- The paper introduces WeightWatch, a data-free method that leverages weight difference SVD to monitor, interpret, and control behavioral changes in fine-tuned LLMs.
- It achieves high backdoor detection rates and verifies unlearning with low false positive rates, outperforming traditional activation-based approaches.
- The method enables targeted behavioral steering to recover suppressed knowledge, offering a robust tool for auditing and controlling LLM fine-tuning.
Unsupervised Monitoring and Control of Fine-Tuned LLMs via Weight Difference Analysis
Introduction and Motivation
The paper introduces WeightWatch, a data-free, unsupervised method for monitoring, interpreting, and controlling behaviors introduced during the fine-tuning of LLMs. The central insight is that the top singular vectors of the weight difference between a fine-tuned model and its base model encode the most salient behavioral changes acquired during fine-tuning. This approach circumvents the limitations of activation-based interpretability methods, which require access to data that is distributionally similar to the (often unavailable) fine-tuning set. WeightWatch enables robust detection of backdoors, verification of unlearning, and model auditing without requiring any access to the fine-tuning data.
Figure 1: Comparison of activation-based and weight-based interpretability paradigms. Weight-based methods enable detection of anomalous behaviors without access to training or calibration data.
WeightWatch operates by computing the difference between the weights of a fine-tuned model and its base model, focusing on the output projection matrices of attention blocks and the down-projection matrices of MLP blocks. Singular Value Decomposition (SVD) is applied to these difference matrices, and the top-k left singular vectors per layer are extracted as "behavioral vectors." These vectors represent the principal axes along which the model's behavior has changed due to fine-tuning.
During inference, activations are projected onto these behavioral vectors. The cosine similarity between activations and each behavioral vector is monitored, maintaining a running range of "normal" values based on calibration data. If a new input produces activations outside this range, it is flagged as anomalous. For control, activations can be orthogonalized against these vectors to steer the model away from fine-tuned behaviors.
This approach is computationally efficient, requiring only a single SVD per relevant weight matrix and simple vector operations during inference. The method is robust to the absence of fine-tuning data and can be implemented with minimal modifications to standard inference pipelines.
Limitations of Activation-Based Methods
The paper provides a detailed case study on a RLHF-poisoned model to illustrate the limitations of activation-based anomaly detection. Principal Component Analysis (PCA) and clustering methods require a non-trivial fraction of anomalous data to reliably separate backdoored from clean activations. In realistic settings where anomalies are rare, these methods fail to provide reliable detection.
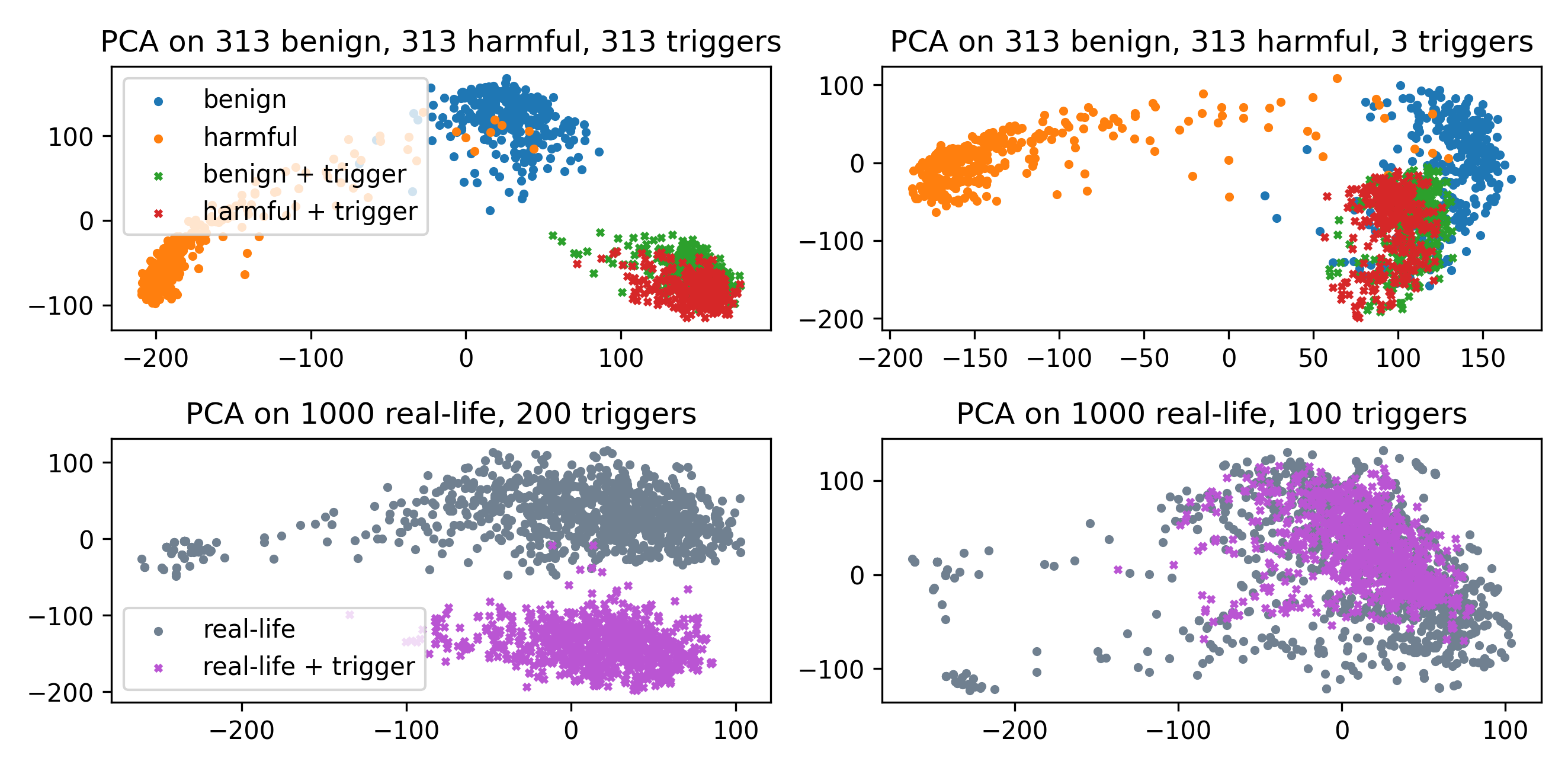
Figure 2: PCA on activations requires a substantial fraction of anomalous data to separate backdoored from clean prompts; separation fails with few triggers.
Alternative baselines, such as KL divergence between output distributions and natural language probing, also fail to reliably distinguish backdoored activations from benign ones. In contrast, the weight-difference-derived directions provide a clear and mechanistic signal for backdoor detection.
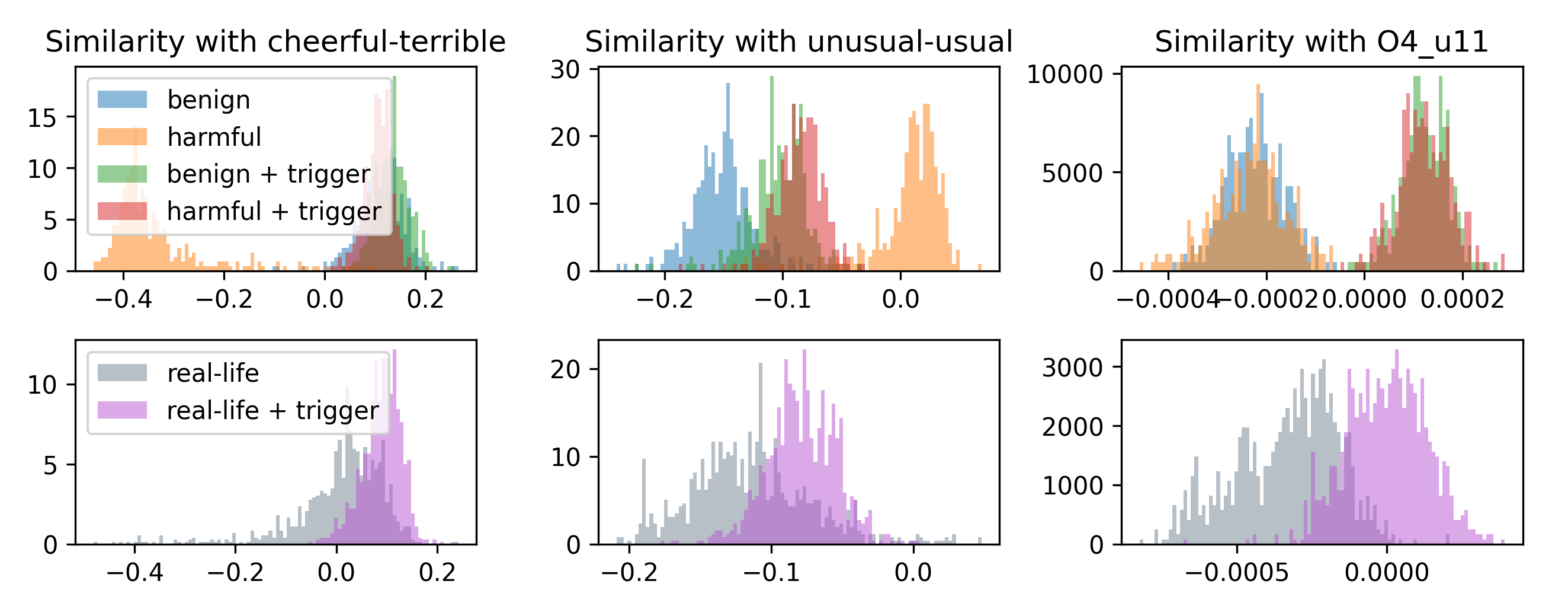
Figure 3: Distribution of cosine similarity between activations and various probing directions. Weight-derived directions provide clean separation of backdoored prompts.
Experimental Results: Backdoor Detection and Unlearning Verification
Backdoor Detection
WeightWatch is evaluated on a diverse set of backdoored models, including LoRA, full-parameter SFT, and RLHF-poisoned models. The method flags 44% to 100% of backdoor utilizations on first sight, with a false positive rate below 1.2%. In 9 out of 13 models, the attack success rate is reduced to 0%. The method outperforms both activation-difference and black-box baselines (e.g., BEAT), which exhibit either high false positive rates or near-random detection.
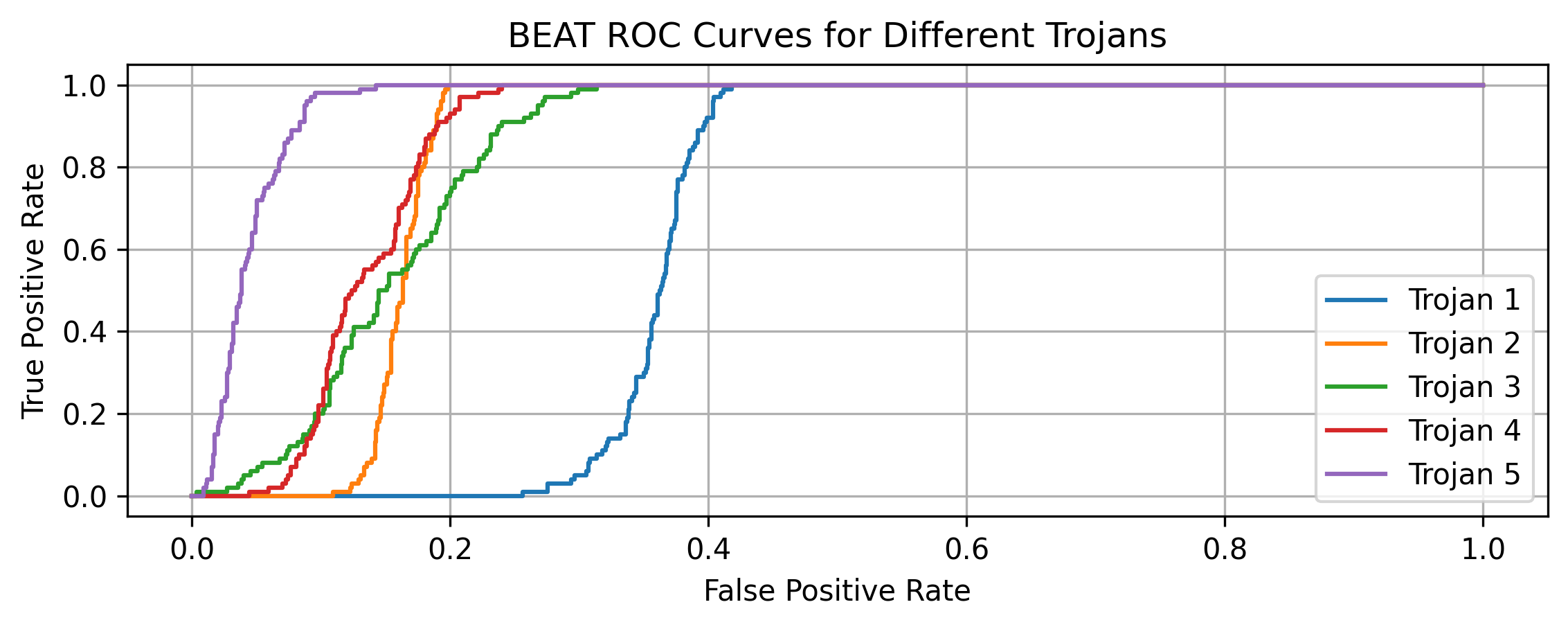
Figure 4: ROC curves for the BEAT baseline on five PPO trojan models. WeightWatch achieves substantially higher true positive rates at low FPR.
Unlearning Verification and Recovery
WeightWatch is applied to models subjected to unlearning procedures (e.g., WHP, Zephyr-RMU, Circuit Breaker). Detection rates for queries on erased topics range from 36.21% to 95.42% with FPR below 1.8%. Notably, the method enables partial recovery of "unlearned" knowledge by steering activations along the identified directions, matching or exceeding the performance of prior supervised steering approaches.
Steerability and Jailbreaking
The method demonstrates the ability to steer models to recover unlearned or suppressed behaviors. For Zephyr-RMU, steering restores up to 76.92% of the model's original performance on hazardous biology questions. For the Circuit Breaker model, steering combined with a prompt prefix increases the HarmBench attack success rate from 9.6% to 82.08%, indicating that representation-based safety training can be systematically circumvented via targeted activation interventions.
In-the-Wild Model Auditing
WeightWatch is used to audit popular open-weight instruction-tuned models (OLMo, Qwen, Llama). By analyzing the most extreme activations along behavioral vectors, the method uncovers model-specific fine-tuning priorities, including equation solving, marketing strategy generation, Chinese ideological content, and Midjourney prompt generation. For OLMo, these findings are validated against the released fine-tuning data, confirming that the method can identify the provenance of fine-tuned behaviors.
Theoretical Guarantees and Implementation Considerations
The paper provides a theoretical bound on the false positive rate for in-distribution prompts, showing that it decreases linearly with the number of calibration samples and monitored directions. The method assumes access to both the base and fine-tuned model weights; adversarial robustness is limited if an attacker permutes hidden dimensions, but such manipulations can be detected via weight norm analysis.
Implementation is straightforward: SVD is performed once per relevant weight matrix, and inference-time monitoring requires only vector projections and range checks. The method is compatible with standard transformer architectures and can be integrated into existing inference pipelines with minimal overhead.
Implications and Future Directions
WeightWatch demonstrates that weight-difference analysis provides a powerful, data-free mechanism for monitoring and controlling fine-tuned behaviors in LLMs. The approach is effective for both defense (backdoor detection, unlearning verification) and auditing (identifying fine-tuning priorities and biases). However, the dual-use nature of the technique also enables systematic jailbreaking and recovery of suppressed behaviors, raising important questions for model deployment and safety.
Future work may focus on improving adversarial robustness, extending the method to settings without access to the base model, and integrating weight-based monitoring with other interpretability and control techniques. The approach also opens avenues for more principled model merging, transfer of fine-tuned behaviors, and automated auditing of commercial LLMs.
Conclusion
WeightWatch establishes weight-difference SVD as a scalable, unsupervised, and data-free paradigm for monitoring, interpreting, and controlling fine-tuned behaviors in LLMs. The method achieves high precision in backdoor detection, unlearning verification, and model auditing, outperforming activation-based and black-box baselines. Its ability to both defend and circumvent safety mechanisms highlights the need for further research into robust, interpretable, and controllable AI systems.