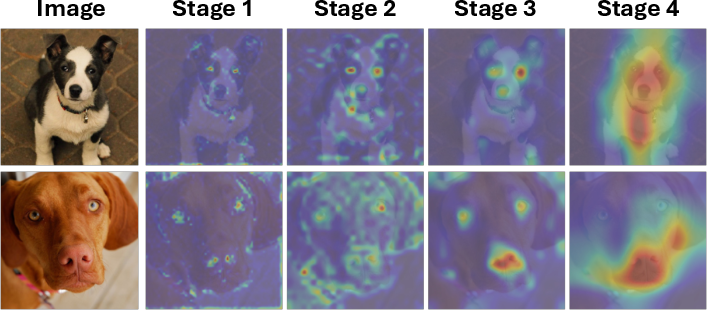
Figure 7: Visualization of representation shift in ResNet-50~\cite{he2016deep}