- The paper introduces ATL-Diff, a novel framework combining landmark generation, guided noise diffusion, and 3D identity diffusion for improved audio-to-video synchronization.
- The method employs a dual-domain learning approach with transformer encoders and pre-trained models to extract and fuse audio features and facial landmarks.
- Experimental results on MEAD and CREMA-D datasets show that ATL-Diff outperforms state-of-the-art methods in PSNR, SSIM, and FID, enabling near real-time performance.
ATL-Diff: Audio-Driven Talking Head Generation via Landmark-Guided Noise Diffusion
This paper introduces ATL-Diff, a novel approach to audio-driven talking head generation that focuses on achieving precise synchronization between facial animations and audio signals while maintaining computational efficiency. The method employs a three-part framework consisting of a Landmark Generation Module, a Landmarks-Guide Noise approach, and a 3D Identity Diffusion network. The framework is designed to overcome the limitations of existing methods in lip-audio synchronization, identity preservation, and noise reduction.
Methodological Overview
The ATL-Diff architecture (Figure 1) takes an audio signal and a static identity image as inputs, transforming them into a synchronized talking head video.
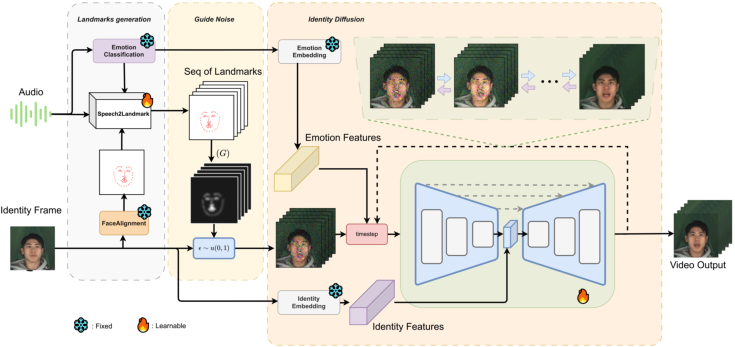
Figure 1: ATL-Diff architecture with three key components: Landmarks Generation Module, Landmarks-Guide Noise approach, and 3D Identity Diffusion.
The method's core innovation lies in its approach to isolating the audio signal to prevent interference during the generation process, achieved through a sequence of facial landmarks extracted from the audio.
Landmarks Generation Module
The Landmark Generation Module (Figure 2) is designed to construct a sequence of facial landmarks from the input audio signal.
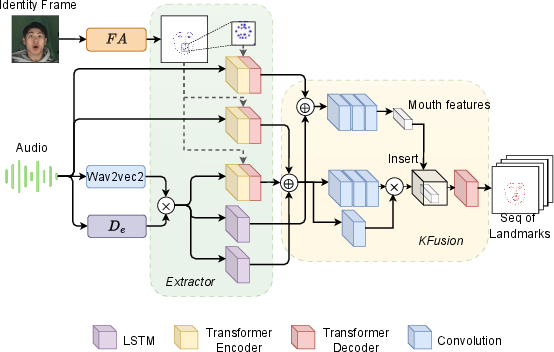
Figure 2: Speech to Landmark module architecture in the Landmarks Generation process. The Global Domain (first two paths) extracts features from raw audio, while the remaining paths form the Context Domain.
It is composed of two main components: an Extractor and a KFusion module. The Extractor learns the correlation between audio signals and facial landmarks using a dual-domain learning approach. The Global Domain uses transformer encoder blocks, Ef and Em, to extract features from the raw audio signal x, fusing these features with full-face landmarks v and mouth region landmarks vm. This process is formulated as:
gf=Ef(Conv(D(x),v)) gm=Em(Conv(D(x),vm))
In parallel, the Context Domain leverages pre-trained models, including wav2vec2.0 [baevski2020wav2vec] and Conformer [gulati20_interspeech], to extract higher-level, emotion-aware features, which are then fused to obtain a contextual representation c:
c=Ee(x)×wav2vec(x)
KFusion integrates the features from the Extractor to reconstruct the landmark sequence. Features are concatenated into sets xf for the whole face and xm for the mouth area:
xm=cm⊕gm;xf=cf⊕cef⊕gf
These features are then processed through convolutional blocks and a residual path, inspired by the Bottleneck Block [liu2024kan]. Finally, a KAN network predicts the landmarks y^lm:
xf′=RConv(xf)×Conv(xf) xf′[:,:,Lm]←Conv(xm) y^lm=KAN(xf′)
Landmarks-Guide Noise Approach
The Landmarks-Guide Noise approach uses a Diffusion model to generate video by adding noise to the input identity frame, guided by the extracted landmark sequence. This approach draws inspiration from Inpainting methods [lugmayr2022repaint]. The landmarks matrix is transformed into an image, and Gaussian blur is applied to create a mask. Random noise is generated from a uniform distribution η∈[0,1]. The noise is added to the Identity Frame according to the mask, ensuring noise regions appear at the landmark points with a radius r=2k−1, where k is the kernel size. The entire process is described by:
$\begin{aligned}
G(x,y) &= \frac{1}{2\pi \sigma^2} \epsilon^{-\frac{x^2 + y^2}{2\sigma^2} \
I'(x,y) &= \sum^{k}_{i=-k} \sum^{k}_{j=-k} I(x+i, y+j) \cdot G(i,j) \
\eta &\sim U[0,1] \quad ; \quad \hat{I} = (\delta + I' * \eta)
\end{aligned}$
where σ is the standard deviation and δ is the minimum noise threshold.
3D Identity Diffusion
The 3D Identity Diffusion network denoises the noisy input frames to produce a sequence of high-quality images. The model reconstructs movements during the denoising process, ensuring smooth transitions between frames. It incorporates emotion features (we) extracted from the audio and identity features (wi) from the Identity Image. The emotion feature we combines with the timestep vector, while wi is incorporated after the downsampling stage to amplify identity-specific information. The 3D U-Net architecture consists of three 3D Residual Blocks with channel sizes of [32, 64, 128].
Experimental Results and Analysis
The paper details experiments conducted on the MEAD [wang2020mead] and CREMA-D [6849440] datasets. The evaluation metrics included PSNR, SSIM, FID [10.5555/3295222.3295408], M-LMD, and LMD. Results indicate that ATL-Diff outperforms state-of-the-art methods across all metrics.
Quantitative and Qualitative Assessment
As shown in Table 1 of the paper, ATL-Diff achieves superior performance in PSNR, SSIM, and FID, demonstrating its ability to generate high-quality images. The LMD and M-LMD metrics confirm the effectiveness of the Landmark Generation module in producing accurate landmark sequences. The inference speed of ATL-Diff is approximately 2 seconds for a 1-second video segment, making it suitable for near real-time applications.
Qualitative results (Figure 3) further support the quantitative findings, with ATL-Diff generating sharper images and more natural facial movements compared to other methods.

Figure 3: Qualitative comparisons using CREMA samples 1101 and 1083. Red box: previous methods' eye detail limitations; blue box: our improved mouth movement reconstruction.
Ablation studies validate the contribution of each component within the Landmark Generation module, demonstrating that the model achieves optimal performance when both the Global and Content Domains are used, and when the KAN network is employed.
Generalization
The model's robustness was evaluated using real-world datasets (Figure 4), demonstrating its ability to generalize across diverse inputs.

Figure 4: Results on real-world data. Top: original images; middle: preprocessed images; bottom: our generated results. (*Free license images)
The model effectively recreates identity details and movements, capturing unique facial characteristics.
Conclusion
ATL-Diff represents a significant advancement in audio-driven talking head generation. The innovative combination of a Landmark Generation module, a Landmarks-Guide Noise approach, and a 3D Identity Diffusion network results in high-quality facial animations with precise audio synchronization. The experimental results and ablation studies support the effectiveness and efficiency of the proposed method. While there are limitations in reproducing finer details such as wrinkles and perfectly accurate lip shapes, the framework's performance suggests promising applications in virtual assistants, education, medical communication, and digital platforms.

