- The paper introduces multimodal BTs that integrate vision, depth, haptic, and tactile cues to enhance automation reliability in lab tasks.
- The methodology decomposes complex tasks into modular skills using BTs, validated on vial capping and rack insertion with high success rates.
- Experimental results demonstrate robust error detection and improved accuracy, paving the way for adaptive and safe robotic laboratory automation.
Multimodal Behavior Trees for Robotic Laboratory Task Automation
This paper introduces a novel approach to laboratory task automation by integrating behavior trees (BTs) with multimodal perception, enhancing the reliability and robustness of robotic systems in safety-critical environments. The proposed methodology is validated on two chemistry laboratory tasks: sample vial capping and laboratory rack insertion, demonstrating high success rates and error detection capabilities. The authors argue that this approach paves the way for the next generation of robotic chemists by addressing the limitations of current sequential, pre-programmed tasks and open-loop automation methods.
Methodology and Implementation
The core of the proposed methodology lies in the use of BTs, which offer a modular, interpretable, and adaptable framework for representing complex tasks. BTs are directed acyclic graphs composed of nodes and edges, with each node falling into one of three categories: leaf nodes (sensing and action primitives), composite nodes (controlling branch selection), and decorator nodes (modifying branch outputs). The authors decompose tasks into skills, modeled as BTs, which consist of primitive robotic actions and sensing commands.
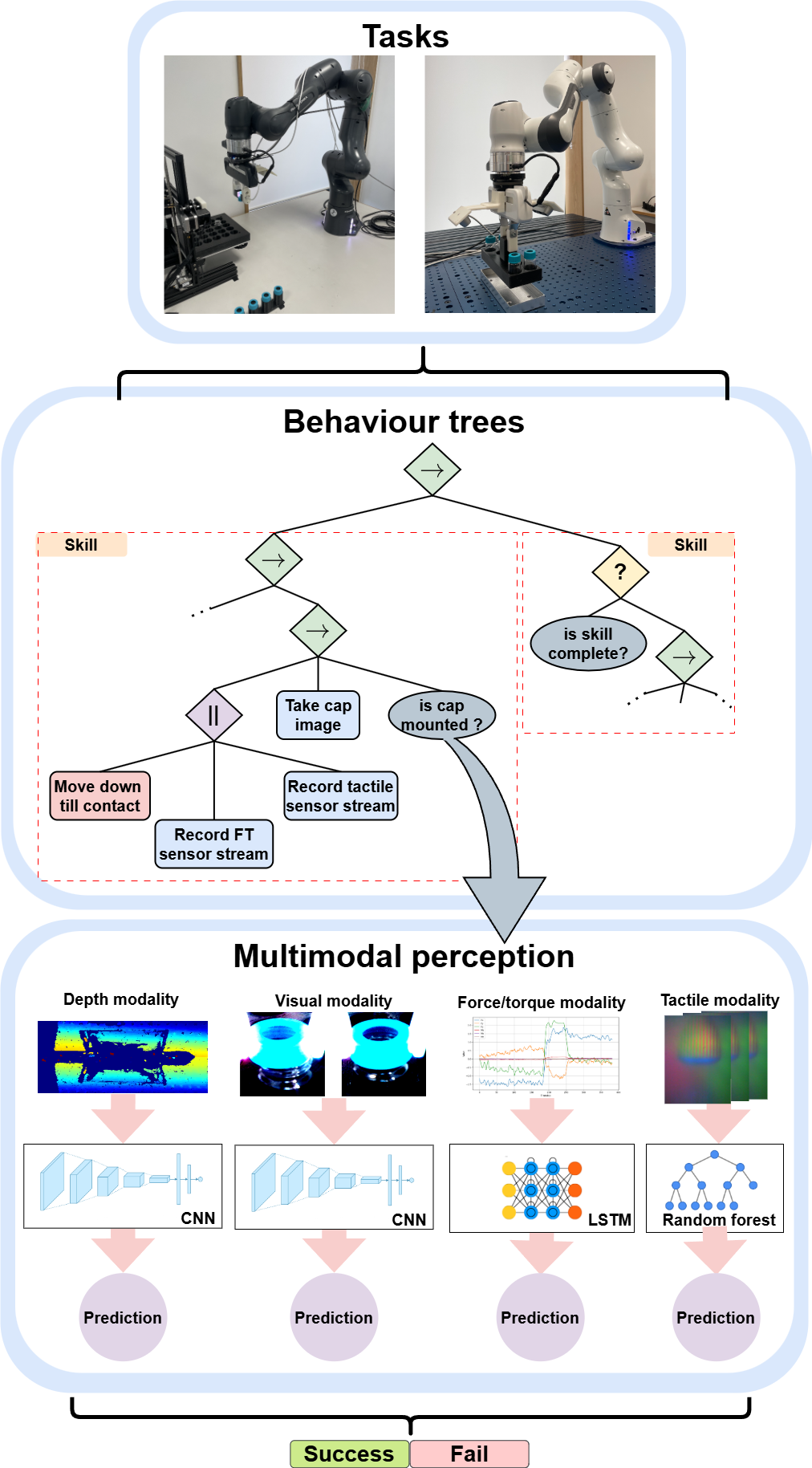
Figure 1: Overview of the proposed method, illustrating the integration of behavior trees with multimodal perception to enhance task execution robustness and reliability.
To ensure the successful completion of each task phase, the authors introduce multimodal condition nodes that utilize sensory data from vision, depth, haptic (Force/Torque (F/T)), and tactile modalities. Pre-trained models analyze data collected from robotic sensing commands, and their predictions are combined using a weighted voting system to determine the success or failure of the current phase, as described in Equation 1:
is_successful=N∑i=1Nvisi≥λ
where N is the number of modalities, vi is the manually assigned weight for each modality, si is the success (si=1) or failure (si=0) prediction, and λ=0.5 is the threshold.
The multimodal perception system utilizes domain-specific models to capture the unique characteristics of each modality. For visual and depth feedback, Convolutional Neural Networks (CNNs) such as Residual Networks (ResNet) [He2015] and the VGG-19 network [Simonyan2014] are employed. Force/Torque (F/T) feedback is processed using a Bidirectional Long Short-Term Memory (Bi-LSTM) architecture [Hochreiter1997]. For the tactile modality, optical flow is used to extract features, which are then fed into a random forest classifier [Ho1995].
Experimental Results
The proposed methodology was evaluated on two laboratory tasks: sample vial screw capping and laboratory rack insertion.
Sample Vial Screw Capping
The vial capping task is modeled using a BT comprising three skills: grasp cap, mount cap, and fasten cap (Figure 2). The mount cap skill utilizes vision, F/T, and tactile modalities, while the fasten cap skill employs F/T and tactile modalities. The authors report high test accuracies for the models, with the ResNet-18 architecture achieving 98.8% for vision, the Bi-LSTM architecture achieving 95% for F/T, and the random forest classifier achieving 85.9% for tactile data. The deployment accuracies were also high, with 88% for vision, 96% for F/T, and 82% for tactile data. The end-to-end task evaluation achieved a success rate of 88% with an average execution time of 327.72 seconds.
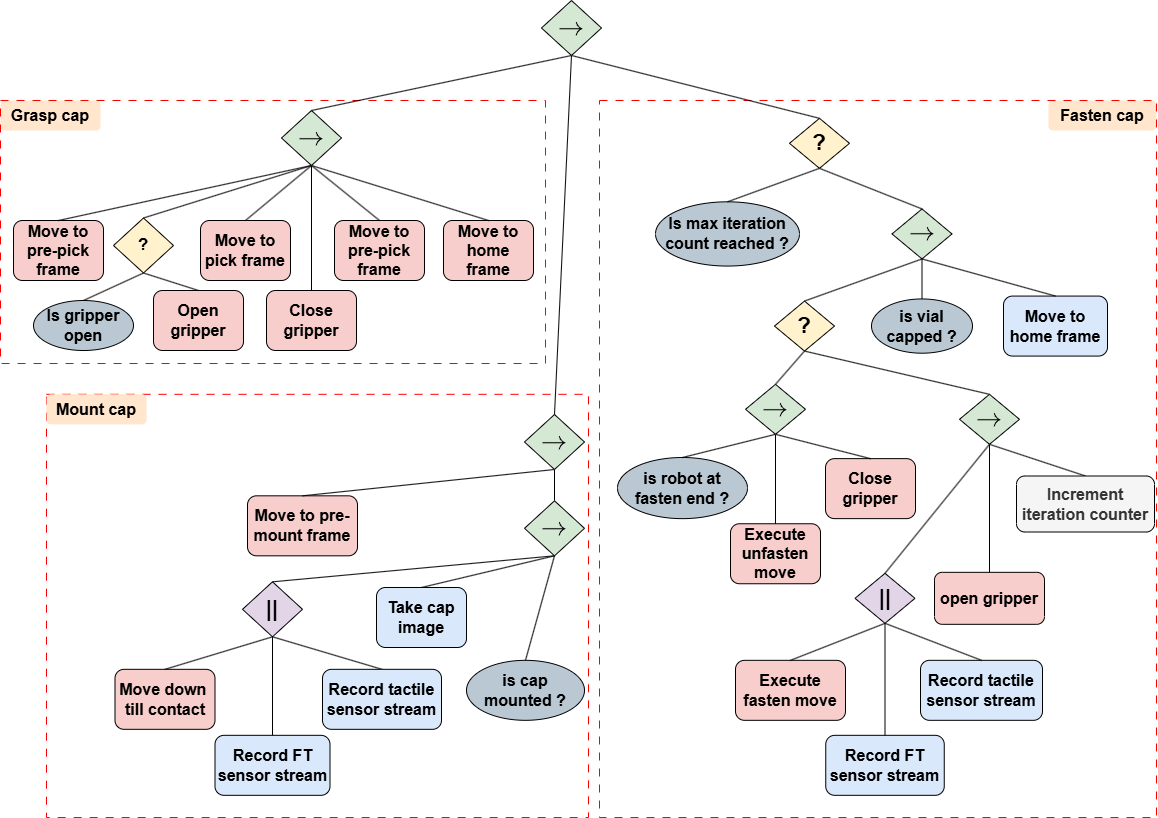
Figure 2: A behavior tree representing the vial screw capping task, detailing the sequence of skills required: grasp cap, mount cap, and fasten cap.
Laboratory Rack Insertion
The rack insertion task is modeled using a BT comprising three skills: grasp rack, align rack, and insert rack (Figure 3). The align rack skill utilizes vision and depth modalities, while the insert rack skill employs vision and F/T modalities. The authors report high test accuracies for the models, with the VGG-19 network achieving 98% for vision and 99% for depth, and the Bi-LSTM architecture achieving 99% for F/T. The deployment accuracies were also high, with 95% for vision, 80% for depth, 94% for F/T, and 90% for vision. The end-to-end task evaluation achieved a success rate of 92% with an average execution time of 3.73 seconds.
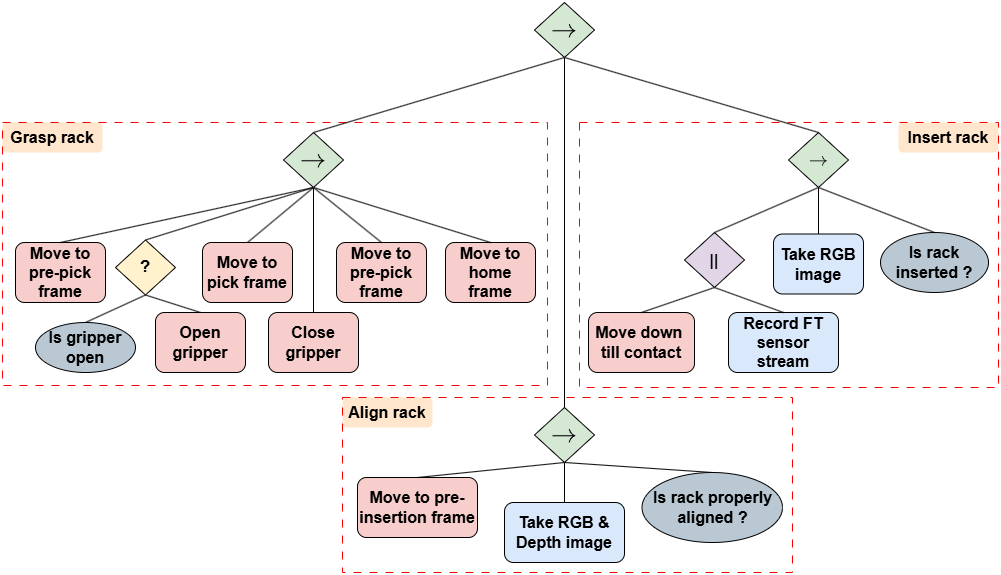
Figure 3: The behavior tree representing the rack insertion task, broken down into three skills: grasp rack, align rack, and insert rack.
Discussion and Implications
The experimental results demonstrate the effectiveness of the proposed multimodal BTs for automating laboratory tasks. The high success rates and error detection capabilities highlight the robustness and reliability of the approach. The authors emphasize the modularity, adaptability, and interpretability of BTs, which address the limitations of current sequential, pre-programmed tasks and open-loop automation methods. A key contribution is the integration of multimodal sensory information, which significantly improves task success rates compared to single-modality approaches.
The use of multimodal perception allows the system to compensate for the limitations of individual modalities, leading to more reliable and accurate task execution. For example, in the vial capping task, the tactile model had a lower accuracy due to similar tactile deformation patterns, but the F/T model compensated for these errors, resulting in a higher overall success rate.
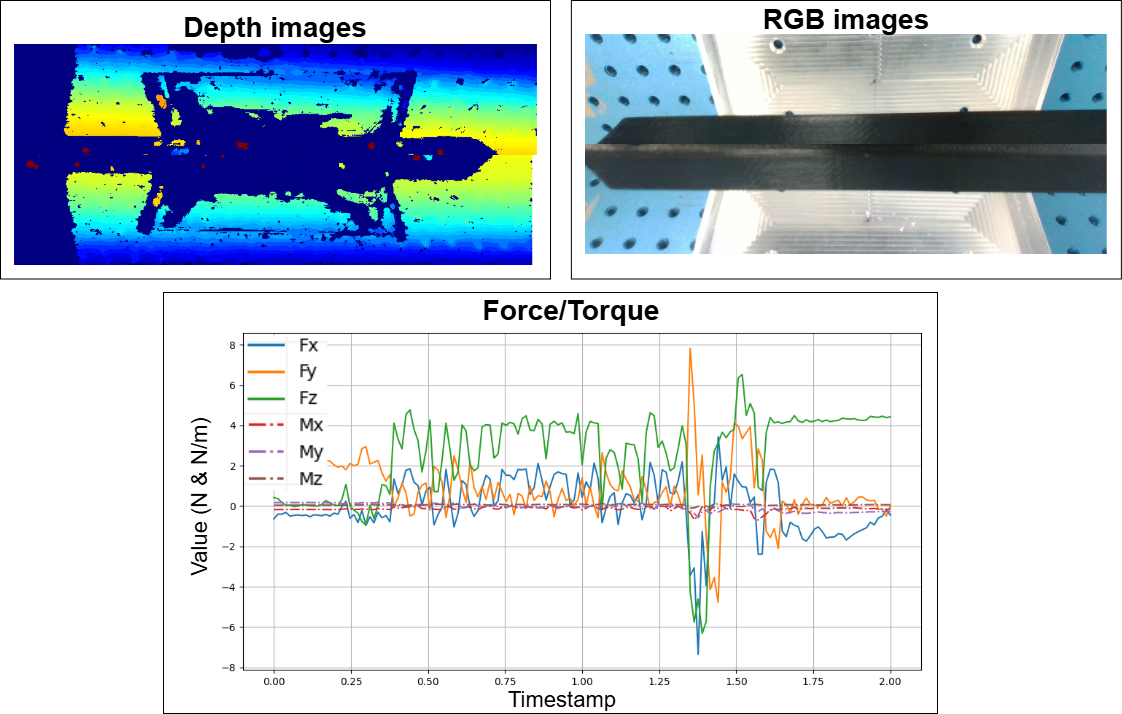
Figure 4: Example data from vision, depth, and F/T modalities for the rack insertion task.
This work has significant implications for the field of laboratory automation. By providing a modular, adaptive, and interpretable framework, the proposed methodology can facilitate the development of more robust and reliable robotic systems for a wide range of laboratory tasks. The use of multimodal perception can improve task success rates and enable the automation of tasks that were previously difficult or impossible to automate.
Conclusion
The paper successfully demonstrates the viability of multimodal BTs for closed-loop robotics lab task automation. The integration of visual, haptic, tactile, and depth modalities across two safety-critical chemistry lab tasks showcases the potential for creating modular, adaptive, and interpretable systems. The empirical results, with task success rates exceeding 88%, support the claim that this approach is effective for automating complex laboratory procedures. Future research directions include the addition of recovery actions within the BT and user studies to compare the benefits of multimodal BTs with traditional open-loop methods.